汇编程序设计与计算机体系结构软件工程师教程笔记:内联汇编与宏
《汇编程序设计与计算机体系结构: 软件工程师教程》这本书是由Brain R.Hall和Kevin J.Slonka著,由爱飞翔译。中文版是2019年出版的。个人感觉这本书真不错,书中介绍了三种汇编器GAS、NASM、MASM异同,全部示例代码都放在了GitHub上,包括x86和x86_64,并且给出了较多的网络参考资料链接。这里只摘记了MASM和NASM,测试代码仅支持Windows和Linux的x86_64。
9. 内联汇编与宏
9.2 内联汇编:是一种在高级语言中嵌入汇编代码的办法。还有一种办法也能把汇编语言的代码同高级语言的代码结合起来,就是用汇编代码来撰写函数,并将其放在一份文件中,然后在C++代码中调用这些函数。不过,这种办法需要执行相关的准备工作,而且还涉及函数调用,因此会引发一些开销。与之相比,撰写内联式的汇编代码在某些情况下可能更为简单。
各种编译器会采用不同的做法来处理内联式的汇编代码。如果高级语言的代码所内嵌的汇编代码在编译过程中没有受到修改或优化,那么GCC实际上就相当于把这一部分汇编代码复制到它所输出的汇编文件中(这种文件的后缀名是.s),进而把这些代码与从高级语言转换而来的那些汇编代码一起交给GNU汇编器(GNU Assembler, 也就是GAS)处理。Microsoft的Visual Studio采用Visual C++内置的汇编器处理内联汇编语句,而不会专门采用MASM那样单独的汇编器来做。Microsoft的x64 C/C++编译器不支持内联式的汇编代码,它改用编译器内部函数来完成相应的底层指令。
C++编译器通常用asm或__asm关键字表示内联式的汇编语句。内联汇编代码范例如下表所示:
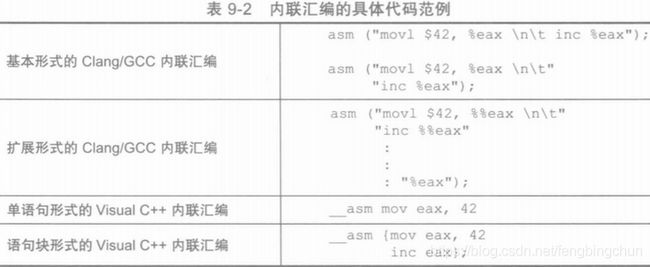
Clang/GCC汇编器要求asm关键字后面必须写一对圆括号及一个分号,而汇编代码则要以字符串的形式写在一对双引号中,并放置在这对圆括号中。换行符与制表符用来分割字符串中的各条汇编语句。Visual C++要求__asm关键字的后面要么直接写汇编语句,要么跟上一对花括号。如果汇编语句只有一条可以直接写出来,若有很多条则需放在花括号中。最后的分号可有可无。
开发者在使用Clang/GCC时可能会开启-ansi或-std这样的编译选项,从而导致asm及inline等关键字遭到禁用,这种情况下,可以把asm关键字写成__asm__。
Clang与GCC是有基本形式与扩展形式之分的。尽量不要使用基本形式的asm内联,因为在访问全局变量时可能要做不同的处理,而且,这种形式还会假设汇编代码不修改通用的寄存器。然而基本形式的asm内联也有一些好处,由于它不一定非要写在C/C++函数中,因此可以用来执行汇编器指令并撰写全局的汇编函数。此外,如果C/C++函数声明成了naked函数,编译器就不会为其生成开场及收场代码(prologue and epilogue code),这就要求开发者必须使用基本形式的asm内联来为这样的函数撰写定制的开场及收场代码。扩展形式的asm内联可以更精细地控制与汇编代码有关的输出与输入,并指明代码所用到的寄存器。Clang/GCC要求扩展形式的asm代码必须写在C/C++函数中,Visual C++则要求所有的内联汇编代码都必须这样写。
GCC并不会解析内联式的汇编指令,因此它根本就不知道这些语句是否有效,而且GDB等调试器也不会单步地进入内联汇编语句中去调试,而是把整个asm视为一个步骤。如果要单步调试,可以在想插入断点的地方手工添加”int $3”指令。Visual Studio无须使用INT即可单步调试x86内联汇编指令。
内联汇编中的注释既可以按汇编代码自身的格式来写也可以按C++的格式来写,建议采用后一种写法。
Visual C++可以直接访问C语言式的变量。Clang/GCC访问变量的方式比较复杂,对内联的汇编代码来说,用于输出和用于输入的变量都必须在模板中的相应列表中说明。当然,列表也可以留空,如果其中有内容,那么与clobbers列表合计起来不得超过30项。
在Clang/GCC的内联式汇编代码中对涉及输出与输入的变量做出说明:
[asmSymbolicName] “constraint” (CvariableName)
其中,asmSymbolicName可以是任何一个有效的标识符名称,它也可以与外围代码中已经定义的C语言标识符同名,从而使内联式的汇编代码能够用同样的名称来引用这个变量。constraint(约束或限定)这一部分用来指定与操作数的用法及放置地点有关的信息。它可以是一个或一系列字面。如果某个操作数是用来输出数值的,那么它必须先以修饰符开头,然后才能写上一个或多个字母。最常用的两个修饰符是”=”与”+”,前者表示该操作数在执行汇编指令之前的初始值并不重要,仅仅是供汇编代码写入数据的,后者表示汇编代码既要读取该操作数的初始值,又要向其中写入数据(也就是说这个参数既用于输入又用于输出)。有的时候,系统会先把那些仅仅用于输入的参数处理完,然后再处理那些供汇编代码输出数据的参数,这就促使它有可能会复用某些寄存器,令其在不同的阶段表示不同的参数。这样一来,如果其中有某个输出参数在处理输入参数的过程中已经写进了值,那么这个值就会把用同一个寄存器所表示的输入参数所具备的初始值给覆盖掉。为了避免这种覆写的情况,可以在”=”或”+”后面写上”&”符号,使得系统能够正确地实现这样的参数。
在Clang/GCC的内联汇编模板中,还有一个部分叫做clobbers列表,列表中需要写上内联的汇编代码所修改的寄存器,以防止系统误以为这些寄存器的值不会为汇编代码所修改,从而执行一些相关的优化措施。系统可能会生成指令来保存它们的值,以便在执行完内联的asm语句后能够予以恢复。系统在选用寄存器来实现汇编代码中用于输入及输出的操作数时会避开clobbers列表中指明的项目。如果你所写的内联式汇编代码确实会顺带影响到某个寄存器的值,但你却没有将其写在clobbers列表中,那么程序可能会出错或发生意外的结果。
下表列出了内联式汇编代码中经常用到的x86约束修饰符:

根据AT&T汇编语法,寄存器以一个%符号开头。不过,内联式的汇编代码中寄存器需要用两个%符号开头,也就是要在前面加上%%,若只加一个%,表示的则是这段内联代码所用的参数(或变量)。之所以要这样写,是因为内联代码会把%当作转义符使用,以便输出它后面的符号所表示的字符,因此,”%%”输出的是单个%字符,而”%=”则会针对代码库中的每一段asm代码输出一个独特的数字(这个数字可以用来创建标签,以供其它代码引用)。此外,”%{”、”%|”及”%}”这三种写法分别用来输出{、|及}字符。这三种字符必须用%来转义,假如直接写在内联的汇编代码中,那么系统就会将其当成特殊字符并解读成用来表示各种汇编方言的结构。如果要产生%eax这样的汇编代码,那么在内联的汇编语句中应该写成%%eax,不过,在clobbers列表中提到eax时,只写一个%就好。
Clang与GCC默认使用AT&T语法规则,而Visual C++则使用Intel语法规则。不过,Clang与GCC能够在内联的汇编代码中使用多种汇编方言。由AT&T语法切换到Intel语法能够使代码变得好懂一些。要想采用某种特定的语法来撰写内联汇编代码,一种简单的办法是在第一条命令中写上.att_syntax以表示这段代码用的是AT&T语法,或者写上.intel_syntax以表示这段代码用的是Intel语法。Clang与GCC可以通过-masm这个编译选项来指定内联汇编代码所采用的方言。-masm=att与-masm=intel分别表示AT&T语法及Intel语法。
9.3 宏(macro):它可以视为一个模块或一系列指令,并根据名称来加以调用。汇编代码中的宏的运作方式与C++代码中的内联函数类似,都是用其中所包含的一系列语句或指令来替换位于调用点的宏名或函数名。每调用一次宏就要发生一次代码替换或代码展开。
对比宏与函数:函数适合实现那种比较长而且需要频繁执行的代码。无论函数调用多少次,都只需要在程序中保留一份代码。每次调用函数时,系统会把控制权转移给内存中的这个函数。调用函数涉及传递参数、建栈以及清理栈等工作,从而会产生一定的开销。为了提高效率,这些比较长且比较复杂的函数代码只在程序中保留一份就可以了。宏适合实现那种比较短而且需要频繁执行的代码。对程序做汇编的时候,汇编器每看到一个宏就会把该宏所代表的那一系列指令展开到这里,于是同样一段代码就有可能多次出现在程序中,这样做的好处是省去了调用函数所需的开销。宏与函数有一个共同点,就是都可以接受参数(argument或parameter),不过函数的参数是在运行程序的时候才传递过去的,而宏的参数则是在做汇编的时候就已经替换好了。
定义并调用宏:NASM采用[%#]的格式来指代参数,其中的#部分是从1开始的编号;MASM直接按照参数的名称来引用。宏可以写在程序段以外,也可以写在其中,无论采用哪种写法都应该在整个程序的范围内保持一致。还有一种管理宏的办法,是把所有的宏或者相关的一组宏单独放在一份文件中,然后通过INCLUDE汇编命令将其包含进来。MASM的宏还具备一项特性,就是可以在参数后面写上:REQ,以要求调用方必须指定这个参数而不能将其忽略。
以下是测试内联汇编和宏的测试代码段,这些code主要来源本书的示例代码:
MASM的内联汇编代码段如下:
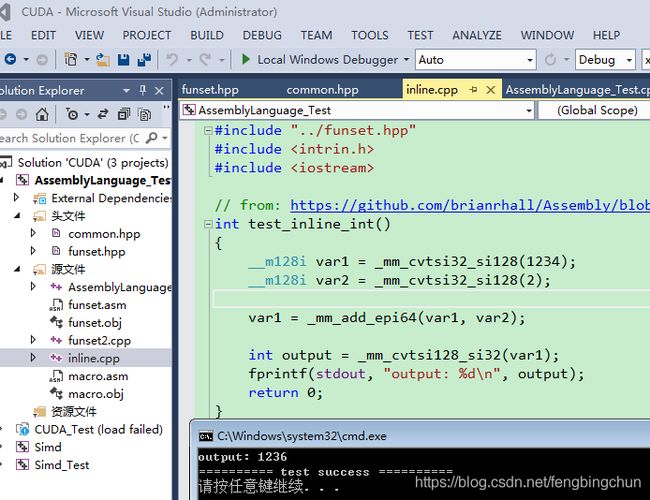
int test_inline_int()
{
__m128i var1 = _mm_cvtsi32_si128(1234);
__m128i var2 = _mm_cvtsi32_si128(2);
var1 = _mm_add_epi64(var1, var2);
int output = _mm_cvtsi128_si32(var1);
fprintf(stdout, "output: %d\n", output);
return 0;
}以上代码段是在Visual Studio下执行两个整数的相加,向_mm_add_epi64等这些指令来自于SSE2 Intrinsics,执行结果如下图所示:
NASM的内联汇编代码段如下:
int test_inline_int()
{
int var1 = 1234, var2;
asm ("mov %1,%%eax \n\t"
"add $2,%%eax \n\t"
"mov %%eax,%0 \n\t"
:"=r" (var2) /* %0: Out */
:"r" (var1) /* %1: In */
:"%eax" /* Overwrite */
);
fprintf(stdout, "var2: %d\n", var2);
return 0;
}以上代码段是在Linux下执行两个整数的相加,执行结果如下图所示:
![]()
MASM的宏代码段如下:
extrn ExitProcess : proc
_printInt PROTO C
intAdd MACRO dest, source1, source2
mov rax, source1
add rax, source2
mov dest, rax
ENDM
.DATA
intA QWORD 2
intB QWORD 4
intC QWORD 3
intD QWORD 7
result QWORD 0
.CODE
macro_usage PROC
push rbp
intAdd result, intA, intB
mov rcx, result
mov rax, 0
call _printInt
intAdd result, intC, intD
mov rcx, result
mov rax, 0
call _printInt
pop rbp
ret
macro_usage ENDP
END执行结果如下图所示:

NASM的宏代码段如下:
extern _printInt
%macro intAdd 3
mov rax, [%2]
add rax, [%3]
mov [%1], rax
%endmacro
section .data
intA: dq 2
intB: dq 4
intC: dq 3
intD: dq 7
result: dq 0
section .text
global macro_usage
macro_usage:
push rbp ; set up stack frame, must be alligned
intAdd result, intA, intB
mov rdi, qword [result]
mov rax, 0 ; or can be xor rax, rax, no vector registers in use
call _printInt
intAdd result, intC, intD
mov rdi, qword [result]
mov rax, 0
call _printInt
pop rbp ; restore stack
mov rax, 0 ; normal exit, no error, return value
ret ; return to operating system执行结果如下图所示:

GitHub:https://github.com/fengbingchun/CUDA_Test