巨详细!使用OpenCV和OpenVINO轻松创建深度学习应用

导读:本文来自《OpenCV深度学习应用与性能优化实践》,作者团队也是OpenCV DNN 模块的主要贡献者,是国内唯一的系统介绍OpenCV DNN 推理模块原理和实践的书。
OpenCV 是业界使用最为广泛的计算机视觉库,随着深度学习在计算机视觉领域的广泛应用,OpenCV 自3.3开始加入对深度学习推理的支持,即OpenCV DNN模块。
它支持TensorFlow、Caffe、Torch、DarkNet、ONNX 和 OpenVINO 格式的网络模型,开发者无需考虑模型格式的差异,直接调用DNN模块相关接口即可快速创建深度学习应用。
OpenVINO是英特尔推出的视觉推理加速工具包。OpenCV 3.4.1版本加入了英特尔推理引擎后端(英特尔推理引擎是OpenVINO中的一个组件),为英特尔平台的模型推理进行加速。
本文将以MobileNet-SSD模型为例,展示如何使用OpenCV和OpenVINO快速创建深度学习应用。
在深入代码之前,让我们了解一下OpenVINO工具包以及OpenCV是如何跟OpenVINO交互的。
OpenVINO工具包
2018 年 5 月 Intel 发布了 OpenVINO(Open Visual Inferencing and Neural Network Optimization, 开放视觉推理和神经网络优化)工具包,旨在为运行于 Intel 计算平台的基于神经网络的视觉推理任务提供高性能加速方案。
OpenVINO 提供了一整套在 Intel 计算设备上完成深度学习推理计算的解决方案,它支持 Intel CPU、 GPU、FPGA 和 Movidius 计算棒等多种设备。
OpenVINO 工具包的主要组件是 DLDT(Deep Learning Deployment Toolkit,深度学习部署工具包)。DLDT主要包括模型优化器(Model Optimizer)和推理引擎(Inference engine,IE)两部分。
模型优化器负责将各种格式的深度神经网络模型转换成统一的自定义格式,并在转换过程中进行模型优化;推理引擎接受经过模型优化器转换并优化的网络模型,为Intel的各种计算设备提供高性能的神经网络推理运算。
使用 DLDT 进行神经网络模型的部署,典型工作流程如图所示。
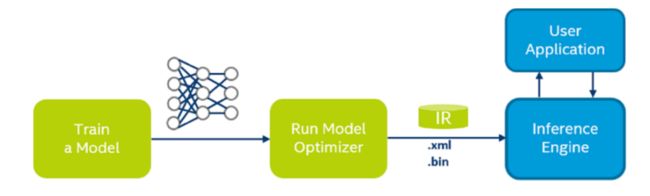
1)训练一个DLDT 支持的深度学习框架网络模型(Train a Model) ;
2)使用模型优化器对网络模型进行编译和优化(Run Model Optimizer),生成Openvino IR(Intermediate Representation,中间表示)格式的网络配置文件(.xml 文件)和模型参数文件(.bin 文件);
3)调用 Inference Engine(即 Intel 推理引擎)进行网络运算,并将结果返回给 User Application(应用程序)。
OpenCV如何使用OpenVINO
OpenCV的推理引擎后端使用OpenVINO的推理引擎API完成推理任务。推理引擎后端有两种工作模式:模型优化器模式和构建器模式,如下图所示。

模型优化器模式直接使用DLDT模型优化器编译后的OpenVINO格式(.xml和.bin)的网络模型进行推理计算,这种模式下,网络模型将被直接加载到推理引擎中,创建出一个推理引擎网络对象。而构建器模式则需要在DNN模块内部将网络模型逐层转换成内部表示,并通过推理引擎后端建立内部推理引擎网络。
相比构建器模式,模型优化器模式支持网络中所有的层,不需要逐层建立DNN网络,而是直接加载OpenVINO模型到推理引擎,能够减少在网络加载和运算推理过程中报错的情况。
了解了OpenCV 和 OpenVINO 相关内容之后,接下来详细讲解如何基于OpenCV和OpenVINO构建深度学习应用。
基于OpenCV和OpenVINO创建深度学习应用
第一步:安装OpenVINO
这里我们以 Ubuntu 18.04 上安装 OpenVINO 为例。从官网注册并下载OpenVINO开发包的Linux版本,
官网下载地址:
https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/choose-download/linux.html
如果下载顺利,你将得到文件名为 l_openvino_toolkit_p_< 版本号>.tgz 的压缩包,为了兼容更多的网络模型,我们选择安装目前最新的OpenVINO版本(OpenVINO-2020.3.194)。
OpenVINO开发包中包含了相应版本的OpenCV,安装OpenVINO时会默认安装OpenCV,因此无需额外安装OpenCV。
1. 解压并安装 OpenVINO 开发包核心组件
$ tar -xvzf l_openvino_toolkit_p_2020.3.194.tgz
$ cd l_openvino_toolkit_p_2020.3.194
运行图形化安装命令:
$ sudo ./install_GUI.sh
然后一路选择“Next”安装默认组件即可。如果一切顺利,安装文件将位于/opt/intel/openvino_2020.3.194/,同时会生成一个符号链接/opt/intel/openvino 指向最新的安装目录。至此,OpenVINO 核心组件安装完成,接下来安装依赖包。
2. 安装依赖包
使用 OpenVINO 写一个完整的视觉类应用,除了 OpenVINO 本身之外,还需要安装一些依赖包,包括但不限于 FFMpeg视频框架、CMake 编译工具、libusb(Movidius 神经计算棒 插件需要用到)等,安装步骤如下:
$ cd /opt/intel/openvino/install_dependencies
运行以下命令安装必要的依赖包:
$ sudo -E ./install_openvino_dependencies.sh
设置环境变量:
$ source /opt/intel/openvino/bin/setupvars.sh
建议将以上环境变量设置命令加入到用户的环境脚本当中,方法如下:
$ vi <用户目录>/.bashrc
在其中加入以内容:
$ source /opt/intel/openvino/bin/setupvars.sh
按 Esc 键,然后输入“:wq”保存并退出。接下来配置模型优化器,依次运行以下命令:
$ cd /opt/intel/openvino/deployment_tools/model_optimizer/install_prerequisites
$ sudo ./install_prerequisites.sh
上面这条命令会安装所有的深度学习框架的支持,如果只希望安装某一个框架的支持,以安装Caffe 框架支持为例,可以这么做:
$ sudo ./install_prerequisites_caffe.sh
至此,安装工作结束,下面验证安装好的 OpenVINO 环境是否可以工作。
3. 验证 OpenVINO 环境
进入推理引擎示例程序目录:
$ cd /opt/intel/openvino/deployment_tools/demo
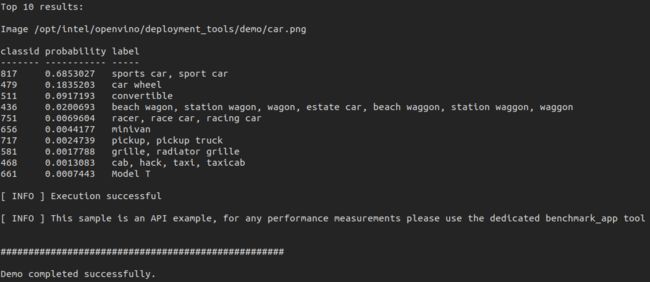
运行图片分类示例程序的验证脚本:
$ ./demo_squeezenet_download_convert_run.sh
如果一切顺利,输出结果将如图所示。
确保 OpenVINO 安装成功后,重新启动电脑:
$ reboot
检查OpenCV版本:
$ python
> import cv2 as cv
> print(cv.__version__)
如果安装成功,可以看到如下输出:
4.3.0-openvino-2020.3.0
第二步:模型准备
首先下载MobileNet-SSD的caffe模型:
• 模型参数文件MoblieNetSSD_deploy.caffemodel下载地址:https://drive.google.com/open?id=0B3gersZ2cHIxRm5PMWRoTkdHdHc
• 网络结构文件MoblieNetSSD_deploy.prototxt下载地址:https://raw.githubusercontent.com/chuanqi305/MobileNet-SSD/daef68a6c2f5fbb8c88404266aa28180646d17e0/MobileNetSSD_deploy.prototxt
模型下载好后,将caffe模型转换成OpenVINO格式:
1. 进入OpenVINO安装目录下的模型优化器目录:
cd /deployment_tools/model_optimizer
2. 使用OpenVINO模型优化器脚本mo.py将caffe模型转换成OpenVINO格式的模型:
python3 mo.py --input_model /MobileNetSSD_deploy.caffemodel --input_proto /MobileNetSSD_deploy.prototxt -o
通过input_model和input_proto 两个参数指明模型的参数和结构,并指定转换后网络的存储路径。
通过这一步,我们可以得到OpenVINO格式的MobileNet-SSD网络模型,包括MobileNetSSD_deploy.xml文件和MobileNetSSD_deploy.bin 文件。
第三步:使用OpenVINO模型进行目标检测
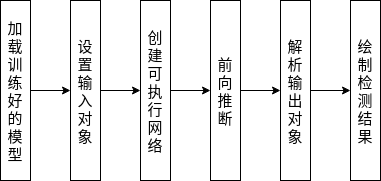
接下来开始进入我们的最后一步,使用转换好的OpenVINO格式的MobileNet-SSD模型进行实时目标检测。下面是整个目标检测过程的流程图。
流程图
程序代码
为方便起见,我们采用Python语言来创建应用。首先导入必要的Python库,包括numpy、argparse和cv2(OpenCV)。
# 导入必要的库
import numpy as np
import argparse
import cv2
接下来使用argparse对命令行输入参数进行解析。
# 组建参数parse
parser = argparse.ArgumentParser(
description='Script to run MobileNet-SSD object detection network ')
parser.add_argument("--video", help="path to video file. If empty, camera's stream will be used")
parser.add_argument("--model", type=str, default="MobileNetSSD_deploy",
help="path to trained model")
parser.add_argument("--thr", default=0.2, type=float, help="confidence threshold to filter out weak detections")
args = parser.parse_args()
程序执行命令行只需输入下列 3 个参数。
• video:图片或视频路径,不设置则从摄像头读取数据。
• model:训练好的模型路径。
• thr:分类阈值。
定义一个变量classNames,存储分类标签。注意,我们下载的模型是基于20分类数据集训练出来的,因此这里的类别标签有20个(加上背景是21个)。也有针对90分类数据集训练的模型,此处需要使用相对应的标签定义。
# 类别标签变量.
classNames = { 0: 'background',
1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat',
5: 'bottle', 6: 'bus', 7: 'car', 8: 'cat', 9: 'chair',
10: 'cow', 11: 'diningtable', 12: 'dog', 13: 'horse',
14: 'motorbike', 15: 'person', 16: 'pottedplant',
17: 'sheep', 18: 'sofa', 19: 'train', 20: 'tvmonitor' }
定义模型输入大小,MobileNet-SSD接受的输入图片大小为300*300
input_size = (300, 300)
接下来通过cv2.dnn.Net_readFromModelOptimizer()函数读取转换好的OpenVINO模型文件,初始化网络对象 net,并设置加速后端:
# 加载模型
net = cv2.dnn.Net_readFromModelOptimizer(args.model+".xml", args.model+".bin")
# 设置推理引擎后端
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_INFERENCE_ENGINE)
注意,这里cv2.dnn.DNN_BACKEND_INFERENCE_ENGINE指明使用的是推理引擎后端。
# 设置运算设备
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
推理引擎后端支持多种类型的运算设备,这里指定使用CPU作为运算设备。如果平台有英特尔集成显卡,也可以设置成cv2.dnn.DNN_TARGET_OPENCL,使用GPU来进行加速。
下一步设置图像输入设备,根据参数video选择可用输入设备或者输入路径:
# 打开视频文件或摄像头
if args.video:
cap = cv2.VideoCapture(args.video)
else:
cap = cv2.VideoCapture(0)
现在进入程序关键步骤,开始循环处理输入设备读到的帧图像,将读取到的图像转换成网络输入:
while True:
# 读取一帧图像
ret, frame = cap.read()
# 将图片转换成模型输入
blob = cv2.dnn.blobFromImage(frame, 0.007843, input_size, (127.5, 127.5, 127.5), False)
这一步参数比较多,也比较重要,做一下重点讲解:
1)frame是输入图像,0.007843是缩放因子,
2)input_size是模型所接受的输入大小,(127.5, 127.5, 127.5)是图像均值,它结合前面的缩放因子,在函数内部对输入图像做正规化处理。
3)False表示不进行R和B通道置换。当模型接受的通道顺序和图像均值的通道顺序不一致时,swapRB 需要设置成 true。
接下来是设置网络输入和运行网络推理:
# 转换后的待输入对象blob设置为网络输入
net.setInput(blob)
# 开始进行网络推理运算
detections = net.forward()
然后是结果解析。
MobileNet-SSD 模型的检测结果detections是一个4维数组,数组的4个维度大小分别是[1,1,N,7]。
N表示检测出的对象数目,7表示每个对象用一个含有7个元素的数组描述,7个元素分别代表图片id、类型id、置信度、对象框左上角x坐标,对象框左下角y坐标、对象框右下角x坐标、对象框右下角y坐标,接下来根据这个4维数组绘制运行结果。
首先获取图像大小,根据再通过遍历所有检测出的对象,通过参数thr筛除部分置信度较低的对象:
# 获取输入图像尺寸(300x300)
cols = input_size[1]
rows = input_size[0]
for i in range(detections.shape[2]):
confidence = detections[0, 0, i, 2] # 目标对象置信度
if confidence > args.thr: # Filter prediction
class_id = int(detections[0, 0, i, 1]) # 目标对象类别标签
获取被检测对象框的顶点坐标和图像的缩放比,并获取实际目标对象框的坐标:
# 目标位置
xLeftBottom = int(detections[0, 0, i, 3] * cols)
yLeftBottom = int(detections[0, 0, i, 4] * rows)
xRightTop = int(detections[0, 0, i, 5] * cols)
yRightTop = int(detections[0, 0, i, 6] * rows)
# 变换尺度
heightFactor = frame.shape[0]/300.0
widthFactor = frame.shape[1]/300.0
# 获取目标实际坐标
xLeftBottom = int(widthFactor * xLeftBottom)
yLeftBottom = int(heightFactor * yLeftBottom)
xRightTop = int(widthFactor * xRightTop)
yRightTop = int(heightFactor * yRightTop)
最后将检测结果绘制到原始图像上:
# 框出目标对象
cv2.rectangle(frame, (xLeftBottom, yLeftBottom), (xRightTop, yRightTop),
(0, 255, 0))
# 标记标签和置信度
if class_id in classNames:
label = classNames[class_id] + ": " + str(confidence)
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)
yLeftBottom = max(yLeftBottom, labelSize[1])
cv2.rectangle(frame, (xLeftBottom, yLeftBottom - labelSize[1]),
(xLeftBottom + labelSize[0], yLeftBottom + baseLine),
(255, 255, 255), cv2.FILLED)
cv2.putText(frame, label, (xLeftBottom, yLeftBottom),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
print(label) # 输出类别和置信度
cv2.namedWindow("frame", cv2.WINDOW_NORMAL)
cv2.imshow("frame", frame)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"): # 按下q键退出程序
break
if key == ord("s"): # 按下s键保存检测图像
cv2.imwrite('detection.jpg', frame)
至此,整个目标检测应用的代码就完成了,接下来输入以下命令运行目标检测程序:
$ python mobilenet_ssd_python.py
这里我们使用的默认参数,通过摄像头直接采集图像,默认模型采用我们转换好的MobileNetSSD_deploy(.xml/.bin)文件,阈值设为0.2。
这时候我们可以看到终端中将输出检测到的目标置信度,同时在视频图像中框处检测到的目标,左上角为目标分类结果和分类置信度。
终端中的检测结果输出:
chair: 0.9978288
chair: 0.29011992
person: 0.9536861
tvmonitor: 0.6713625
tvmonitor: 0.26635352
...
实际检测图像如下:

以上内容摘自《OpenCV深度学习应用与性能优化实践》一书,经出版方授权发布。

《OpenCV深度学习应用与性能优化实践》
作者:吴至文,郭叶军,宗炜,李鹏,赵娟
这是国内唯一系统介绍OpenCV 深度学习推理原理与实践的书,Intel与阿里巴巴高级图形图像专家联合撰写,深入解析OpenCV DNN 模块、基于GPU/CPU的加速实现、性能优化技巧与可视化工具,以及人脸活体检测等应用,涵盖Intel推理引擎加速等鲜见一手深度信息。
也欢迎在以下链接直接购买:

更多精彩回顾
书讯 |华章计算机拍了拍你,并送来了8月书单(下)
书讯 | 华章计算机拍了拍你,并送来了8月书单(上)
上新 | 首本深入讲解Linux内核观测技术BPF的书上市!
书单 | 《天才引导的历程》| 西安交通大学送给准大一新生的礼物
干货 | 机器人干活,我坐一边喝茶——聊聊最近爆火的RPA
收藏 | 揭秘阿里巴巴的客群画像


点击阅读全文购买