XFS:大数据环境下Linux文件系统的未来?
AD:
WOT2015 互联网运维与开发者大会 热销抢票
【51CTO 2月7日外电头条】Linux有好多种件系统,但往往最受关注的是其中两种:ext4和btrfs。XFS开发者Dave Chinner近日声称,他认为更多的用户应当考虑XFS。他谈到了为了解决XFS中最严重的可扩展性问题所做的工作,还谈到了他认为将来的发展走向。如果他说的一点都没错,接下来几年我们在XFS方面有望看到更多的动静。
XFS经常被认为是适合拥有海量数据的用户的文件系统。Dave表示,XFS非常适合扮演这个角色;它对许多工作负载而言向来表现不俗。以前往往问题出在元数据写入方面;对生成大量元数据写入操作的工作负载缺少有力的支持历来是该文件系统的薄弱环节。简而言之,元数据写入速度很慢,扩展性欠佳,甚至只能适用于单个处理器。
速度到底有多慢?Dave制作了几张幻灯片,显示XFS与ext4相比的fs-mark结果。哪怕在单个处理器上,XFS的表现也要差得多(速度只有ext4的一半);如果线程数量多达8个,情况完全变得更糟;但线程数量超过8个后,ext4也遇到了瓶颈,速度慢下来。就元数据频繁变化的输入/输出密集型工作负载(解开tarball文件就是个例子)而言,Dave表示ext4的速度可能比XFS快20倍至50倍。速度这么慢足以表明XFS确实存在严重问题。
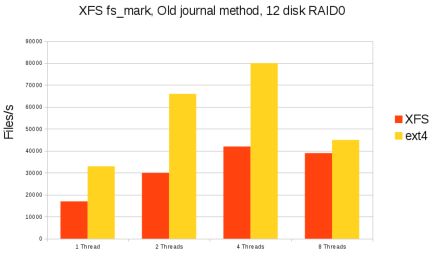
延迟的日志
结果表明问题其实出在日志的输入/输出上。针对元数据的变化,XFS会生成大量的日志流量。在最糟糕的情况下,几乎所有的实际输入/输出流量都用于日志——而不是用于用户试图想要写入的数据。多年来人们试图采用多种办法来解决这个问题,比如对算法进行重大改变,另外进行许多重大的优化和调整。不需要的一点是任何一种磁盘上格式变化,不过这在将来可能由于其他原因而在筹划之中。
元数据密集型的工作负载最后可能会在很短的时间内多次改变同一个目录块;那些改变每一次都会生成一个记录,记录必须写入到日志中。这正是导致巨大日志流量的根源。解决这个问题的办法从概念上来说很简单:延迟日志更新,并且将针对同一目录块的变更合并到一个条目中。这些年来,以一种可扩展的方式实际落实这个概念颇费周折,但是现在取得了进展;延迟的日志(delayed logging)将是3.3内核中唯一得到支持的XFS日志模式。
实际的延迟日志技术主要由ext3文件系统借鉴而来。由于这种算法已知切实可行,证明它同样适用于XFS所需的时间则短得多。除了性能上的优点外,这一变化最终促使代码数量减少。有谁想详细了解其工作原理,应该会在内核文档树中的filesystems/xfs-delayed-logging.txt找到所需内容。
延迟日志是一大变化,但绝不是唯一的变化。日志空间预留快速路径是XFS中非常热门的路径;现在它是无锁的,不过慢速路径现阶段仍需要全局锁。异步元数据写回代码形成了非常分散的输入/输出,结果大幅降低了性能。现在,元数据写回在写出之前已被延迟和分类。用Dave的话来说,这意味着文件系统在做输入/输出调度程序的工作。但是输入/输出调度程序处理的请求序列通常限制在128个条目,而XFS的延迟元数据写回序列可以有数千个条目,所以有必要在输入/输出提交之前在文件系统中完成分类操作。“活动日志项”(Active log item)这种机制可以累计变化,并批量运用变化,以此改进(庞大的)分类日志项列表的性能。元数据缓存也被移到了页面缓存器的外面,页面缓存器往往会在不合适的时间收回页面。等等。
诸文件系统相比如何?
那么,现在XFS的扩展性如何?如果是一两个线程,XFS的速度仍比ext4慢一点,但是它可以线性扩展,支持多达8个线程,而ext4的情况比较糟,btrfs的情况要糟得多。对XFS来说扩展性方面的局限性如今出现在虚拟文件系统层核心中的锁定上,根本不是出现在针对特定文件系统的代码上。现在即使对一个线程来说,目录遍历速度也更快,对8个线程来说,速度快得多。他表示,这些并不是btrfs开发人员可能展示给人的那种结果。
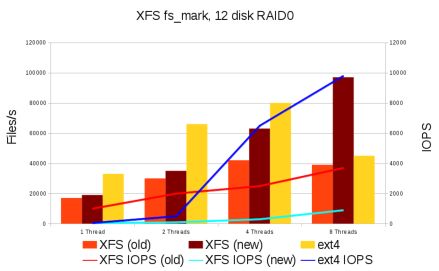
现在空间分配方面的可扩展性要比ext4快“几个数量级”。这是由于3.2内核中添加了“bigalloc”特性而引起的变化,如果使用了足够大的块,这项特性可以将ext4在空间分配方面的可扩展性提高两个数量级。遗憾的是,该特性还将小文件的空间使用量增加了同样数量,以至于需要160GB来存放内核树。bigalloc并不是很适合ext4的另外一些选项,而且需要管理员回答复杂的配置问题;在创建文件系统时,管理员必须考虑文件系统在整个使用寿命期间将如何使用。Dave表示,ext4存在架构方面的不足——尤其是使用位图来用于跟踪空间,这是上世纪80年代的文件系统存在的典型问题。它根本无法扩展,成为真正超大的文件系统。
btrfs中的空间分配甚至比ext4还要来得慢。Dave表示,问题主要出在闲置空间缓存的走查,目前这是处理器密集型的操作。这不是btrfs中的架构问题,所以它应该有望得到解决,但需要做一番优化工作。
Linux文件系统的未来
这方面有何进展?现阶段,XFS中的元数据性能和可扩展性可以被认为是已得到解决的问题。现在性能瓶颈出现在虚拟文件系统(VFS)层,所以需要在这方面开展下一轮工作。但是未来面临的一大挑战在于可靠性方面;这可能需要XFS文件系统作出一些相当大的变化。
可靠性不仅仅是不丢失数据这么简单——但愿XFS在这方面已经做得很到位,这在将来其实是个可扩展性问题。让数千兆兆字节(PT)的文件系统下线、运行一款文件系统检查和修复工具,这根本不切实际;将来,这项工作其实需要在线进行。这就需要把成熟可靠的故障检测机制融入到文件系统当中,以便可以实时验证元数据正确无误。其他一些文件系统也在实施验证数据的机制,但是这似乎超出了XFS的范围。Dave表示,数据验证工作最好是在存储阵列层面或应用程序层面完成。
“元数据验证”意味着,让元数据自我描述,保护文件系统,防范被存储层指错方向的写入。添加校验和技术还不够——核验和只能证明现有的是被写入的。以适当方式自我描述的元数据能够检测写入到错误地方的块,并且帮助重新组装完全坏掉的文件系统。它还能防止“"reiserfs问题”,即文件系统的修复工具被过时的元数据或存储在待修复的文件系统中的文件系统映像里面的元数据搞糊涂。
让元数据可以自我描述需要作出许多变化。每个元数据块将包含文件系统的UUID;每个块中还有块和索引节点(inode)的编号,那样文件系统就能验证元数据来自预期的地方。将来会有检验和机制,用来检测受到损坏的元数据块,还会有所有者标识符,用来将元数据与归属的索引节点或目录关联起来。反向映射分配树将让文件系统可以迅速确认任何某个块属于哪个文件。
不用说,目前的XFS磁盘上格式并不提供存储所有这些额外数据的机制。这意味着磁盘上格式会有变化。据Dave声称,不打算提供任何形式的向前或向后格式兼容;格式变化将是真正重大的变化。开展这项工作是为了便于完全自由地设计一种长期服务于XFS用户的新格式。虽然正在改变格式来添加上述的可靠性功能,但是开发人员也会为目录结构中的d_type、NFSv4版本计数器、索引节点创建时间以及可能更多对象添加空间。最大的目录大小(目前只有区区32GB)也会得到提高。

这一切将带来许多优点:主动检测文件系统受损情况、定位和更换缺乏联系的块以及更好的在线文件系统修复。Dave表示,这意味着在将来很长一段时间,对Linux环境下的大数据应用程序而言,XFS仍将是最出色的文件系统。
从btrfs的角度来看,这一切又意味着什么呢?Dave表示,btrfs显然不是针对处理元数据密集型工作负载的文件系统而优化;有一些严重的可扩展性问题成为了拦路虎。对于处于早期开发阶段的一款文件系统来说,这完全在意料之中。其中一些问题需要借以时日才能克服,但可能存在这种情况:其中一些问题可能无法得到解决。另一方面,btrfs中的可靠性功能开发得很完善,这款文件系统完全能够提供在接下来几年预期的存储功能。
而ext4存在架构可扩展性问题。据Dave的结果显示,它不再是速度最快的文件系统。有几个方案可用来改进可靠性,其磁盘上格式显露了老态。ext4支持在不远将来的存储需求有难度。
考虑到这点,Dave在最后抛出了一个问题。由于其丰富功能,btrfs不日将取代ext4,成为许多Linux发行版中的默认文件系统。与此同时,ext4在处理大多数工作负载方面性能不如XFS,包括它在传统上表现更强劲的应用领域。一些可扩展性问题甚至出现在了更小的服务器系统上。“汇聚半完成的项目”并不总是能取得很好的效果;Dave表示,ext4并不如人们想象的那么稳定或久经测试。于是他问道:为什么我们仍需要ext4?
有人可能认为,ext4开发人员会想出很好的办法来回答这个问题,但是目前还没有人回答得了。