some collected dl tips
调参侠的自我修养——深度学习调参秘籍_夕小瑶的卖萌屋-CSDN博客_人工智能调参侠
https://blog.csdn.net/xixiaoyaoww/article/details/105036075
NLP、炼丹技巧和基础理论文章索引_夕小瑶的卖萌屋-CSDN博客_nlp 炼丹
https://blog.csdn.net/xixiaoyaoww/article/details/104553483
项目经验
调研做好,找准起点
接手一个算法问题后,如果时间很充裕,就可以先定位一下该算法问题所对口的学术会议或期刊:
比如你要解决query-doc相关性匹配的问题,那么你就要优先考虑SIGIR,CIKM等IR强相关的会议,而不是NLP的会议;
如果你要解决NLI、问答、对话这种语义匹配的问题,那么你就要优先考虑ACL、EMNLP、NAACL、COLING这种NLP会议,而不是IR会议了;
如果你把匹配模型做好了,想压缩一下变得更小更快,那就要优先考虑ICLR、NIPS这种更general的深度学习、神经网络会议了。
定位不出来算法问题的对口会议?最起码可以逛逛AAAI和IJCAI吧(虽然鱼龙混杂问题比较严重)
然后根据文章title,找几篇跟你的算法问题最接近的近两年的paper,慢慢调研。通过这些paper的related work章节和实验章节,还很容易追溯出更早的工作,(基本就是paper中提到的 baseline 和 related work);所以一般没有必要去手动调研更早期的paper。
如果时间很不充裕,要解决的问题又比较简单(比如就是个典型的文本分类问题、序列标注问题等),在知乎上搜一下也经常能发现惊喜。
总之,非常不建议直接去github一个repo一个repo的蛮力调参,大量的宝藏方法是很难通过通用搜索引擎来找到的(虽然这种行为在比赛刷榜的时候随处可见)。
先跑起来
不要一上来就自己动手写模型。
建议首先用成熟的开源项目及其默认配置(例如 Gluon 对经典模型的各种复现、各个著名模型作者自己放出来的代码仓库)在自己的数据集上跑一遍,在等程序运行结束的时间里仔细研究一下代码里的各种细节,最后再自己写或者改代码。
构建策略迭代闭环,找准努力方向
避免蛮力试错的第二步就是构建完整的策略迭代闭环。由于不同的问题有不同的限定,因此不存在一个绝对的流程可以恰好适合所有算法问题,(一般都是非线性的,部分步骤需要来回修改,反复调整)。夕小瑶最常用的迭代闭环就是
数据集分析 - 预处理策略 - 算法策略 - 模型评价 - case study
对于小白,往往是在第三步和第四步陷入死循环,看不到前两个环节和最后一个环节。
对于大白,往往还能额外考虑一下预处理策略。
1. 数据集分析
很多小白拿到数据集后就开始迫不及待的调参之路了,其实在开始之前对数据集做个简单的分析,可能有助于大大降低你之后的体力劳动(提前排除不靠谱的策略和不敏感的超参数),并大大降低初次接触新任务时犯致命错误的概率。
比如,简单统计一下样本长度分布,你就可以知道max sequence length这个参数的大体取值范围,没有必要把它当成一个正儿八经的超参数从小调到大;简单统计一下类别分布,你就不会在正负样本比9:1的情况下为一个90%的准确率沾沾自喜,误导决策;多扫几眼数据集,你就不会在初次接触文本风格相关任务时把英文单词统一小写了。
2.预处理策略与算法策略
这个环节不用太多赘述啦,最直接方法就是搬运上一节的调研结果,将一些paper中比较有效的策略搬过来进行验证。不过,尤其是注意一个meaningful的问题,即我搬运这个策略,甚至设计一个新的策略,目的是什么?要解决什么问题?毕竟很多paper中的策略的适用场景是很局限的,毫无目的的搬运可能会大大增加无用功。
3.模型评价
模型评价的问题在打比赛时一般不会遭遇,在比较成熟的算法任务中一般也被解决了。比如谈到文本分类,就能想到acc、f1等指标;谈到机器翻译,就能想到bleu等。然而有很多算法问题是很难找到一个 无偏且自动 的评价指标的。
一个典型的例子就是开放域对话生成问题。
虽然与机器翻译一样,这也是个生成问题,但是如果你沿用BLEU作为评价指标,那么BLEU对对话生成来说就是一个有偏的评价指标,你刷的再高也难以真实反映对话生成模型的质量(对话生成问题中不存在机器翻译中的强的对齐关系)。更糟糕的是,由于找不到无偏的自动指标,因此每迭代一次策略,就需要让一群人轰轰烈烈的标注打分,还要去检验是否存在异常标注者(说不定有个宝宝就耍脾气了给你乱打一通),这无疑是效率非常低的,纵然你代码写的再快,也会被评价问题所拖累。
业务中更是可能有一些模棱两可的算法任务,比如“小夕,来个更好的句子表示吧”,那么如何无偏的评价一个表示的好坏,就需要你在大规模开搞之前仔细设计清楚了。没有一个客观、无偏且自动的评价指标,策略迭代无疑会非常缓慢甚至到后期推翻重来。
4.case study
像accuracy、f1、bleu等标量型评价指标可以指导当前策略整体上好不好,但是却无法帮助你发现更细粒度的问题。很多小白在入行时,喜欢把各种花里胡哨的算法和各种不着边际的想法一顿乱试,以为有了模型评价指标就可以很轻松的评判一个算法“是不是有用”,以及可以因此纯拼体力的炼丹。
但!是!当你额外的做一下case study之后,可能你会突然发现,很多自己之前的尝试完全就是多余的:
你以为数据不均衡问题很严重,case study才发现模型其实很轻松;
你以为推理问题离自己很遥远,case study才发现一大半的错例是推理问题导致的;
你以为领域问题不重要,case study才发现太多模型没见过的领域术语了;
你以为数据集很干净,case study却发现了大量错别字导致的错误决策;
总之,在经验不足的情况下,通过case study可以帮助你排除大量的不必要尝试,并有助于发现当前策略的瓶颈,针对性的寻找策略和创新。
重视bug,找准翻车原因
效果不好时,首先检测有没有bug。
摆脱“洁癖”,提高写代码速度
早期探索阶段,没必要封装代码,能跑能看效果即可。
分规模验证,快速完成实验
这个问题写出来时感觉很白痴,但是据我观察,大部分新手都存在这个问题。如果你给他100万规模的训练集,他就会拿整个训练集去调试;你给他1000万规模的训练集,他还是拿整个训练集去调试。。。
第一阶段:调通代码。这时候象征性的挂几百条样本就够了,修正语法错误和严重的逻辑错误。
第二阶段:验证收敛性。很多bug不会报错,但会导致训练完全崩溃或者压根就没在训练。可以对几百条或者几千条样本进行训练,看看若干epoch之后训练loss是否能降低到接近0。
第三阶段:小规模实验。在万级或十万级别的小样本集上验证模型表现,分析超参数敏感性。这一阶段在数据规模不大时(比如几十万或一二百万)其实可有可无,当训练数据极其庞大时(十亿级甚至百亿级的话)还是必要的。有一些很细微的bug虽然不会影响收敛,却会显著影响最终模型的表现。此外也有助于发现一些离谱的超参数设置。
第四阶段:大规模实验。即,有多少训练数据,就上多少,甚至多训练几个epoch。进行到第四阶段时,应当绝对保证代码是高度靠谱的,基本无需调参的,否则试错代价往往难以承受。
实验管理 & 项目管理
实验管理就是,要记录下来每一次实验的策略名和对应的实验结果,一般以表格的形式记录。
这里可以用excel、markdown编辑器等记录,当然更建议使用支持云端同步的工具来记录(比如石墨文档、印象笔记或内网的相关工具等),以防电脑被偷、文件误删等意外导致的悲剧。
但是,有时候实验着急,对策略的描述不够仔细怎么办?比如某次实验同时改变了具体策略、还改了超参数、预训练模型等一堆东西,不能用一个名字概括全部,怎么办呢?
最简单的做法就是与版本管理工具配合,再也不用担心未来settings丢失、模型无法复现、模型无法追溯环境等问题了。
而要实现版本管理,也很简单,Git自然是不二之选。
首先,务必保证训练日志、eval日志是以文件的形式存了下来,而不是打印到屏幕上变成过眼云烟了;此外,需要保证每一次运行时的settings(比如超参数、数据集版本、ckpt存储路径等)都能保存到日志文件中,且尽量封装一个run.sh来维护训练任务的启动环境。
之后就是看每个人自己的习惯啦。夕小瑶 的习惯是
- 主线策略每成功推进一步,就调用git tag打个tag。这里的tag即策略名,与实验管理的表格中的策略名对齐
- 如果要在某个策略的基础上尝试一个很不靠谱的探索,那么可以在当前策略的基础上拉一个分支出来,在这个分支上完成相应事情后切回主分支。当然啦,万一这个分支上的策略work了,就可以考虑将其转正,合入主分支并打上相关tag
调参经验 - general
在调参之前,小夕强烈建议在代码里完成下面几件事:
-
可视化训练过程中每个step(batch)的loss。如果是分类任务,可以顺便可视化出每个batch的准确率(不均衡数据可视化F1-score)。
-
将训练日志在打印到屏幕上的同时也写入到本地磁盘。如果能实时同步写入那更好了(在python中可以用logging模块可以轻松实现。一个handler输出到屏幕,再设置一个handler输出到磁盘即可)。
-
借助tensorflow里的FLAGS模块或者python-fire工具将你的训练脚本封装成命令行工具。
-
代码中完成tensorboard等训练过程可视化环境的配置,最少要可视化出训练loss曲线。
-
如果使用tensorflow,记得设置GPU内存动态增长(除非你只有一个GPU并且你确信一个训练任务会消耗GPU的一大半显存)
-
初始调参阶段记得关闭L2、Dropout等用来调高模型泛化能力的超参数呐,它们很可能极大的影响loss曲线,干扰你的重要超参数的选取。
-
根据自己的任务的量级,预估一个合理的batch size(一般来说64是个不错的初始点。数据集不均衡的话建议使用更大一点的值,数据集不大模型又不是太小的情况下建议使用更小一些的值)。
数据预处理:
对输入数据进行归一化处理,能够显著加速梯度下降的收敛过程。如果不归一化,输入数据每个维度的尺度范围的差异会对梯度下降的迭代过程造成影响。
权重初始化:
目前有很多关于如何做权重参数初始化的研究。因为深度学习权重初始化很重要,如果有问题就不会有好结果。这是一个非常重要的问题。
如果权值初始化为0的话,用梯度下降算法,那会完全失效。因为如果权重初始化为0,每个神经元将会输出同样的结果,方向传播时就会计算出同样的梯度,最后会得到完全相同的参数更新,所以算法失效。
如果用很小的随机数值初始化。比如用高斯分布乘以一个很小的常数进行初始化:W = 0.01 * np.random.randn()。对于层数较少的神经网络效果很好,但是随着层数的增加,对于初始化更为敏感。
如何初始化:
深度学习之参数初始化策略_浅梦的学习笔记-CSDN博客_glorot初始化
https://blog.csdn.net/u012151283/article/details/78230891
作者:萧瑟
链接:https://www.zhihu.com/question/41631631/answer/94816420
- 要做梯度归一化,即算出来的梯度除以minibatch size;
- clip c(梯度裁剪): 限制最大梯度,其实是value = sqrt(w1^2+w2^2….),如果value超过了阈值,就算一个衰减系系数,让value的值等于阈值: 5,10,15;
- dropout对小数据防止过拟合有很好的效果,值一般设为0.5,小数据上dropout+sgd在我的大部分实验中,效果提升都非常明显.因此可能的话,建议一定要尝试一下。 dropout的位置比较有讲究, 对于RNN,建议放到输入->RNN与RNN->输出的位置.
- adam,adadelta等,在小数据上,我这里实验的效果不如sgd, sgd收敛速度会慢一些,但是最终收敛后的结果,一般都比较好。如果使用sgd的话,可以选择从1.0或者0.1的学习率开始,隔一段时间,在验证集上检查一下,如果cost没有下降,就对学习率减半. 我看过很多论文都这么搞,我自己实验的结果也很好. 当然,也可以先用ada系列先跑,最后快收敛的时候,更换成sgd继续训练.同样也会有提升.据说adadelta一般在分类问题上效果比较好,adam在生成问题上效果比较好。
- 除了gate之类的地方,需要把输出限制成0-1之外,尽量不要用sigmoid,可以用tanh或者relu之类的激活函数.1. sigmoid函数在-4到4的区间里,才有较大的梯度。之外的区间,梯度接近0,很容易造成梯度消失问题。2. 输入0均值,sigmoid函数的输出不是0均值的。
- rnn的dim和embdding size,一般从128上下开始调整. batch size,一般从128左右开始调整.batch size合适最重要,并不是越大越好;
- word2vec初始化,在小数据上,不仅可以有效提高收敛速度,也可以可以提高结果;
- 尽量对数据做shuffle;
- 如果你的模型包含全连接层(MLP),并且输入和输出大小一样,可以考虑将MLP替换成Highway Network,我尝试对结果有一点提升,建议作为最后提升模型的手段,原理很简单,就是给输出加了一个gate来控制信息的流动。
关于 Ensemble
Ensemble是论文刷结果的终极核武器,深度学习中一般有以下几种方式
- 同样的参数,不同的初始化方式
- 不同的参数,通过cross-validation,选取最好的几组
- 同样的参数,模型训练的不同阶段,即不同迭代次数的模型。
- 不同的模型,进行线性融合. 例如RNN和传统模型.
- 训 RNN 注意加上 gradient clipping,不然会导致训练一段时间以后 loss 突然变成 Nan。
- tying input & output embedding(就是词向量层和输出 softmax 前的矩阵共享参数,在语言模型或机器翻译中常用)时学习率需要设置得非常小,不然容易 Nan。
- 在数据集很大的情况下,一上来就跑全量数据。建议先用 1/100、1/10 的数据跑一跑,对模型性能和训练时间有个底,外推一下全量数据到底需要跑多久。在没有足够的信心前不做大规模实验。
-
不要只喜欢漂亮的模型结构,瞧不起调参数的论文/实验报告。看论文时也需要看超参数设置等细节。NLP 领域主要推荐以下几篇:
Regularizing and Optimizing LSTM Language Models(LSTM 的训练技巧)
Massive Exploration of Neural Machine Translation Architectures(NMT 里各个超参的影响)
Training Tips for the Transformer Model(训练 Transformer 时会发生的各种现象)
RoBERTa: A Robustly Optimized BERT Pretraining Approach(BERT 预训练技巧,虽然跟大部分人没啥关系)
作者:Towser
链接:https://www.zhihu.com/question/41631631/answer/862075836
- 虽然有至少十种激活函数,但初期用 Relu 或者和某个 paper 统一即可。优化器只推荐 Momentum 和 Adam。在这些方面做尝试意义不大,如果性能提升反倒可能说明模型不成熟。不推荐做人肉模型设计,比如把某层卷积改大一点,或者微调一下通道数。除非有特别 insight,不要自己乱设计玄学组件,以吸收别人经验为主。
-
链接:https://www.zhihu.com/question/41631631/answer/1129785528
- 激活函数用relu一般就够了,也可以试试leaky relu。
- batchnorm和dropout可以试,放的位置很重要。优先尝试放在最后输出层之前,以及embedding层之后。RNN可以试layer_norm。有些任务上加了这些层可能会有负作用。
- metric learning中先试标label的分类方法。然后可以用triplet loss,margin这个参数的设置很重要。
- batchsize设置小一点通常会有一些提升,某些任务batchsize设成1有奇效。
- embedding层的embedsize可以小一些(64 or 128),之后LSTM或CNN的hiddensize要稍微大一些(256 or 512)。(ALBERT论文里面大概也是这个意思)
- 模型方面,可以先用2或3层LSTM试一下,通常效果都不错。
- weight decay可以试一下,我一般用1e-4。
- 有CNN的地方就用shortcut。CNN层数加到某一个值之后对结果影响就不大了,这个值作为参数可以调一下。
- GRU和LSTM在大部分任务上效果差不多。
- 看论文时候不要全信,能复现的尽量复现一下,许多论文都会做低baseline,但实际使用时很多baseline效果很不错。
- 对于大多数任务,数据比模型重要。面对新任务时先分析数据,再根据数据设计模型,并决定各个参数。例如nlp有些任务中的padding长度,通常需要达到数据集的90%以上,可用pandas的describe函数进行分析。
理性调参,把算力和时间留给策略探索
调参之前 - 『模型是否 work』
先把锦上添花的东西去掉,如数据增广,玄学学习率和超参,魔幻损失函数,异形模型。如果世界上有一个非要加八个增广和 1.96e-4 学习率 42 batchsize,配上四种混合损失函数的模型,改动一点都不行,它应该存在于灵能文明。
可以先造一些尽量玩具的模型,验证代码正确性。(最开始的时候,主要看是否大致work;naive的model即可,不需trick)
作者:hzwer
链接:https://www.zhihu.com/question/41631631/answer/859040970
调参的第一步,也是最重要的一步,是进行超参数敏感性分析,找到对当前任务性能影响最大的几个超参数,之后再进行精调。
而要确定各个超参数的敏感性,一方面可以根据自身经验来定,一方面可以根据各paper中的取值(差异大的超参数可能是敏感超参,大家都取值相同的一般不敏感),实在不确定,跑两三组实验就够确定敏感性了,完全没有必要来个“网格搜索”。
调参顺序1 - from 夕小瑶
阶段1: learning rate --> 阶段2: batch size和momentum --> 阶段3: 学习率衰减策略.
阶段1:lr
这个阶段是最容易的,打开tensorboard,按照指数规律设置几组可能的学习率,小夕一般设置如下六组[1, 0.1, 0.01, 0.001, 0.0001, 0.00001]。
如果你的GPU比较多,你还可以在几个大概率学习率附近多插几个值,比如小夕一般喜欢再插上[0.03, 0.05, 0.003, 0.005, 0.007, 0.0005]这几个值(最起码在做文本分类任务时经常撞到不错的结果哦)。
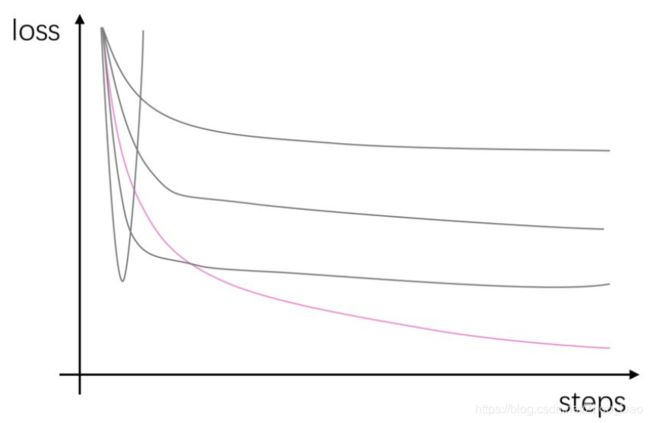
当这些任务跑完时,就可以去tensorboard里挑选最优学习率啦。选择原则也很简单,选择那条下降的又快又深的曲线所对应的学习率即可,如下图,选择粉色那条曲线:(收敛太早太晚都不好,也要注意收敛的程度)
选择好学习率后,顺便再观察一下这条曲线,选择一个差不多已经收敛的step作为我们的训练总steps(如果数据集规模小的话也可以换算成epoch次数)。如图
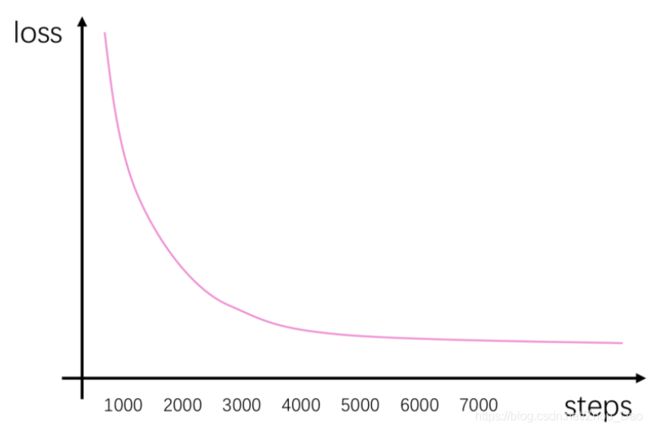
可以看到,我们的模型在迭代到4K步的时候就基本收敛了,保险起见我们可以选择6K来作为我们训练的总num_steps。
关于GPU
如果GPU有限并且任务对显存的消耗没有太大,那么可以同时在一个GPU里挂上多组训练任务(这时每组任务的计算速度会有损耗,但是完成全部任务所消耗的总时间大大减少了)。小夕一般先随便设个学习率跑一下,确定一下每个任务大体消耗的显存,然后在shell脚本里将这若干个任务塞进GPU里并行跑(shell脚本里直接用&扔进后台即可)。当然,如果代码里用到了时间戳,可以给时间戳加个随机噪声或者在shell脚本里为任务之间加上一定的时间间隔,免得训练任务的时间戳发生碰撞。
阶段2:batch size和momentum
带着第一阶段得到的超参数,我们来到了第二阶段。
如果我们使用的是Adam这种“考虑周全”的优化器的话,动量项momentum这类优化器的超参数就基本省了。然而,不仅是小夕的经验,业界广泛的经验就是Adam找到的最优点往往不如精调超参的SGD找到的超参数质量高。因此如果你想要追求更加极限的性能的话,momentum还是要会调的哦。
momentum一方面可以加速模型的收敛(减少迭代步数),另一方面还可以带领模型逃离差劲的局部最优点(没理解的快回去看看momentum SGD的公式)。而batch size参数似乎也能带来类似的作用——batch size越小,噪声越大,越容易逃离局部最优点,同时这时对梯度的估计不准确,导致需要更多的迭代步数。因此小夕一般将这两个参数一起调。
另外,由于这两个超参数可能涉及到模型的泛化能力,因此记得在监控loss曲线的同时也要监控开发集准确率哦。如果两组实验的loss曲线的形状都很好,这时就可以根据开发集准确率来做取舍了(一般不会出现loss曲线形状很差但是开发集准确率超好的情况)。
阶段3:学习率衰减策略
调参顺序2 - from 知乎
关于神经网络的调参顺序? - 知乎
https://www.zhihu.com/question/29641737
阶段1: learning rate & 衰减策略 --> 阶段2: batch size --> other params: L1,L2正则化; epoch.
L1,L2正则化参数,也就是很多深度学习框架里面的wd参数,一般默认是0.0001,调整正则化的参数可以根据模型表现来,过拟合的时候可以适当加大系数,非过拟合的时候可不调这个参数.
超参上,learning rate 最重要,推荐了解 cosine learning rate,其次是 batchsize 和 weight decay。当你的模型还不错的时候,可以试着做数据增广和改损失函数锦上添花了。
链接:https://www.zhihu.com/question/41631631/answer/859040970
调参经验-text clf
原文:
文本分类有哪些论文中很少提及却对性能有重要影响的tricks?
分词器
首先就有一个问题,真的是算法越“先进”的分词器就会给下游任务带来越好的性能吗?
很多人走到这一步的时候会忽略一个东西,词向量!!!
其实比起分词算法本身的先进程度,在神经网络使用预训练词向量的大背景下,确保分词器与词向量表中的token粒度match其实是更更重要的事情!毕竟哪怕你词分的再好,一旦词向量表里没有的话,那么就变成OOV了,分的再好也木用了。
1. 已知预训练词向量的分词器
一般像word2vec、glove、fasttext这些官方release的预训练词向量都会公布相应训练语料的信息,包括预处理策略如分词等,这种情况真是再好不过了,不用纠结,如果你决定了使用某一份词向量,那么直接使用训练该词向量所使用的分词器叭!此分词器在下游任务的表现十之八九会比其他花里胡哨的分词器好用。
2. 不知道预训练词向量的分词器
这时就需要去“猜”一下分词器了。怎么猜呢?首先,拿到预训练词向量表后,去里面search一些特定词汇比如一些网站、邮箱、成语、人名等,英文里还有n't等,看看训练词向量使用的分词器是把它们分成什么粒度,然后跑几个分词器,看看哪个分词器的粒度跟他最接近就用哪个,如果不放心,就放到下游任务里跑跑看啦。
当然,最理想的情况当然是先确定最适合当前任务数据集的分词器,再使用同分词器产出的预训练词向量啦。可惜互联网上不可能有那么多版本的公开词向量供选择,因此自己在下游任务训练集或者大量同分布无监督语料上训练词向量显然更有利于进一步压榨模型的性能。
当然,除了分词器跟词向量表要match上,另外,还要保证大小写、OOV的定义等跟词向量表match上。如果使用了一个区分了大小写的词向量表,但是你还将下游任务的单词全都小写,那么不用想了,绝对性能丢N多个百分点。
数据集噪声是否严重
这里噪声严重有两种情况。对于数据集D(X, Y),一种是X (train sample)内部噪声很大(比如文本为口语化表述或由广大互联网用户生成),一种是Y (label) 的噪声很大(一些样本被明显的错误标注,一些样本人也很难定义是属于哪一类,甚至具备类别二义性)。
1. X (train sample)内部噪声很大:
一个很自然的想法是去使用语言模型或者基于编辑距离去做文本纠错,然鹅实际中由于专有名词和超出想象的“假噪声”存在,在实际场景中往往效果并不是很好。
这里小夕一般有两种思路,一种是直接将模型的输入变成char-level(中文中就是字的粒度),然后train from scratch(不使用预训练词向量)去跟word-level的对比一下,如果char-level的明显的效果好,那么短时间之内就直接基于char-level去做模型叭~
如果性能差不太多,或者char的已经做到头了,想做一下word-level呢?
一个很work但是貌似没有太多人发现的trick就是使用特殊超参的FastText去训练一份词向量啦。
为什么说特殊呢?一般来说fasttext在英文中的char ngram的窗口大小一般取值3~6,但是在处理中文时,如果我们的目的是为了去除输入中的噪声,那么我们可以把这个窗口限制为1~2,这种小窗口有利于模型去捕获错别字(想象一下,我们打一个错误词的时候,一般都是将其中的一个字达成同音异形的另一个字),比如word2vec学出来的“似乎”的最近词可能是“好像”,然而小ngram窗口fasttext学出来的“似乎”最近词则很有可能是“是乎”等内部包含错别字的词,这样就一下子让不太过分的错别字构成的词们又重新回到了一起,甚至可以一定程度上对抗分词器产生的噪声(把一个词切分成多个字)。当然,如果数据集很干净的话,这样训练词向量的话可能就gg了。
2.Y (label) 的噪声很大
一种很直接的想法是做标签平滑,然而小夕在实战中使用多次发现效果并不是太明显。
最后总结的trick是,首先忽略这个噪声,强行的把模型尽可能好的训出来,然后让训练好的模型去跑训练集和开发集,取出训练集中的错误样本和开发集中那些以很高的置信度做出错误决策的样本(比如以99%的把握把一个标签为0的样本预测为1),然后去做这些bad cases的分析,如果发现错误标注有很强的规律性,则直接撸一个脚本批量纠正一下(只要确保纠正后的标注正确率比纠正前明显高就行)。
如果没有什么规律,但是发现模型高置信度做错的这些样本大部分都是标注错误的话,就直接把这些样本都删掉吧~常常也可以换来性能的小幅提升,毕竟测试集都是人工标注的,困难样本和错标样本不会太多。
Dropout加在哪里
word embedding层后、pooling层后、FC层(全联接层)后,哦了。
关于多标签分类
如果一个样本同时拥有多个标签,甚至标签同时还构成了DAG(有向无环图),不要着急,先用binary-cross-entropy训出个baseline来(即把每个类别变成一个二分类问题,这样N个类别的多标签分类问题就变成了N个二分类问题),毕竟这个都在tensorflow里有现成API了,即tf.nn.sigmoid_cross_entropy_with_logits。因此实现代价很小。
然后你还可能惊喜的发现,这个baseline做好后好像多标签问题不大了,DAG问题自己也基本解决了(虽然模型层并没有专门针对这个问题作处理),然后就可以安心做模型辣。
别太纠结系列
-
别太纠结文本截断长度使用120还是150
-
别太纠结对性能不敏感的超参数带来的开发集性能的微小提升
-
别太纠结未登陆词的embedding是初始化成全0还是随机初始化,别跟PAD共享embedding就行
-
别太纠结优化器用Adam还是MomentumSGD,如果跟SGD的感情还不深,就无脑Adam,最后再用MomentumSGD跑几遍.
QA1 - loss曲线抖动上升是什么原因
深度学习train accuracy曲线抖动上升是什么原因?
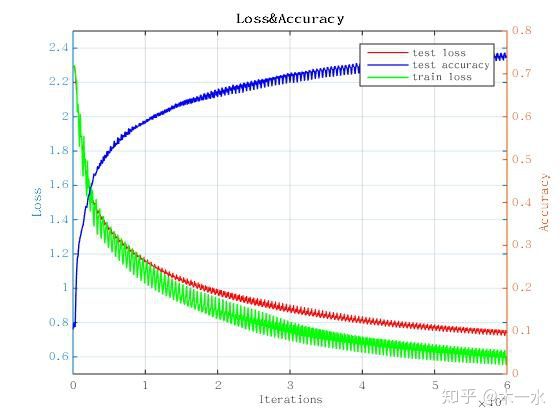
1.直接原因——显示的数据点太多
2. 深入原因——学习率设置、batchsize大小等
- 1)学习率越大,波动越剧烈,学习率越小,波动越平缓。
- 2)batchsize越小,波动越剧烈,batchsize越大,波动越平缓。
3. 根本原因——梯度下降算法
抛开表象看根本,是由于神经网络是高维度的,通过简单的公式求解最优值显然不现实。这时梯度下降算法应运而生了。梯度就是曲线的斜率,如果要最小化目标函数,反向传播过程中,每个参数在梯度方向上减小一定幅度,最终网络收敛到一个局部最优值,减小的幅度大小由学习率决定。
在梯度反向传播过程中,每个patch分别求参数的梯度,最终整个batch的梯度为每个patch梯度之平均,而由于patch之间的差异性,梯度差异较大,因此最终的平均梯度无法精确地匹配每一个patch。下一个batch进来时,由于和第一个batch也存在差异,求平均之后的梯度又偏离了第一个梯度方向,因此损失和精确度的值总是在波动,最终向总体样本的平均梯度靠近。
作者:木一水
链接:https://www.zhihu.com/question/64949637/answer/673388242
QA1 - loss曲线震荡分析
分析原因: 1:训练的batch_size太小
1. 当数据量足够大的时候可以适当的减小batch_size,由于数据量太大,内存不够。但盲目减少会导致无法收敛,batch_size=1时为在线学习。
2. batch的选择,首先决定的是下降方向,如果数据集比较小,则完全可以采用全数据集的形式。这样做的好处有两点,
1)全数据集的方向能够更好的代表样本总体,确定其极值所在。
2)由于不同权重的梯度值差别巨大,因此选取一个全局的学习率很困难。
3. 增大batchsize的好处有三点:
1)内存的利用率提高了,大矩阵乘法的并行化效率提高。
2)跑完一次epoch(全数据集)所需迭代次数减少,对于相同的数据量的处理速度进一步加快。
3)一定范围内,batchsize越大,其确定的下降方向就越准,引起训练震荡越小。
4. 盲目增大的坏处:
1)当数据集太大时,内存撑不住。
2)batchsize增大到一定的程度,其确定的下降方向已经基本不再变化。
总结:
1)batch数太小,而类别又比较多的时候,可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
6)具体的batch size的选取和训练集的样本数目相关
分析原因: 2:数据输入不对
数据输入不对包括数据的格式不是网络模型指定的格式,导致训练的时候网络学习的数据不是想要的; 此时会出现loss曲线震荡;
解决办法: 检查数据输入格式,数据输入的路径;
原文链接:https://blog.csdn.net/yuanlunxi/article/details/79378301