Android的两种数据存储方式分析(二)
二、SQLiteDatabase
做移动应用的人,应该没有人不知道SQLite的吧,但SQLite与其它的关系型数据库有多大区别?Android是怎么使用和操作SQLite的?SQLite的性能怎么样?平时困扰我们的各种数据库异常都是怎么会事儿?有没有什么解决办法?带着这些问题,我们来深入学习一下Android中的SQLite吧!
1、SQLite的优势,Android为什么要选择SQLite
(1)SQLite是一个单进程的数据库(和应用程序运行在一个进程中),不分Server/Client。
(2)所有数据保存在一个文件中(transaction操作过程中会有一些事务记录文件),跨平台。
(3)免安装直接使用。
(4)驱动引擎包很小,500K,去掉一些不常用的功能,可以缩到300K。
(5)资源占用非常少,可以运行在100K内存的设备上。
(6)在读写效率、消耗总量、延迟时间和整体简单性上具有的优越性
(7)完全免费,商用也免费;收费版有加密的功能。
它从设计开始就是为嵌入式设备服务的,所以很适合手机,它不像其它的数据库,启动后会有一个Server的进程,访问时再起一个客户端,通过IPC进行通信。实际上SQLite现在的性能已经很不错了,有不少小的网站也在用它,SQLite的官网上说,它可以支持一天10~30W的访问量。
2、SQLite的数据类型
SQLite支持的数据类型比别的数据库要少很多;SQLite的数据存储是动态数据类型的。
SQLite数据库只支持五种数据类型,基本已经抽象到极高的层次了,而实际上我们只用到4种:

SQlite的五种数据类型
Null这种类型表示一个空值 ;Integer表示数学上的整数;Real表示数学上的小数;Text表示文本,计算机中叫字符串;Blob表示二进制;仔细想想,这几种值的确已经涵盖了平常我们用到的各有种情况。如果真想再抽象,blob可以表示一切啦,计算机里一切都是byte嘛。
再说说SQLite的动态数据类型,或者也可以叫弱数据类型:SQLite定义的表中的每一列是可以存储非指定的类型的数据的,比如我们的表定义如下:

一个Sqlite的表定义
如果我们在Android中使用:
contentValue.put("group_name","group_name");
contentValue.put("group_name", new byte[]{1,2 3});
contentValue.put("group_name", 123);
在做插入或修改操作时,都是可以执行成功的,看起来GROUP_NAME的类型约束TEXT根本就不生效,实际上,我把这那个类型去掉:

无类型定义的表创建语句
SQLite照样能把这个张表创建出来,可见对于SQLite而言,类型根本不是个必要条件,任何一列都可以存不同类型的数据,这也是SQLite区别于其它关系型数据库的一个重要地方。
我们在平时使用时可能也有发现另一种现象,我存入的是一个String="123",但在cursor.getInt()时,竟然真的能得到int = 123,而你在使用cursor.getType(columnIndex)时获取到的对应字段的类型又的确是Text的,太混乱了。
另外,我们也注意到Cursor提供的方法,比如对于整数,它提供了以下方法:
getInt(int columnIndex)
getLong(int columnIndex)
getShort(int columnIndex)
而SQLite只有INTEGER这一种类型呀,这怎么对应起来的呢?
这是不是说,SQLite根本没有数据类型可言?或者SQLite根本就不需要数据类型?
答案是NO,SQLite从来都没有改变他自己定义的数据类型,他内部仍然存储着五种数据类型,他做的仅仅是列内数据动态而已,其它的工作都是Android自己做的,我们来看看Cursor的代码,先看getshort和getInt:(源代码在:CursorWindow.java)
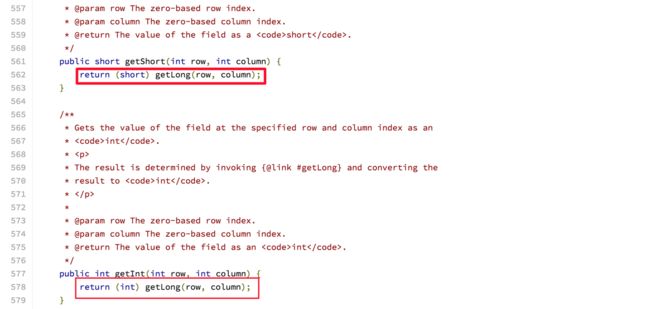
Cursor的getShort和getInt
太暴力了,直接从long转过来,也不必数据丢失。再看同学暴力的getFloat和getDouble:

getFloat

从这里可以看出,SQLite内部的确只存储基本数据类型Integer和Real,对应于Java就是最大字节长度的long和double,而使用时直接强转,风险由RD自己承担,所以我们在写程序时对用哪种get要自己小心,保证你存的是什么类型的数就用什么来取,如果真的担心,那就直接用getLong和getDouble吧,它们不会丢失数据。
好,我们再来看第二个问题,为什么存入一种类型,可以用另一种类型来get,还是直接上个代码,从上面的getDouble代码来看,真正获取数据是用JNI实现的,我们先来看nativeGetDouble:(源代码在:android_database_CursorWindow.cpp)
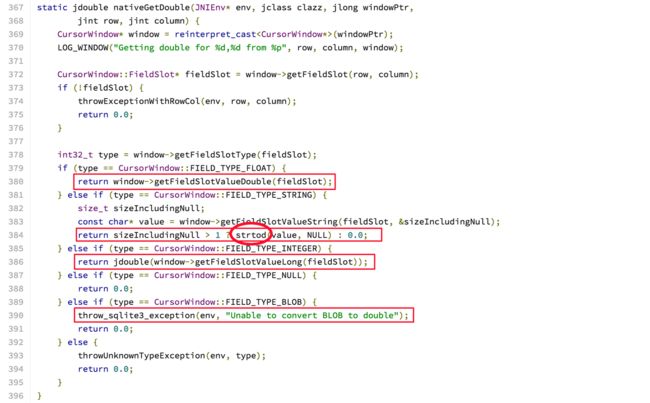
JNI中getDouble
从上面代码可以看出,SQLite内部还是有类型的,只不过Android为了大家使用方便,对每种类型做了转换,如果存的是String,它会用strtod方法转换一下(string to double),这个方法并不是所有string都能转过来的,如果不是一个小数形式的,它会返回0.0的;再看最后一个红框,如果你存入的是blob二进制,它就无能为力啦,给你抛个异常。
getLong和getDouble是类似的,我们再来看看getString的实现:

nativeGetString
注意红框部分,String使用utf16的形式;数向串转换使用的是sprintf;string跟blob类型也是不兼容的,也会出异常。我们再来看看另一个让人疑惑的地方,nativeGetBlog:
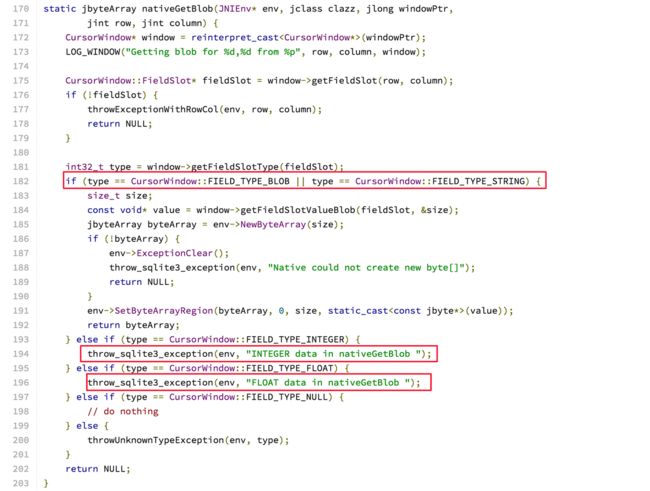
nativeGetBlob
疑惑就是string不兼容blob,但blob可不管你,string它照样按字节数组给读出来,可能blob是更加底层的形态吧;便我们往下面两个红框看,blob又不兼容integer和real。
总结一下吧:
(1)SQLite的内部设计是每一列内都可以存放不同类型的数据,但我们建议大家还是按强类型的关系型数据库来,显式定义列类型,同时列中的确存这种类型的数据,这样可以增加代码的可读性,又能减少潜在和隐藏bug的出现;
(2)尽管cursor的get可以获取一个非它存入的类型,但这个的正确性需要程序员自己来保证,而且一不小心还可能被它抛出异常,所以,建议同上,我们按强类型库的要求来做,存什么就取什么吧。
3、SQLite的线程模式
Sqlite是怎么处理多线程情况的?
实际上,SQLite的引擎对多线程做了处理的,要注意,这是sqlite层做的处理,指的是,打开一个库后,多个线程去处理这个库,而不是多个线程各自去打开这个库。我们看看SQLite是的各种线程模式:

SQLite的线程模式
(1)单线程模式,实际指的是数据库引擎不加锁,如果调用者使用了多线程,那调用都自己来保证同步。这种模式下,数据库内部的操作效率是最高的。
(2)多线程模式,这种模式下,可以多线程操作数据库,但有一个要求,一个DBconnection只能被一个线程使用,这一点也要求调用者自己来保证。
(3)顺序模式,此模式安全性最高,随便操作数据库,当然,效率也最低。
那Android使用的是哪种模式呢,我们看一下代码:(android_database_SQLiteGlobal.cpp)
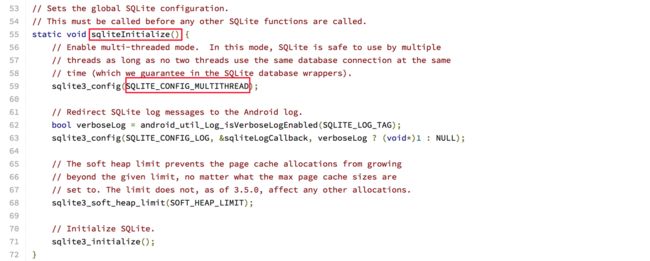
android 6.0上SQLite初始化的代码
从上面代码我们也可以看出,在Android6.0上,使用的是多线程模式。
我们如果注意到SQLiteDatabase的接口,会发现这样一个方法:
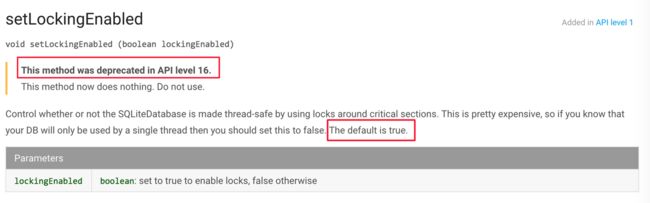
SQLiteDatabase的一lock方法
可以看到,SQLiteDatabase提供了一个锁来控制线程同步,但这个方法在api level 16就不建议用了,这又是为什么呢?我们去看看ApiLevel 16以前的SQLite配置吧。
在jni中找了所有的database*.cpp文件,都没有找到这个配置,再回去看看SQLite配置多线程模式的方法:

SQLite的线程模式配置方法
从这几个配置方法和默认配置方法,我猜测4.0及以前版本的SQLite用的不是默认的serialized模式,因为用这个模式Android就不用自己再加锁了;那它应该用的是编译时设置线程模式,而且是单线程模式。
那Android4.0以上是怎么实现每个connection只被一个线程操作的呢?我们接下来分析Android操作SQLiteDatabase的方法就能发现了。(4.0及以下使用的是锁的方式,我们就不细看了)
4、Android是如何实现操作SQLiteDatabase的
Android操作数据库的流程比较简单,牵扯到的类其实不多,一个简单的图就可以看清楚:
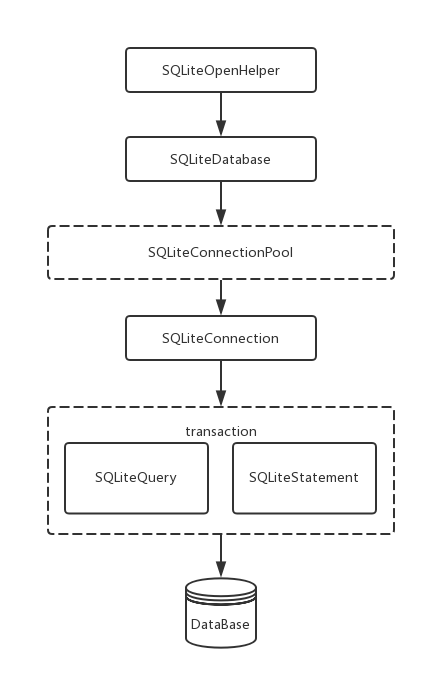
Sqlite操作流程
一句话描述整个流程就是:openHelper打开数据库后,构建DBConnection,使用sqliteQuery和SqliteStatement操作数据库。是不是很简单,但它里面实际上还是有很多其它代码逻辑,我们主要从三个方面分析:openDatabase、session和两个操作方法query+statement。
(1)Open Database
我们在使用db时,先要通过SQLiteOpenHelper获取到SQLiteDatabase,一般获取方法有两种:getReadableDatabase和getWritableDatabase,猛一看,这两个方法还挺有迷惑性,好像一个是得到一个read only的库,一个用于得到一个可写的库,我们看看代码中是这样的吗?
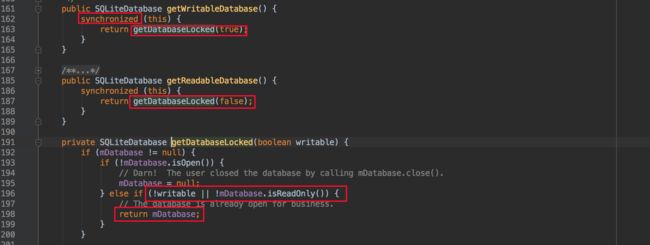
打开SQLiteDatabase
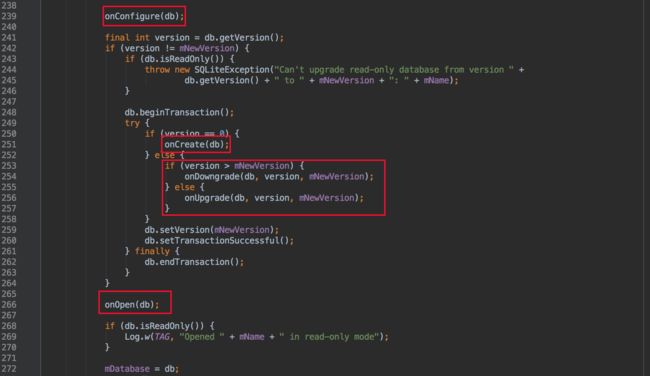
先注意第一个红框,这两个方法都是加了synchronized的,不会因为线程问题创建出两个SQLiteDatabase;第二、三个红框 可以看出,他们都是调用了getDatabaseLocked方法,只是参数不一样,参数表明了打开哪种db;第四个红框里的条件可以发现,只要是非writable,当前缓存的db就可能返回了,或者当前数据是writable的,也可以返回了,所以,获取readable的数据库并不一定返回的是只读的哦,下面还有更吐血的。
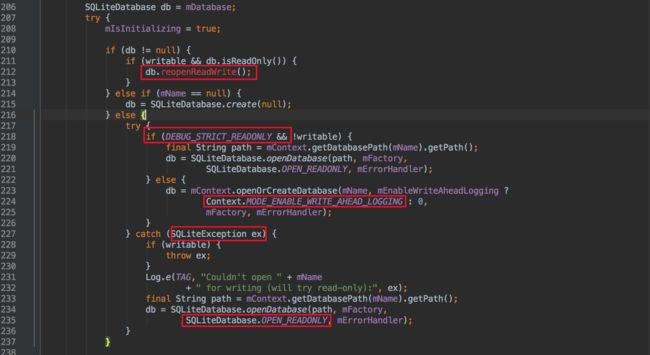
打开Sqlite数据库
第一个红框比较好理解,要打开一个writable的,当前是readOnly的就重新打开一次;看第二个红框,这个值是debug用的,真实环境一直是false,所以这个if是不会走的;看第三个红框,我们发现打开数据库时,根本不管是要readable还是writable,统一打开Writable的,那还要传进来的writable参数干什么呢?再往下看,第五个红框,在打开readable失败时,这时才去判断,如果我们计划打开的是readable的,它才去尝试用readable去打开。
结论:不管getReadableDatabase还是getWritableDatabase,OpenHelper都是优先去打开writable的,对于getReadableDatabase的作用,只是在打开writable失败时(比如磁盘满了),才会用第二案,尝试用readable打开一下。
打开SQLiteDatabase
接下来就比较简单了,同步的把各种on*方法回调走一遍,注意,这里的调用是同步依次调用,不会有什么线程问题的。
(2)SQLiteSession
SQLiteDatabase在操作数据库时,都要获取到一个session后才能开始操作,从session这个单词我们看以看出,它就像一个client一样。
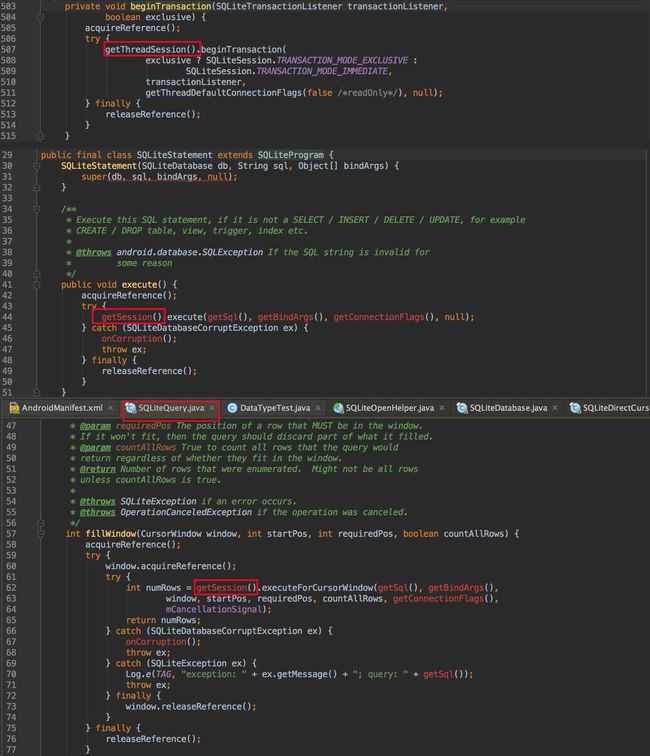
transaction,query,statement都是要先获取一个session
从这几个方法可以看出,数据库的操作都是要先获取到session才可以操作,我们看看session定义的地方。

SQLiteDatabase中的SQLiteSession
我们可以看到,Session是用threadLocal保存的,SQLiteDatabase正是通过ThreadLocal来保证了每个线程拿到的Session唯一,线程结束了,它也就被释放了。每个session中有一个dbconnection,此时,andriod已经做到了每个connection只属于一个线程,符合SQLite线程模式Multi-Thread的要求。
SQLiteSession的类注释写了好多内容,对我们理解数据库操作非常有帮助,(我使用Google翻译了一下,翻译的很难懂,还是直接看英文看的更加明白):

sqliteSession说明
database只能用session访问数据库;多个readonly操作可以并行执行,写操作只能串行;session不是线程安全的,DB通过ThreadLocal来保证安全;多线程同时操作connection,有可能造成死锁。
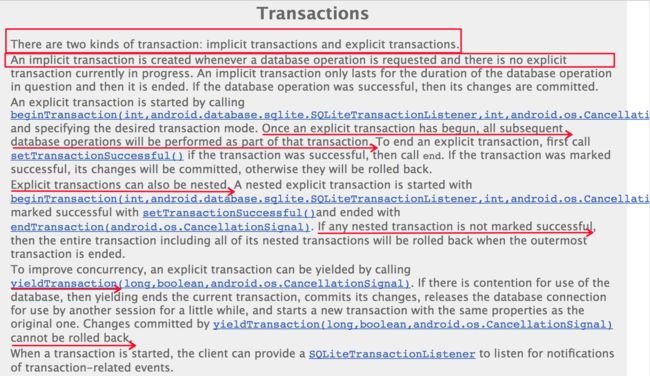
sqliteSession说明
transaction有两种,隐式和显式;平时的任何直接操作都会起一个隐式的;只有调用beginTransaction,才发起一个显式的transaction;transaction是可以嵌套的,嵌套内的任何一个没有succesfull,最外层的都会回滚;如果一个transaction执行时间太长,可以通过yieldTransaction来让出一段时间数据库操作,但让出这前的提交内容会被commit,且不会回滚(比较鸡肋)。
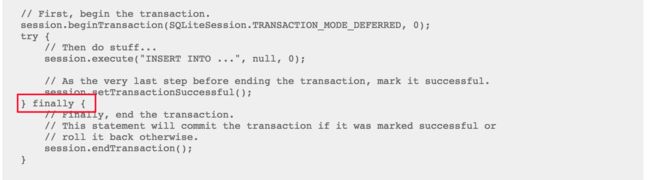
显示transaction用法
显式的transaction必须这样用,try + finaly,像lock的用法一样,否则会再现死锁的情况。

connection和responsiveness
一个数据库的connection是有限的,多线程并发比较高时,一些sessoin在获取connection是要等待的;Android做了一个connection的pool来提高效率,实际上这个pool的max size很小的(系统配置),也就2~5个的样子;
为了提升数据库操作响应速度,一定要减少transaction执行时间,特别是writable的,它们要串行执行;为增加响应速度和流畅性,有几个需要注意的点:
[1]不要在主线程操作数据库;
[2]保持transaction时间尽可能短;
[3]简单的查询条件要比复杂查询条件的速度快的多;
[4]表内数据量的大小是非常影响查询速度的,100行的表跟10000行的表完全不是一个速度级的。
(3)关于query和statement就不细讲了,我们只要理解两点:
[1]所有的query操作,包括rawQuery,最终都是组成一个SQLiteQuery对象来执行;
[2]所有的增、删、改操作,包括executeSQL,最终都是组成一个SQLiteStatement对象来执行;
具体代码大家可以从SQLiteDatabase中相关方法跟下去看看:
https://android.googlesource.com/platform/frameworks/base/+/android-6.0.1_r77/core/java/android/database/sqlite/
5、SQLite的读写性能和内存占用情况
先说读写性能,我自己做的测试,一般的手机
query100条以内:1ms
query500条以内:<10ms
query1000条:>10ms
插件操作:
Insert一条记录:20ms
从上面的数据可以看出,正常情况下查询少量数据是非常快的,这里说的是正常情况,所以,如果我们只是查很少量的数据,有时可以放在主线程操作,但是不建议,个别手机上还是有可能anr;
修改操作很快,必须放在工作线程完成。
关于内存占用情况,我测试打开一个库,建立一个connection,正常情况下一个connection会占用2K左右的内存,而库的主要内存就在这里,看connectionPool的大小了。
所以,对于数据库内存方面的建议是:如果这个库要经常操作,可以不用关,占用内容并不多,因为再打开一次开销还是挺大的(50~100ms);如果不常用的数据库,还是及时关闭吧。
6、开发中如何正确的使用SQLite
关于使用数据库的建议:
(1)保证sqliteOpenHelper单例,或者全局唯一,不要让一个库在一个进程中同时存在多个OpenHelper;
(2)不要在多个进程中操作同一个库,如果有多进程的情况,使用contentProvider来操作库吧,各进程都通过contentProvider来获取数据;
(3)数据库是否需要关闭根据业务情况来,它占用的内存其实不多。