【消息中间件-Kafka】原理介绍及相关配置优化和JMX监控性能指标
kafka特点:高性能,持久化,多副本,横向扩展能力
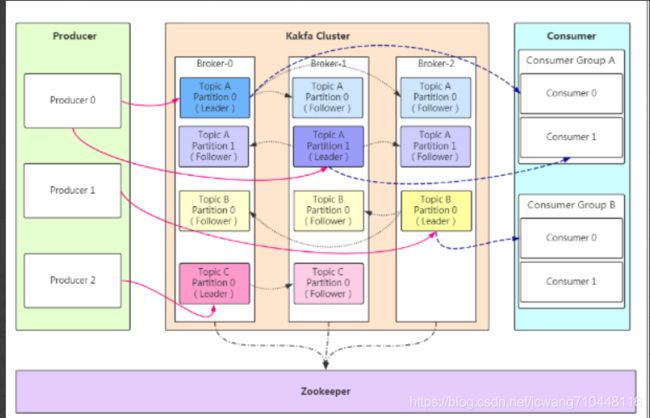
一.名词理解
producer和consumer:生产者,消费者就不多说了
1.kafka cluster:kafka集群簇
2.Broker:消息中间件处理节点,一个kafka节点就是一个broker,每个服务器上有一个或多个kafka的节点,多个broker组成一个kafka集群(不同的broker之间,可以联系)
3.Topic:消息主题,kafka根据topic对消息进行分类,发布到kafka集群的每条消息都要指定一个Topic
4.Partition:Topic的分区,每个topic可以有多个partition分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹
5.Leader:主分区,如上图,生产者优先把消息存储到相应topic的主分区下
6.Follower:副本分区
7.Zookeeper:分布式协调系统
二.为什么kafka做分区
1、方便扩展。因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
2、提高并发。以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
三.如何保证producer向kafka写入消息的时候,怎么保证消息不丢失

1.通过ACK应答机制。在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、-1
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
-1代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
四.partition结构
Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息
4.1. Message结构:包含消息体,消息大小,offest,压缩类型等,重点3个:
1.offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
2.消息大小:消息大小占用4byte,用于描述消息的大小。
3.消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样
五.存储策略
无论消息是否被消费,kafka都会保存所有的消息。那对于旧数据有什么删除策略呢?
1、 基于时间,默认配置是168小时(7天)。
2、 基于大小,默认配置是1073741824。
需要注意的是,kafka读取特定消息的时间复杂度是O(1),所以这里删除过期的文件并不会提高kafka的性能!
六。消费数据
1.消息存储在log文件后,消费者就可以进行消费了。Kafka采用的是点对点的模式,消费者主动的去kafka集群拉取消息,与producer相同的是,消费者在拉取消息的时候也是找leader去拉取。
2.多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id!同一个消费组者的消费者可以消费同一topic下不同分区的数据,但是不会组内多个消费者消费同一分区的数据

七。后台配置优化(/data/kafka/config/)
1.配置文件server.properties
# broker处理消息的最大线程数
num.network.threads=3 (建议cpu核数加1.)
# broker处理磁盘IO的线程数
num.io.threads=8 (建议cpu核数2倍)
#日志保留默认168小时=7天,建议3天即可
log.retention.hours=168
#单个segment文件大小,默认1G=1073741824byte
log.segment.bytes=1073741824
#间隔多久检查一次segment文件
log.retention.check.interval.ms=300000
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
#日志路径及是否可以清空日志(true,符合条件即清理)
log.dirs=/data/kafka/logs
delete.topic.enable=true
#节点id及分区数量
num.partitions=1
broker.id=0
八.使用JMX监控kafka性能
1.在./kafka/bin/kafka-run-class.sh里,加入JMX_PORT=9999 (每个broker都需要加)
2.重启kafka集群(可以先kill,然后启动,启动要加参数:./kafka-server-start.sh -daemon /data/kafka/config/server.properties)
3.在本地cmd中执行jconsole.exe(没配置环境变量的,去相应目录下手动运行)
4.登录时注意端口号,是上面“JMX_PORT=9999”的端口号,9999;在Mbean下查看kafka指标信息

5.重点监控指标:
消息入站速率(消息数)
kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec
消息入站速率(Byte)
kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec
消息出站速率(Byte)
kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec
Leader副本数
kafka.server:type=ReplicaManager,name=LeaderCount
Partition数量
kafka.server:type=ReplicaManager,name=PartitionCount
同步失效的副本数
kafka.server:type=ReplicaManager, name=UnderReplicatedPartitions
解释:这个UnderReplicatedPartitions是一个Broker级别的指标,指的是leader副本在当前Broker上且具有失效副本的分区的个数,也就是说这个指标可以让我们感知失效副本的存在以及波及的分区数量。这一类分区也就是文中篇头所说的同步失效分区,即under-replicated分区。
如果集群中存在Broker的UnderReplicatedPartitions频繁变动,或者处于一个稳定的大于0的值(这里特指没有Broker下线的情况)时,一般暗示着集群出现了性能问题