Redis源码阅读【番外篇-Redis的多线程】
Redis源码阅读【1-简单动态字符串】
Redis源码阅读【2-跳跃表】
Redis源码阅读【3-Redis编译与GDB调试】
Redis源码阅读【4-压缩列表】
Redis源码阅读【5-字典】
Redis源码阅读【6-整数集合】
Redis源码阅读【7-quicklist】
Redis源码阅读【8-命令处理生命周期-1】
Redis源码阅读【8-命令处理生命周期-2】
Redis源码阅读【8-命令处理生命周期-3】
Redis源码阅读【8-命令处理生命周期-4】
Redis源码阅读【番外篇-Redis的多线程】
Redis源码阅读【9-持久化】
建议搭配源码阅读:源码地址
文章目录
- 1、前言
- 2、为什么使用多线程
-
- 2.1、单线程的瓶颈
- 2.2、如何使用多线程
- 3、多线程初始化
-
- 3.1、IO线程运行初始化&NUMA陷阱(绑核)
- 3.2、Redis的自动IO线程调整
- 4、总结
1、前言
由于做完前面的章节发现还是有遗漏的地方,其中Redis的多线程就是一个遗漏的知识点。在前面的《命令处理生命周期-3》文章中,在Redis服务端初始化的过程就有提到,Redis存在多线程初始化的情况,并且当时有在图片中标记,但是由于担心知识点增加导致文章内容扩散,所以当时并没有展开来讲,那么我们现在先回顾一下当时的图片内容:

在这张图片中,我使用【红色的箭头】和【红色的字体】分别标记出涉及多线程的【环节】和【方法】,从Redis6开始Redis开始支持多线程模式了,默认是关闭的,可以通过配置redis.conf的io-threads-do-reads 线程数量 和 io-threads yes 来开启多线程或者修改多线程数量。那么我们为什么要了解Redis多线程模式呢?很大的一个程度就是为了了解多线程下的Redis设计思路,以及Redis多线程是为了解决什么问题,同时也能让大家更加了解使用多线程的技巧,下面就开始主题内容吧。
2、为什么使用多线程
2.1、单线程的瓶颈
首先我们回归一下问题:Redis为什么使用多线程?,带着问题去看代码可以起到事半功倍的效果。在Redis之前的版本中,基本上都是以单线程的方式运行着从用户请求-解析命令-命令执行-响应用户,在单线程下【无需线程切换】以及【不需要锁】,单线程的确是能发挥高效率的特性,但是随着企业应用的并发量进一步的提升,单线程也出现了瓶颈,其中最大的瓶颈就是来源于网络I/O,如下图所示:

在之前版本的Redis中,从I/O输入->解析命令->执行命令->响应I/O都是在一个线程底下执行的,由于使用了多路复用的技术,单线程需要处理众多的网络IO。此外命令执行等操作都是基于内存进行的,所以速度是非常快的,那么这个时候网络I/O就成了Redis最大的性能瓶颈,尤其是当一个Redis服务同时维护着大量的连接的时候 (这里的client对应前面文章提到了client实体)。
2.2、如何使用多线程
在Redis6为了更好的配合多线程的优势,利用上了 client 的两个缓冲区,分别就是前面文章《8-命令处理生命周期-1》中提到的输入缓冲区 querybuf 和输出缓冲区buf,多线程将socket的数据包放入缓冲区中并对命令进行校验解析,由readQueryFromClient函数处理。其流程 参考 《8-命令处理生命周期-4》
整体的调用逻辑基本如下:

这里需要注意,我发现网络上有很多文档都是在写,IOThread会自行将数据直接写入client的querybuf中,其实还是有点区别,与常用的 java 多线程编程不同的是,这里其实是有一个玄机的,主线程能协调多个IO线程同一时间在做同一种事情 (读/写),大家看一下后面的内容就明白了,话不多说,先列出代码:
//aeMain的核心执行函数
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
//........................前面有一堆代码.........................
//获取触发的读文件事件
numevents = aeApiPoll(eventLoop, tvp);
//遍历事件
for (j = 0; j < numevents; j++) {
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
//.....................省略....................................
//如果是读文件事件(上面还有一个写事件)
if (invert) {
fe = &eventLoop->events[fd]; /* Refresh in case of resize. */
if ((fe->mask & mask & AE_READABLE) &&
(!fired || fe->wfileProc != fe->rfileProc))
{
//调用rfileProc(是指针)处理读事件,对应的函数是 acceptTcpHandler
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
fired++;
}
}
//............................后面还有很多代码...........................
}
//处理TCP连接函数
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
..................省略......................
//为了防止处理时间过长每次只处理1000个连接请求
while (max--) {
//获取socket文件描述符
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
//..................省略......................
//进一步处理读事件(创建client)
acceptCommonHandler(connCreateAcceptedSocket(cfd), 0, cip);
}
}
//进一步处理读事件(创建client)
static void acceptCommonHandler(connection *conn, int flags, char *ip) {
//.................省略......................
//判断是否达到服务器最大连接数量
if (listLength(server.clients) >= server.maxclients) {
//.................省略......................
return;
}
//创建 client
if ((c = createClient(conn)) == NULL) {
//.................省略......................
return;
}
//.................省略......................
}
//创建client
client *createClient(connection *conn) {
if (conn) {
//这里会将client放入 clients_pending_read
connSetReadHandler(conn, readQueryFromClient);
//主线程将创建的client放入 connection 的 private_data
connSetPrivateData(conn, c);
}
}
//从client 读取数据
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
//检查我们是否想要稍后退出时从客户端读取事件循环。如果启用了线程I/O,就会出现这种情况。
if (postponeClientRead(c)) return;
//.............后面还有很多代码..............
}
/* 如果我们想处理后面使用线程I/O读取的客户端,返回1。
* 这是由事件循环的可读处理程序调用的。
* 调用此函数的副作用是将客户端放在【挂起读客户端列表】并标记*/
int postponeClientRead(client *c) {
if (io_threads_active && // 多线程 IO 是否在开启状态,在待处理请求较少时会停止 IO多线程
server.io_threads_do_reads && // 读是否开启多线程 IO (配置文件配置)
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER | CLIENT_SLAVE | CLIENT_PENDING_READ))) {
// 主从库复制请求不使用多线程 IO
// 连接标识为 CLIENT_PENDING_READ 来控制不会反复被加队列,在下次的时候会直接进入到命令读取和解析
c->flags |= CLIENT_PENDING_READ;
// 连接加入到等待读处理队列
listAddNodeHead(server.clients_pending_read, c);
return 1;
} else {
return 0;
}
}
/**
* 当还为读+解析端启用了线程I/O时,可读的处理程序将把普通客户端放入要处理的客户端队列中(而不是同步地为它们提供服务)。
* 该函数使用I/O线程运行队列,并对其进行处理,以便在缓冲区中累积读操作,同时还解析第一个在客户机结构中呈现该队列的可用命令。
*
*/
int handleClientsWithPendingReadsUsingThreads(void) {
//............................前面有一堆代码................................
// 将等待处理队列的连接按照 RR 的方式分配给多个 IO 线程
listRewind(server.clients_pending_read, &li);
int item_id = 0;
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id], c);
item_id++;
}
//将当前线程设置为读(io_threads_op 是一个全局开关)
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
io_threads_pending[j] = count;
}
//当然主线程也不能闲着,也要一起来处理读客户端
listRewind(io_threads_list[0], &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
//这里是真实的处理逻辑
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 一直忙等待直到所有的连接请求都被 IO 线程处理完
while (1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += io_threads_pending[j];
if (pending == 0) break;
}
//..................................后面还有一堆代码.........................
}
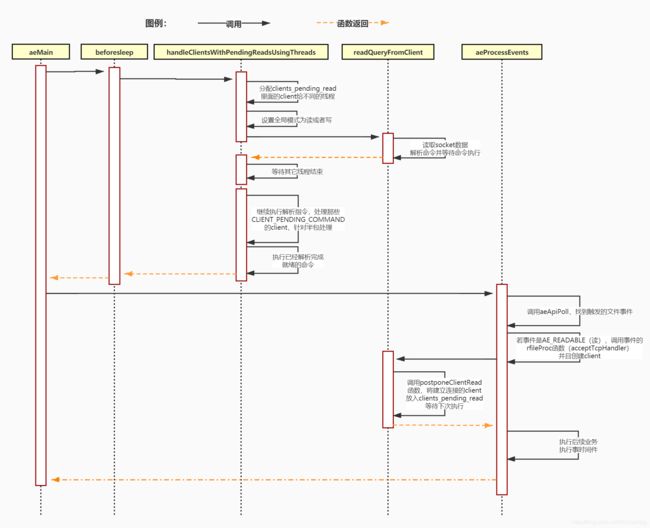
乍一看感觉内容很多有点而且懵逼,其实整个过程可以总结为如下两个过程,分别为,主线程流程 和 IO线程流程这里我们主要以 读 为例子(写比读简单且过程类似):
主线程流程:
-
1、 主线程处理读事件(文件事件),通过
aeApiPoll找到被触发的事件(可以看文章《8-命令处理生命周期-2》中的文件事件处理),通过调用读事件中的rfileProc(指针对应函数acceptTcpHandler),完成client的创建(createClient),并放入clients_pending_read等待队列中(通过调用readQueryFromClient完成); -
2、 主线程分配 等待队列
clients_pending_read中的 client 给不同的IO线程(包括自己),通过item_id % server.io_threads_num的方式分配到io_threads_list数组中,item_id是当前等待队列元素的索引值,server.io_threads_num是当前线程的数量,全部 client 分配到不同的线程对应的io_threads_list后等待下一步执行(这里io_threads_list是一个list数组,其中io_threads_list的索引值是线程的编号,0号留给主线程); -
3、 主线程设置全局
io_threads_op为IO_THREADS_OP_READ读或者;IO_THREADS_OP_WRITE写,io_threads_op是一个开关,用来控制切换当前所有IO线程,是 读 模式还是 写 模式; -
4、 在
io_threads_op的控制下,所有线程 (包括主线程) 一起同时处理分配给自己的client (在io_threads_list中通过io_threads_list[线程号]获取自己已经分配到的client链表),进行 读业务 或者 写业务,读业务主要是 socket数据包读取,RESP协议解析,命令解析 等内容(这里就提现了多线程的协同也是Redis使用多线程提高效率的一个点); -
5、 若主线提前程执行完后,需要等待其它IO线程执行结束;
-
6、 再次执行 数据包读取,RESP协议解析以及命令解析等流程,这次的主要目的是针对那些缓冲区还有数据的client,一般都是发生了半包的 client 需要读取完整的数据,再次执行尝试看看是否能够解析出完整的命令;
-
7、 执行已经解析完成并且放入client
cmd中的命令(redisCommand对象) (主线程执行,不涉及IO线程,这块内容可以参考《8-命令处理生命周期-4》); -
8、 进行后续的业务,然后进行下一次轮回;
-
这里有个地方要注意: 主线程和IO线程都执行了
processInputBuffer函数,但是为什么IO线程不会再执行命令呢?主要是processInputBuffer里面的段代码:
/* If we are in the context of an I/O thread, we can't really
* execute the command here. All we can do is to flag the client
* as one that needs to process the command. */
//如果我们在I/O线程的上下文中,我们就不能真正执行这个命令。我们所能做的就是将客户端标记为需要处理该命令的客户端。
if (c->flags & CLIENT_PENDING_READ) {
c->flags |= CLIENT_PENDING_COMMAND;
break;
}
IO线程流程:
- 1、 读取
io_threads_list中已经被主线程分配到的client ,准备进行迭代遍历; - 2、 判断当前的
io_threads_op的全局状态是IO_THREADS_OP_READ读模式,还是IO_THREADS_OP_WRITE写模式; - 3、 如果是 读 调用
readQueryFromClient,如果是 写 调用writeToClient; - 4、 如果是 读 ,执行socket数据包读取,以及解析RESP协议命令解析等内容,解析完成后IO线程不再执行命令,直接返回等待主线程去执行;
- 5、 进入下一次轮回;
通过上面的流程我们可以发现:首先readQueryFromClient是主线程和IO线程都会执行的函数,但是由于主线程有时候会执行到readQueryFromClient底下的postponeClientRead方法后就返回结束了。其次acceptTcpHandler,handleClientsWithPendingWritesUsingThreads 和 handleClientsWithPendingReadsUsingThreads这几个函数是只有主线程才会执行的。主线程是在handleClientsWithPendingReadsUsingThreads中调用readQueryFromClient的。最后主线程和IO线程的协调关系其实可以用下图表示:
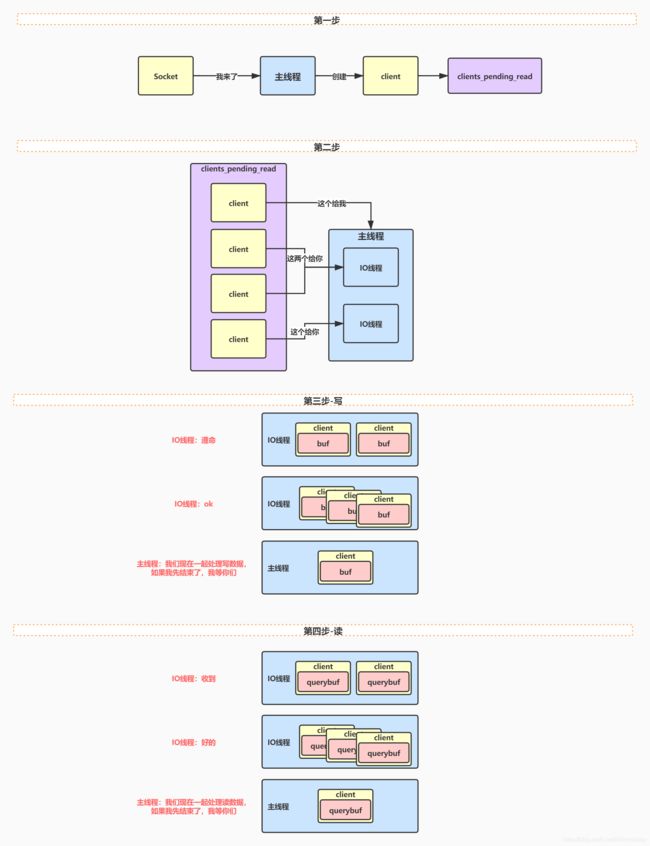
其转换为时序图如下图所示
主线程:
IO线程:

3、多线程初始化
在介绍完前面的多线程特点以及其执行方式之后,我们下面来介绍一下线程的生命周期是怎么样的。首先主线程的初始化基本上就是程序main方法的执行,可以参考前面的文章《8-命令处理生命周期-3》服务端的初始化流程:
在服务端初始化调用initServer后,还调用了一个叫做InitServerLast 的方法其中这段代码是2019年9月份加上去的,刚好就是Redis推出多线程模式前一段时间

在InitServerLast执行了一个叫做initThreadedIO的方法,其代码如下所示:
//初始化线程I/O所需的数据结构。
void initThreadedIO(void) {
io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
//如果用户只设置了一个线程,不要创建任何线程:我们将直接使用主线程处理I/O。
if (server.io_threads_num == 1) return;
//判断是否超过最大线程数量 128
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING, "Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
//循环生成线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
//用于存储主线程分配client的io_threads_list数组,其结构为list
io_threads_list[i] = listCreate();
//注意这里判断了i != 0 因为 0要留给主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
//初始化线程互斥锁锁 mutex
pthread_mutex_init(&io_threads_mutex[i], NULL);
io_threads_pending[i] = 0;
//这里将会把IO线程使用互斥锁阻塞住,等待startThreadedIO执行的时候释放锁
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
//创建IO线程,线程执行的方法是IOThreadMain(相当于Runnable)
if (pthread_create(&tid, NULL, IOThreadMain, (void *) (long) i) != 0) {
serverLog(LL_WARNING, "Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}
上述代码主要是由主线程执行。server.io_threads_num是用来控制服务端线程数量的,Redis服务端允许创建的最大IO线程数量是128,然后在循环中逐个创建IO线程。此外还初始化mutex互斥锁并对IO线程进行阻塞,且放入pthread_mutex_lock数组中,其中数组的索引是线程的编号,这里pthread_mutex_lock里面的锁有点像CountDownLatch的作用,用来控制线程的等待和运行,当主线程初始化完成后会调用startThreadedIO让IO线程开始运作。最后通过pthread_create创建真实的线程并传如IOThreadMain(IOThreadMain有点像Runnable)。
IOThreadMain是IO线程运行的主要代码,其实现代码如下所示:
//IO线程运行的Main方法,myid是当前IO线程的编号
void *IOThreadMain(void *myid) {
/* The ID is the thread number (from 0 to server.iothreads_num-1), and is
* used by the thread to just manipulate a single sub-array of clients. */
long id = (unsigned long) myid;
char thdname[16];
snprintf(thdname, sizeof(thdname), "io_thd_%ld", id);
redis_set_thread_title(thdname);
//绑定CPU和线程的关系,让一个线程始终由一个线程处理 避免NUMA陷阱
redisSetCpuAffinity(server.server_cpulist);
while (1) {
/* Wait for start */
//等待该线程启动
// 这里的等待,没有使用简单的 sleep,避免了 sleep 时间设置不当可能导致糟糕的性能
for (int j = 0; j < 1000000; j++) {
if (io_threads_pending[id] != 0) break;
}
/* Give the main thread a chance to stop this thread. */
//当线程没有任务运行的时候。通过pthread_mutex_lock上锁给主线程机会去停止这个线程
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
serverAssert(io_threads_pending[id] != 0);
if (tio_debug) printf("[%ld] %d to handle\n", id, (int) listLength(io_threads_list[id]));
/* Process: note that the main thread will never touch our list
* before we drop the pending count to 0. */
listIter li;
listNode *ln;
// 遍历线程 id 获取线程对应的待处理连接列表
listRewind(io_threads_list[id], &li);
while ((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 通过 io_threads_op 控制线程要处理的是读还是写请求
if (io_threads_op == IO_THREADS_OP_WRITE) {
writeToClient(c, 0);
} else if (io_threads_op == IO_THREADS_OP_READ) {
readQueryFromClient(c->conn);
} else {
serverPanic("io_threads_op value is unknown");
}
}
listEmpty(io_threads_list[id]);
io_threads_pending[id] = 0;
if (tio_debug) printf("[%ld] Done\n", id);
}
}
3.1、IO线程运行初始化&NUMA陷阱(绑核)
在IOThreadMain中如果是第一次运行,首先会通过redisSetCpuAffinity尽可能的绑定CPU和线程的关系,为什么要绑定关系呢?
首先服务器和家用电脑是不一样的,服务器的核心数量可能达到50甚至以上,由于核心的增加,但是类似于总线等硬件并没有变化,当核心继续增加的时候可能总线等硬件扛不住了?那么硬件设计者,为了硬件设备横向拓展性,可能会对总线或者一些原本可以共享的硬件设施进行横向扩展或者引入新的结构技术(例如QPI技术),可以不准确的理解为服务器表面上是一台物理机,但是在硬件结构上面又类似于多台电脑的模式,每个CPU有自己最贴近的贴身内存,CPU对这个内存的访问效率或者速度是大于同属于其它CPU的内存,在这种模式下的多线程程序会,其效果就好像一个任务总是在不同的电脑中运行,表现情况可能是发现电脑内存还足够使用,但是程序却使用了swap,这样的带价是很高的,通过绑定CPU和线程的亲和性,可以避免这种情况。可以参考这篇文章《NUMA的原理与局限》
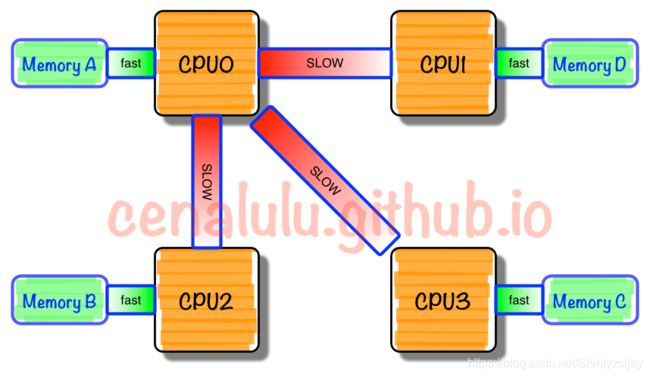
在核心绑定完成后IO线程会先进行一个大约 1000000次 的 自旋循环 等待(我理解为加载等待)。这里可能会问,为什么不使用sleep呢?没有使用简单的 sleep,是为了避免了 sleep 时间设置不当可能导致糟糕的性能,但是也有个问题就是频繁 自旋 可能一定程度上造成 cpu 较长占用。(不过程序还没启动,消耗些CPU其实也没什么)在循环中如果判断自己的io_threads_pending不为0(线程编号作为索引),证明刚刚启动线程就分配到了工作,那么IO线程无需继续等待,直接运行任务(即判断读写调用writeToClient或readQueryFromClient),就这样整个IO线程就在一个while循环中一直执行下去。
3.2、Redis的自动IO线程调整
此外还有一快代码需要注意:
/* Give the main thread a chance to stop this thread. */
//给主线程有机会停止这个IO线程
//当线程没有任务运行的时候。通过pthread_mutex_lock上锁给主线程机会去停止这个线程
if (io_threads_pending[id] == 0) {
pthread_mutex_lock(&io_threads_mutex[id]);
pthread_mutex_unlock(&io_threads_mutex[id]);
continue;
}
在IOThreadMain循环中每次都会进行上面的判断,通过判断当前线程的io_threads_pending是否为0,如果为0那么当前的IO线程会被mutex锁给锁住,主线程会根据当前的运行情况判断是否需要那么多IO线程,来判断是否需要停止全部IO线程变成单线程模式,通过在时间事件里面调用serverCron来判断是否需要停止,调用关系:serverCron -> stopThreadedIOIfNeeded -> stopThreadedIO,判断条件如下:
int stopThreadedIOIfNeeded(void) {
int pending = listLength(server.clients_pending_write);
/* Return ASAP if IO threads are disabled (single threaded mode). */
//只有主线程,之间返回
if (server.io_threads_num == 1) return 1;
if (pending < (server.io_threads_num * 2)) {
if (io_threads_active) stopThreadedIO();
return 1;
} else {
return 0;
}
}
void stopThreadedIO(void) {
/* We may have still clients with pending reads when this function
* is called: handle them before stopping the threads. */
//当调用这个函数时,我们可能仍然有一些具有挂起读的客户机:在停止线程之前处理它们。
handleClientsWithPendingReadsUsingThreads();
//遍历
for (int j = 1; j < server.io_threads_num; j++)
pthread_mutex_lock(&io_threads_mutex[j]);
io_threads_active = 0;
}
基本上的意思是,判断当前需要 写 client的数量(clients_pending_write的数量)是否小于当前运行着线程的2倍,如果是在执行完成本轮的读后,会直接停止IO线程变成单线程模式。为什么这么做呢?Redis使用多线程的主要目的是为了处理挂起等待的client,但是如果每次需要处理挂起等待的client太少还不如使用单线程,多线程毕竟是有开销的(如果只有两个线程岂不是永远不会生效呢?)。
4、总结
在本章节中我们主要介绍了Redis多线程模式的运行机制和特点,同时也表明了为什么Redis会无奈妥协使用多线程,但是在代码中发现作者还是很不情愿的使用多线程,从各种对多线程的限制中就能发现,但是没办法谁让Redis的瓶颈在IO呢,不过这里也侧面显示出了一点,Redis为了维护单线程运行模式的决心,但是不得不说这次Redis加上的多线程代码确实有点糟糕,各种锚点和跳转,感觉作者并没有太多改进的打算。只是为了突破瓶颈而做的功能,所以现在其实还是可以总结出单线程的一些优势:
- 1、无需考虑线程切换带来的性能开销
- 2、无锁化,不用考虑变量线程之间的可见性以及并发问题(无锁就是快)
- 3、在大型服务器下,多线程会受到QPI等技术的制约,而单线程却没有
- 4、能够保证同一个client乃至client与client之间命令执行的顺序性