本赛道分初赛、复赛、决赛三个阶段,每个阶段的任务为基于图片的行人重识别:即给定一张含有某个行人的查询图片,行人重识别算法需要在行人图像库中查找并返回特定数量的含有该行人的图片。比赛将使用首位准确率(Rank-1 Accuracy)和mAP(mean Average Precision)作为客观性能指标。
预训练模型要求
不允许使用任何含有行人图像/行人身体部件的外部数据集,或外部数据集上的预训练模型.
只允许使用在 ImageNet 数据上训练的标准图像分类模型,用于辅助 ReID 模型初始化.
不允许选手在 ImageNet 图像数据上自行训练深度模型。
不允许选手对大赛数据集进行额外标注
初赛数据集
训练集中含有 4,768 个行人,20,429 张图片,每张图片提供 ID 标签,可以用于模型训练
测试集包含 6,714 张
复赛数据集
训练集含有 9,968 个行人,85,729 张 png 格式图片,提供 ID 标签,可以用于模型训练
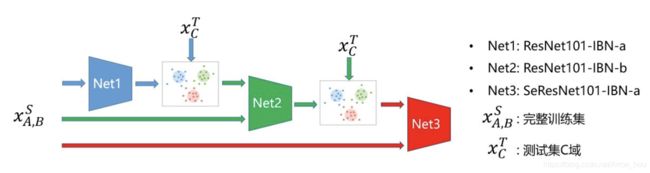
挖掘的时候, 并没有采用传统意义上的无监督挖掘,而是进行一个半监督挖掘. 无监督挖掘例如DBSCAN会根据feature之间距离的远近自动生成聚类的 cluster center, 聚类的数量和实际结果不一致.而[1]使用Query作为中心预先决定了cluster center, 之后再聚类, 效果肯定要优于无监督挖掘. 这个其实已经不是聚类了, 直观来讲就是一个排序.
决赛方案暂且略过.
anxiangsir/NAIC_reid_challenge_rank14_rank25
线下使用4折交叉验证
使用 RandomPatch
方差反转
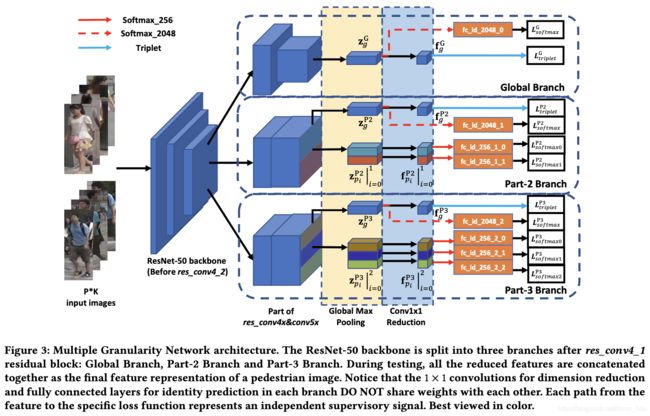
魔改MGN
图片尺寸增加, 配合MGN
haoni0812/person-reid-2019-NAIC
使用了A-softmax-loss
魔改MGN
平衡同一图片ID数量
maliho0803/NAIC_reid_challenge
使用 rank loss
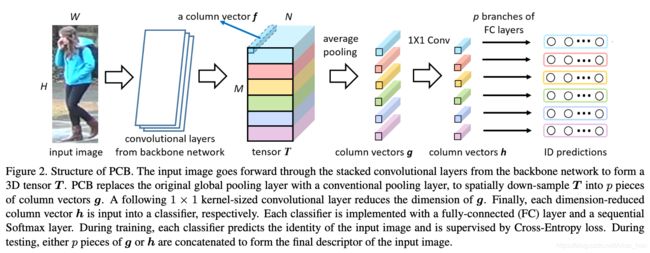
MGN + PCB
随机crop
bochuanwu/NAIC_Person_Reid
rank loss
修改 rank loss 为 聚类 loss
OSMLoss, 加权对比损失函数
backbone 使用 Pyramidal[10] , 一个更为复杂的part feature model
增加了attention机制 DANet[11], 和ABD-net[12]思路一样.
lxyICT/ReID-json-rel
Reference
[1]: 罗浩团队分享 https://zhuanlan.zhihu.com/p/109920765 [2]: Self-similarity Grouping A Simple Unsupervised Cross Domain Adaptation Approach for Person Re-identification [3]: Beyond Part Models: Person Retrievalwith Refined Part Pooling(and A Strong Convolutional Baseline) [4]: Learning Discriminative Features with Multiple Granularities for Person Re-Identification [5]: Bag of Tricks and A Strong Baseline for Deep Person Re-identification [6]: ArcFace: Additive Angular Margin Loss for Deep Face Recognition [7]: Ranked List Loss for Deep Metric Learning [8]:Re-ranking Person Re-identification with k-reciprocal Encoding [9]:Deep Metric Learning by Online Soft Mining and Class-Aware Attention [10]:Pyramidal Person Re-IDentification via Multi-Loss Dynamic Training [11]:Dual Attention Network for Scene Segmentation [12]:ABD-Net: Attentive but Diverse Person Re-Identification [13]: Bag of Tricks and A Strong Baseline for Deep Person Re-identification
public class HttpClientUtils
{
public static CloseableHttpClient createSSLClientDefault(CookieStore cookies){
SSLContext sslContext=null;
try
{
sslContext=new SSLContextBuilder().l
对于JAVA的join,JDK 是这样说的:join public final void join (long millis )throws InterruptedException Waits at most millis milliseconds for this thread to die. A timeout of 0 means t
在网站项目中,没必要把公用的函数写成一个工具类,有时候面向过程其实更方便。 在入口文件index.php里添加 require_once('protected/function.php'); 即可对其引用,成为公用的函数集合。 function.php如下:
<?php /** * This is the shortcut to D
这篇日志是我写的第三次了 前两次都发布失败!郁闷极了!
由于在web开发中常常用到这一部分所以在此记录一下,呵呵,就到备忘录了!
我对于登录信息时使用session存储的,所以我这里是通过实现HttpSessionAttributeListener这个接口完成的。
1、实现接口类,在web.xml文件中配置监听类,从而可以使该类完成其工作。
public class Ses
Spring Boot 1.3.0.M1于6.12日发布,现在可以从Spring milestone repository下载。这个版本是基于Spring Framework 4.2.0.RC1,并在Spring Boot 1.2之上提供了大量的新特性improvements and new features。主要包含以下:
1.提供一个新的sprin

 401
401

 收藏
2
收藏
2
 原力计划
原力计划

 在训练中, 大量出现上图所示的图片, 人眼基本不无法辨认, 只能靠机器识别.另外官方也声明了不允许去使用某些算法还原训练集.
在训练中, 大量出现上图所示的图片, 人眼基本不无法辨认, 只能靠机器识别.另外官方也声明了不允许去使用某些算法还原训练集.