Flask 源码阅读笔记
我觉得我已经养成了一个坏习惯,在使用一个框架过程中对它的内部原理非常感兴趣,有时候需要花不少精力才
明白,这也导致了学习的缓慢,但换来的是对框架的内部机理的熟悉,正如侯捷所说,源码面前,了无秘密。这也是
本文产生的直接原因。
一.flask session原理
flask的session是通过客户端的cookie实现的,不同于diango的服务器端实现,flask通过itsdangerous这个苦
将session的内容序列化到浏览器的cookie,当浏览器再次请求时将反序列化cookie内容,也就得到我们的session内容。
比如说session['name']='kehan',客户端session如下,
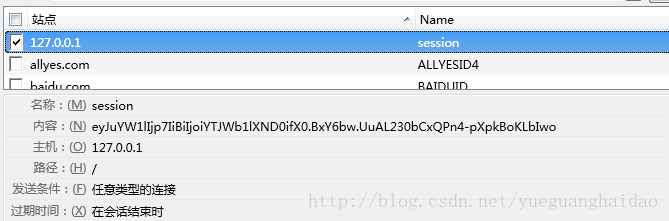
我们来解密这个cookie存储了什么值
该cookie通过.分割,分成了三部分:内容序列化+时间+防篡改值

通过第一部分我们就获得了session['name']的值,我们看看第二部分
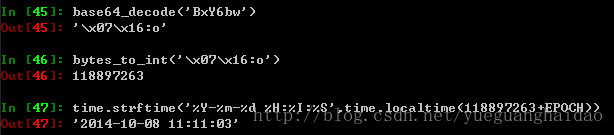
第二部分保存的是时间,itsdangerous库为了减少时间戳的值,之前减掉了118897263,所以我们要加上。
这个时间flask是用来判断session是否过期使用的。
第三部分是session值和时间戳以及我们SECRET_KEY的防篡改值,通过HMAC算法签名。也就是说即使你修改了
前面的值,由于签名值有误,flask不会使用该session。所以一定要保存好SECRET_KEY,以及确保它的复查度,
不然一旦让别人知道了SECRET_KEY,就可以通过构造cookie伪造session值,这是很恐怖的一件事。
我们知道一般为了保护session,所以session的生成还会包含客户端user_agent,remete_addr等,如果你觉得使用
flask提供的保护力度不够,可以使用flask_login这个扩展,一帮在flask使用认证时都会使用这个扩展,简单易用,
还提供了更加强度的session保护。
二. flask扩展import 原理
我喜欢flask的一个理由就是导入简单,非扩展的都可以通过from flask导入,扩展的都是通过from flask.ext.
导入,非常简洁。用django的过程中,经常不记得该从哪里导入,在flask的世界里,你无需烦恼。那么flask的扩展
导入原理是什么呢?
主要通过sys.meta_path实现的
当导入 from falsk.ext.example import E是将会执行flask/ext/__init__.py
当导入 from falsk.ext.example import E是将会执行flask/ext/__init__.py
def setup():
from ..exthook import ExtensionImporter
importer = ExtensionImporter(['flask_%s', 'flaskext.%s'], __name__)
importer.install()比如当我们 from flask.ext.script import Manager时
会调用find_module('flask.ext.script'),prefinx是flask.ext所以将会调用load_module()
此时将会尝试import flask_script模块或flaskext.script
def install(self):
sys.meta_path[:] = [x for x in sys.meta_path if self != x] + [self]
def find_module(self, fullname, path=None):
if fullname.startswith(self.prefix):
return self
def load_module(self, fullname):
modname = fullname.split('.', self.prefix_cutoff)[self.prefix_cutoff]
for path in self.module_choices:
realname = path % modname
__import__(realname)三. flask sqlalchemy原理
sqlalchemy是python中最强大的orm框架,无疑sqlalchemy的使用比django自带的orm要复杂的多,
使用flask sqlalchemy扩展将拉近和django的简单易用距离。
先来说两个比较重要的配置
app.config['SQLALCHEMY_ECHO'] = True =》配置输出sql语句
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True =》每次request自动提交db.session.commit(),
如果有一天你发现别的写的视图中有db.session.add,但没有db.session.commit,不要疑惑,他肯定配置了上面
的选项。
这是通过app.teardown_appcontext注册实现
@teardown
def shutdown_session(response_or_exc):
if app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN']:
if response_or_exc is None:
self.session.commit()
self.session.remove()
return response_or_exc上面self.session.remove()表示每次请求后都会销毁self.session,为什么要这么做呢?
这就要说说sqlalchemy的session对象了。
from sqlalchemy.orm import sessionmaker
session = sessionmaker()
一帮我们会通过sessionmaker()这个工厂函数创建session,但这个session并不能用在多线程中,为了支持多线程
操作,sqlalchemy提供了scoped_session,通过名字反映出scoped_session是通过某个作用域实现的
所以在多线程中一帮都是如下使用session
from sqlalchemy.orm import scoped_session, sessionmaker
session = scoped_session(sessionmaker())
所以在多线程中一帮都是如下使用session
from sqlalchemy.orm import scoped_session, sessionmaker
session = scoped_session(sessionmaker())
我们来看看scoped_session是如何提供多线程环境支持的
class scoped_session(object):
def __init__(self, session_factory, scopefunc=None):
self.session_factory = session_factory
if scopefunc:
self.registry = ScopedRegistry(session_factory, scopefunc)
else:
self.registry = ThreadLocalRegistry(session_factory)
函数)而scopefunc就是能产生某个作用域的函数,如果不提供将使用ThreadLocalRegistry
class ThreadLocalRegistry(ScopedRegistry):
def __init__(self, createfunc):
self.createfunc = createfunc
self.registry = threading.local()
def __call__(self):
try:
return self.registry.value
except AttributeError:
val = self.registry.vdef instrument(name):
def do(self, *args, **kwargs):
return getattr(self.registry(), name)(*args, **kwargs)
return do
for meth in Session.public_methods:
setattr(scoped_session, meth, instrument(meth))
调用__call__的时机,但是在flask_sqlalchemy中并没有使用ThreadLocalRegistry,创建scoped_session过程如下
# Which stack should we use? _app_ctx_stack is new in 0.9
connection_stack = _app_ctx_stack or _request_ctx_stack
def __init__(self, app=None,
use_native_unicode=True,
session_options=None):
session_options.setdefault(
'scopefunc', connection_stack.__ident_func__
)
self.session = self.create_scoped_session(session_options)
def create_scoped_session(self, options=None):
"""Helper factory method that creates a scoped session."""
if options is None:
options = {}
scopefunc=options.pop('scopefunc', None)
return orm.scoped_session(
partial(_SignallingSession, self, **options), scopefunc=scopefunc
)如果你看过前一篇文章你就知道__ident_func__其实就是在多线程中就是thrading.get_ident,也就是线程id
我们看看ScopedRegistry是如何通过_操作的
class ScopedRegistry(object):
def __init__(self, createfunc, scopefunc):
self.createfunc = createfunc
self.scopefunc = scopefunc
self.registry = {}
def __call__(self):
key = self.scopefunc()
try:
return self.registry[key]
except KeyError:
return self.registry.setdefault(key, self.createfunc())
魔法了,和flask cookie,g有异曲同工之妙,这里有两个小问题?
1.flask_sqlalchemy能否使用ThreadLocalRegistry?
大部分情况都是可以的,但如果wsgi对多并发使用的是greenlet的模式就不适用了
2.上面create_scoped_session中partial是干嘛的?
前面我们说过scoped_session的session_factory是可调用对象,但_SignallingSession类并没有定义__call__,所以通过partial支持
到这里你就知道为什么每次请求结束要self.session.remove(),不然为导致存放session的字段太大
1.flask_sqlalchemy能否使用ThreadLocalRegistry?
大部分情况都是可以的,但如果wsgi对多并发使用的是greenlet的模式就不适用了
2.上面create_scoped_session中partial是干嘛的?
前面我们说过scoped_session的session_factory是可调用对象,但_SignallingSession类并没有定义__call__,所以通过partial支持
到这里你就知道为什么每次请求结束要self.session.remove(),不然为导致存放session的字段太大
这里说一下对db.relationship lazy的理解,看如下代码
class Role(db.Model):
__tablename__ = 'roles'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
users = db.relationship('User', backref='role', lazy='dynamic')
class User(db.Model):
__tablename__ = 'users'
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(64), unique=True, index=True)
role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))lazy:dynamic => role.users不会返回User的列表, 返回的是sqlalchemy.orm.dynamic.AppenderBaseQuery对象
当执行role.users.all()是才会真正执行sql,这样的好处就是可以继续过滤
lazy:select => role.users直接返回User实例的列表,也就是直接执行sql
注意:db.session.commit只有在对象有变化时才会真的执行update
四. flask moment原理
flask moment简单封装了moment.js,moment.js通过js提供了对时间的支持,感兴趣的童鞋可以关注下,
功能非常强大。
flask moment原理很简单,使用带有时间的格式话字符串在dom加载后,使用moment.js处理一下,
该步操作有moment.include_moment()完成。如果使用其它语言,如中文,调用moment.lang('zh-cn')
如果使用了flask bootstrap,只需要在最后添加以下代码即可(需要jquery支持)
如果使用了flask bootstrap,只需要在最后添加以下代码即可(需要jquery支持)
{% block scripts %}
{{ super() }}
{{ moment.include_moment() }}
{{ moment.lang('zh-cn') }}
{% endblock %}
单位为分钟
{{ moment(current_time).fromNow(refresh=True) }}
{{ moment(current_time).fromNow(refresh=True) }}
看上面我们知道,
flask moment在模板中导入了moment这个对象,这是如何实现的呢?
def init_app(self, app):
if not hasattr(app, 'extensions'):
app.extensions = {}
app.extensions['moment'] = _moment
app.context_processor(self.context_processor)
@staticmethod
def context_processor():
return {
'moment': current_app.extensions['moment']
}def render_template(template_name_or_list, **context):
ctx.app.update_template_context(context)
在render_template中会把前面注册的变量添加到context,所以在模板中就可以使用moment了,
而flask bootstrap是通过app.jinja_env.globals['bootstrap_find_resource'] = bootstrap_find_resource实现的
而flask bootstrap是通过app.jinja_env.globals['bootstrap_find_resource'] = bootstrap_find_resource实现的
我们知道flask在初始化jinja环境的时候就将request,g,session等注入到全局了
rv.globals.update(
url_for=url_for,
get_flashed_messages=get_flashed_messages,
config=self.config,
# request, session and g are normally added with the
# context processor for efficiency reasons but for imported
# templates we also want the proxies in there.
request=request,
session=session,
g=g
)def _default_template_ctx_processor():
"""Default template context processor. Injects `request`,
`session` and `g`.
"""
reqctx = _request_ctx_stack.top
appctx = _app_ctx_stack.top
rv = {}
if appctx is not None:
rv['g'] = appctx.g
if reqctx is not None:
rv['request'] = reqctx.request
rv['session'] = reqctx.session
return rv哈哈,认真看上面rv.globals.update的注释部分能大概明白。
flask模板可以使用宏,需要使用import导入,此时导入的模板不能访问不能访问当前模板的本地变量,只能使用全局变量。
这也就是为什么global中有g,request,session的理由,也即是为了支持在宏中使用g对象
而本地变量导入g等是为了效率的原因,具体细节需要参考jinja2的文档。