语音识别初探
本文是对最近学习的语音识别的一个总结,主要参考以下内容:
《解析深度学习——语音识别实践》
http://licstar.net/archives/328 词向量和语言模型
几篇论文,具体见参考文献
语音识别任务是把声音数据转换为文本,研究的主要目标是实现自然语言人机交互。在过去的几年里,语音识别领域的研究成为人们关注的热点,出现了众多新型
语音应用,例如语音搜索、虚拟语音助手(苹果的Siri)等。
语音识别任务的pipline

语音识别任务的输入是声音数据,首先要对原始的声音数据进行一系列的处理(短时傅里叶变换或取倒譜...),变成向量或矩阵的形式,称为特征序列。这个过程
是特征提取,最常用的是mfcc特征序列。这里就不深入学习了,只要知道这是语音识别的第一步。
然后,我们要对这些特征序列数据建模。传统的语音识别方案中采用的是混合高斯分布建模。其实不仅仅在语音识别领域,还有很多工程和科学学科领域,高斯分
布是非常流行的。它的流行不仅来自其具有令人满意的计算特性,而且来自大数定理带来的可以近似很多自然出现的实际问题的能力。
混合高斯分布:
一个服从混合高斯分布的连续随机标量x,它的概率密度函数为:

其中 ![]()
推广到多变量的多元混合高斯分布,其联合概率密度函数为:
混合高斯分布最明显的特征是它的多模态(M>1),不同于高斯分布的单模态性质M=1。这使得混合高斯分布能够描述很多显示出多模态性质的数据(包括语音数
据),而单高斯分布则不适合。数据中的多模态性质可能来自多种潜在因素,每一个因素决定分布中一个特定的混合成分。
当语音数据经过特征提取,转换为特征序列之后,在忽略时序信息的条件下,混合高斯分布就是非常适合拟合这样的语音特征。也就是说,可以以帧为单位,用混
合高斯模型对语音特征进行建模。
如果考虑把语音顺序信息考虑进去,GMM便不再是一个好的模型,因为它不包含任何顺序信息。
这时,使用一类名叫隐马儿可夫模型(HiddenMarkov Model)来对时序信息进行建模。然而,当给定HMM的一个状态后,若要对属于该状态的语音特征向量
的概率分布进行建模,GMM仍然是一个好的模型。
所以传统的语音识别中,GMM+HMM作为声学模型。
语言模型
语言模型其实就是看一句话是不是正常人说出来的。它可以用在很多地方,比如机器翻译、语音识别得到若干候选之后,可以利用语言模型挑一个尽量靠谱的结
果。在NLP的其它任务里也都能用到。
语言模型形式化的描述就是给定一个字符串,看它是自然语言的概率P(w1,w2,…,wt)。w1到wt依次表示这句话中的各个词。有个很简单的推论是:
P(w1,w2,…,wt)=P(w1)×P(w2|w1)×P(w3|w1,w2)×…×P(wt|w1,w2,…,wt−1)
常用的语言模型都是在近似地求P(wt|w1,w2,…,wt−1)。比如n-gram模型就是用P(wt|wt−n+1,…,wt−1)近似表示前者。
语言模型经典之作:
训练语言模型的最经典之作,要数Bengio等人在2001年发表在NIPS上的文章《ANeural Probabilistic Language Model》。当然现在看的话,肯定是要看他在2003年投到JMLR上的同名论文了。
Bengio用了一个三层的神经网络来构建语言模型,同样也是n-gram 模型。
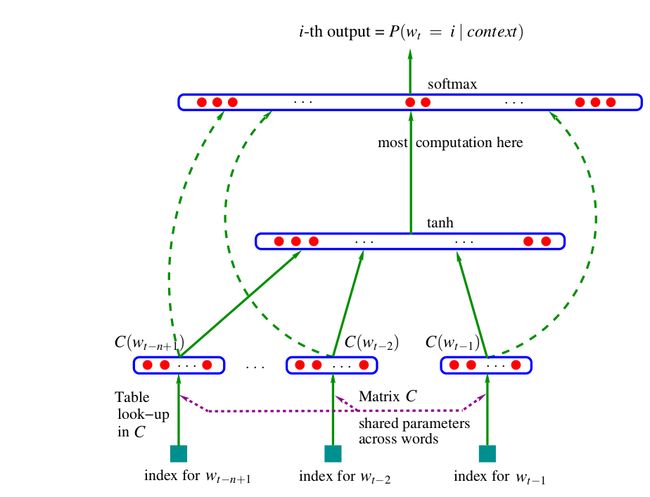
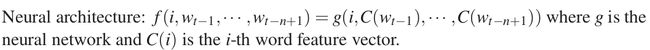
图中最下方的wt−n+1,…,wt−2,wt−1就是前n−1个词。现在需要根据这已知的n−1个词预测下一个词wt。C(w)表示词w所对应的词向量,整个模型中使用的是一套唯一的词向量,存在矩阵C(一个|V|×m的矩阵)中。其中|V|表示词表的大小(语料中的总词数),m表示词向量的维度。w到C(w)的转化就是从矩阵中取出一行。
网络的第一层(输入层)是将C(wt−n+1),…,C(wt−2),C(wt−1)这n−1个向量首尾相接拼起来,形成一个(n−1)m维的向量,下面记为x。
网络的第二层(隐藏层)就如同普通的神经网络,直接使用d+Hx计算得到。d是一个偏置项。在此之后,使用tanh作为激活函数。
网络的第三层(输出层)一共有|V|个节点,每个节点yi表示下一个词为 i的未归一化log概率。最后使用softmax激活函数将输出值y归一化成概率。最终,y
的计算公式为:
y=b+Wx+Utanh(d+Hx)
式子中的U
一个|V|×h的矩阵)是隐藏层到输出层的参数,整个模型的多数计算集中在U和隐藏层的矩阵乘法中。后文的提到的3 个工作,都有对这一环节的简化,提升计算的速度。
式子中还有一个矩阵W(|V|×(n−1)m),这个矩阵包含了从输入层到输出层的直连边。直连边就是从输入层直接到输出层的一个线性变换,好像也是神经网络中的一种常用技巧(没有仔细考察过)。如果不需要直连边的话,将W置为0 就可以了。在最后的实验中,Bengio发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
现在万事俱备,用随机梯度下降法把这个模型优化出来就可以了。需要注意的是,一般神经网络的输入层只是一个输入值,而在这里,输入层x也是参数(存在C中),也是需要优化的。优化结束之后,词向量有了,语言模型也有了。
到此为止,就可以看懂语音识别的pipline了
从概率角度理解语音识别
从概率角度理解语音识别任务的话,语音识别可以说是在尝试找到一个从语音到文本的最优的映射函数,使得错词率(WER)最小。
语音输入O,文本输出W,W=F(O),找到F使得错词率(WER)最小
贝叶斯决策:比较不同词序列的后验概率,选择能够最大化后验概率P(W|O)的词序列作为语音识别系统的输出结果。
P(O|W),对应声学模型,用来评价语音观测样本值O和词序列W对应模型之间的匹配程度。
P(W),对应语言模型,用于表示在人类使用的自然语言中词序列W本身可能出现的概率。
声学模型的变迁
在深度学习的浪潮兴起之后,DNN也应用在了语音识别领域中,主要是声学模型部分。
DNN+HMM作为声学模型
很快,DNN+HMM+LM的模式被DN+LM的模式取代,利用深度神经网络实现端到端的语音识别系统。比较经典的论文:
[5] "DeepSpeech:Scaling up end-to-end speech recognition" & "Deepspeech 2: End-to-end speech recognition in english and mandarin."arXiv preprint arXiv:1512.02595 (2015). [pdf](Baidu Speech Recognition System)
主要专注于提高嘈杂环境(例如,餐馆、汽车和公共交通)下的英语语音识别的准确率。DeepSpeech可以在嘈杂环境下实现接近80%的准确率,而其他商业版语音识别API最高识别率在65%左右。跟顶级的学术型语音识别模型(基于流行的数据集Hub500建模)相比也高出9个百分点。
Deep Speech的基础是某种递归神经网络(RNN),采用了端到端的深度学习模型。结构如图所示。

共五层,前三层是简单的DNN结构,第四层是双向RNN,第五层的输入是RNN的前向和后向单元,后面跟着softmax分类。网络输入是context特征,输出是char,
训练准则是CTC,解码需要结合ngram语言模型。
DeepSpeech的成功主要得益于庞大的语音数据训练集。首先百度收集了9600个人长达7000小时语音数据,这些语音大多发生在安静的环境下。然后再将这些语音文件与包含有背景噪音的文件合成到一起,最后形成约10万小时的训练集。这些背景噪音包括了饭店、电视、自助餐厅以及汽车内、火车内等场景。另一方面,DeepSpeech的成功很大程度上要取决于规模庞大的基于GPU的深度学习基础设施。在论文中也有大量篇幅描述了优化模型训练的方法。
语音识别的最新进展:
[7]Anonline sequence-to-sequence model for noisy speech recognition
谷歌提出在线序列到序列语音识别系统。
[8]AttentionIs All You Need
attention机制.通常来说,主流序列传导模型大多基于RNN或CNN。Google此次推出的翻译框架—Transformer则完全舍弃了RNN/CNN结构,从自然语言本身的特性出发,实现了完全基于注意力机制的Transformer机器翻译网络架构。
[9]MultichannelEnd-to-end Speech Recognitio
attention-basedencoder-decoder framework 实现了cleanspeech的端到端的语音识别,本文是在其基础上进行扩展,加入了multichannelspeech enhancement,解决了噪音环境下的语音识别。
[10]OneModel To Learn Them All
[11]GAN在语音识别方面的尝试
总结和回顾:
语音识别经历了 GMM+HMM+LM ==》 DNN+HMM+LM ==》 DNN+LM的变迁。在实现深度神经网络端到端语音识别系统之后,人们在不断的尝试引入新型网络结
构、attention机制、多任务学习、GAN等技术来进一步提高语音识别特别是嘈杂环境下语音识别的准确率。
参考文献
[1]"Deep neural networks for acoustic modeling in speechrecognition: The shared views of four research groups."Hinton, Geoffrey, et al. IEEE Signal Processing Magazine 29.6 (2012):82-97. [pdf](Breakthrough in speech recognition)
深度神经网络替换传统的声学模型。
[2]"Speech recognition with deep recurrent neuralnetworks." Graves, Alex, Abdel-rahman Mohamed, andGeoffrey Hinton. 2013 IEEE international conference on acoustics,speech and signal processing. IEEE, 2013. [pdf](RNN)
[3] "TowardsEnd-To-End Speech Recognition with Recurrent Neural Networks."Graves, Alex, and Navdeep Jaitly. ICML. Vol. 14. 2014. [pdf]
利用RNN实现端到端的语音识别。
[4] "Fastand accurate recurrent neural network acoustic models for speechrecognition."Sak, Haşim, et al. arXiv preprintarXiv:1507.06947 (2015). [pdf](Google Speech Recognition System)
[5] "DeepSpeech:Scaling up end-to-end speech recognition" & "Deepspeech 2: End-to-end speech recognition in english and mandarin."arXiv preprint arXiv:1512.02595 (2015). [pdf](Baidu Speech Recognition System)
[6] "AchievingHuman Parity in Conversational Speech Recognition." W.Xiong, J. Droppo, X. Huang, F. Seide, M. Seltzer, A. Stolcke, D. Yu,G. Zweig. arXiv preprint arXiv:1610.05256 (2016). [pdf](State-of-the-art in speech recognition, Microsoft)
[7] "Anonline sequence-to-sequence model for noisy speech recognition."
[8] "ANeural Probabilistic Language Model ."
[9]MultichannelEnd-to-end Speech Recognition
[10]OneModel To Learn Them All
[11]GAN在语音识别方面的尝试