Spark Streaming读取kafka中数据详解
话不多说今天就给大家说下Spark Streaming如何读取Kafka中数据
先导依赖包到pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.4</version>
</dependency>Spark Streaming与kafka集成有以下两种方式:
- 基于Receiver的方式
- 基于Direct的方式
基于Direct方式
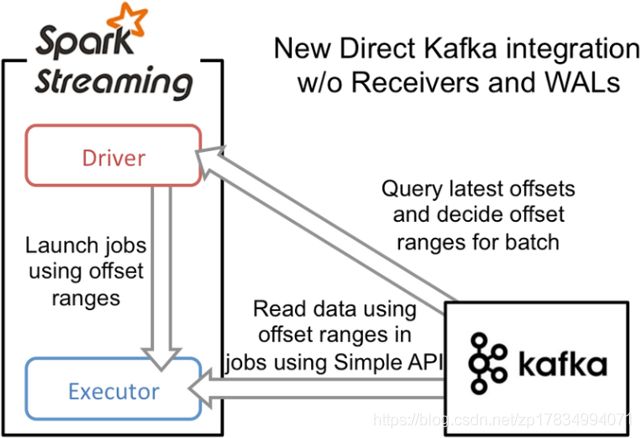
在Spark1.3版本中引入,替代使用Receiver来接收数据,这种方式会周期性地查询kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围,当处理数据的job启动时,就会使用kafka的简单Consumer API来获取kafka中指定offset范围的数据。
基于Direct方式的优势:
-
简化并行读取:如果要读取多个partition,不需要创建多个输入DStream然后对他们进行union操作。Spark会创建跟Kafka partition一样多的RDD partition,并且会并行从kafka中读取数据。所以在kafka partition和RDD partition之间,有一一对应的关系。
-
高性能:如果要保证数据零丢失,在基于Receiver的方式中,需要开启WAL机制。这种方式其实效率很低,因为数据实际被复制了两份,kafka自己本身就有高可靠的机制,会对数据复制一份,而这里又会复制一份到WAL中。
而基于Direct的方式,不依赖于Receiver,不需要开启WAL机制,只要kafka中做了数据的复制,那么就可以通过kafka的副本进行恢复。 -
强一致语义:基于Receiver的方式,使用kafka的高阶API来在Zookeeper中保存消费过的offset。这是消费kafka数据的传统方式。这种方式配合WAL机制,可以保证数据零丢失的高可靠性,但是却无法保证数据被处理一次且仅一次,可能会处理两次。因为Spark和Zookeeper之间可能是不同步的。
基于Direct的方式,使用kafka的简单api,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保证数据时消费一次且仅消费一次。 -
降低资源:Direct不需要Receiver,其申请的Executors全部参与到计算任务中;而Receiver则需要专门的Receivers来读取kafka数据且不参与计算。因此相同的资源申请,Direct能够支持更大的业务。
Receiver与其他Executor是异步的,并持续不断接收数据,对于小业务量的场景还好,如果遇到大业务量时,需要提高Receiver的内存,但是参与计算的Executor并不需要那么多的内存,而Direct因为没有Receiver,而是在计算的时候读取数据,然后直接计算,所以对内存的要求很低。 -
并发性更好:基于Receiver方式需要Receiver来异步持续不断的读取数据,因此遇到网络、存储负载等因素,导致实时任务出现堆积,但Receiver却还在持续读取数据,此种情况容易导致计算崩溃。
Direct则没有这种顾虑,其Driver在触发batch计算任务时,才会读取数据并计算,队列出现堆积并不不会引起程序的失败。
基于Direct方式的不足
- Direct方式需要采用checkpoint或者第三方存储来维护offset,而不是像Receiver那样,通过Zookeeper来维护offsets,提高了用户的开发成本。
- 基于Receiver方式指定topic指定consumer的消费情况均能够通过Zookeeper来监控,而Direct则没有这么便利,如果想做监控并可视化,则需要投入人力开发。
基于Direct方式读取kafka中数据
创建maven工程,导入依赖包之后开始读取kafka数据
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.{
SparkConf, SparkContext}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{
ConsumerStrategies, KafkaUtils, LocationStrategies}
object MyRead {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("mykafka")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc = new SparkContext(conf)
//流处理的上下文类
val ssc = new StreamingContext(sc, Seconds(1))//一定要是滑动窗口的倍数,并且比窗口的数小
//因为有状态Dstream 所以必须要有地方记录
ssc.checkpoint("g:/mykafka-logs")
//创建连接kafka服务器参数
val kafkaParam = Map(
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "192.168.5.150:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "mykafka1", //必须要组名
ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG -> "true", //默认值true
ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG -> "20000", //默认值5000,循环多长时间提交一次
//ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "earliest", //相当于 --from-beginning
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer], // 读是反序列化
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer]
)
//创建direct流
val streams = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("mydemo"), kafkaParam)).map(x=>x)
streams.map(x=>x.value().toDouble).window(Seconds(5),Seconds(1)).foreachRDD(rdd=>{
println(rdd.sum()/rdd.count())
})
val wnd = streams.window(Seconds(5), Seconds(1))
wnd.print()
//简单的数据处理 并打印
streams.map(_.value).flatMap(_.split("")).map((_, 1)).reduceByKey(_ + _).print()
//无状态就是每个方法互不干扰,相互没关系
//有状态就是把前面的数据暗流到state里面,下一隔能看到里面的数据
//因为有状态,所以必须要有地方记录
//带状态的Dstream 不会把原先的数据覆盖掉
// ssc.checkpoint("g:/mykafka-logs")
// streams.map(_.value).flatMap(_.split(",")).map((_,1))
// .updateStateByKey((values:Seq[Int],state:Option[Int])=>Option(state.getOrElse(0)+values.sum)).print( )
ssc.start()
ssc.awaitTermination()
在Linux创建topic ,并启动生产消息 ,再启动IDEA的Spaark Streaming,每隔几秒就会再控制台打印接收到生产消息producer发出的信息。
在linux中创建topic
kafka-topics.sh --create --zookeeper 192.168.5.150:2181 --replication-factor 1 --partitions 1 --topic mydemo启动生产消息
kafka-console-producer.sh --broker-list 192.168.5.150:9092 --topic mydemo输入数据,到idea中的控制台就可以根据设置好的时间,每隔几秒就能接收到数据。
基于Receiver方式读取kafka中数据
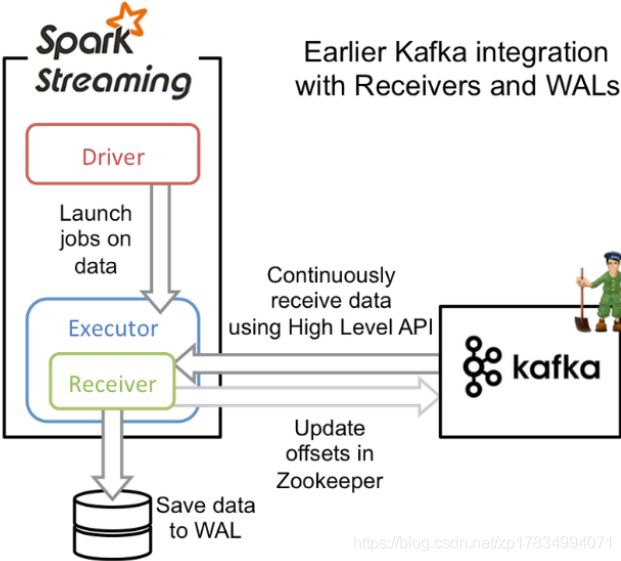
这种方式使用Receiver来接收kafka中的数据,Receiver是基于kafka的高层Consumer API来实现的。Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark Streaming启动的job会去处理那些数据。
在提交Spark Streaming任务后,Spark集群会划出指定的Receivers来专门、持续不断、异步读取kafka数据,读取时间间隔以及每次读取offsets访问由参数来配置。读取的数据保存在Receiver中,具体StorageLevel方式由用户指定。
当Driver触发batch任务的时候,Receivers中的数据会转移到Executors中去执行。在执行完之后,Receivers会相应更新Zookeeper的offsets。
在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log, WAL)。该机制会同步地将接收到的kafka数据写入到分布式文件系统(如HDFS)上的预写日志中。所以,即使底层节点出现了失败,也可以通过预写日志中的数据进行恢复。
确保At least once的读取方式,可以设置:
spark.streaming.receiver.writeAheadLog.enable = true
基于Receiver方式读取数据,用户可以专注于所读数据,而不用关注或维护consumer的offsets,这减少了用户的工作以及代码量,而且相对比较简单。
基于Receiver方式存在的问题:
- 启用WAL机制,每次处理之前需要将该batch内的数据备份到checkpoint目录中,这降低了数据处理效率,同时加重了Receiver的压力;另外由于数据备份机制,会收到负载影响,负载一高就会出现延迟的风险,导致应用崩溃。
- 采用MEMORY_AND_DISK_SER降低对内存的要求,但是在一定程度上影响了计算的速度。
- 单Receiver内存。由于Receiver是属于Executor的一部分,为了提高吞吐量,提高Receiver的内存。但是在每次batch计算中,参与计算的batch并不会使用这么多内存,导致资源严重浪费。
- 提高并行度,采用多个Receiver来保存kafka的数据。Receiver读取数据是异步的,不会参与计算。如果提高了并行度来平衡吞吐量很不划算。
- Receiver和计算的Executor是异步的,在遇到网络等因素时,会导致计算出现延迟,计算队列一直在增加,而Receiver一直在接收数据,这非常容易导致程序崩溃。
- 在程序失败恢复时,有可能出现数据部分落地,但是程序失败,未更新offsets的情况,这会导致数据重复消费。
所以选择哪种方式在于你们自己的选择,小编还是喜欢用基于Direct方式读取kafka中数据,有新的看法可以留言。