WRN 论文笔记
WRN:Wide Residual Networks
摘要
深度残差网络能够将网络深度扩大到上千层,并且有很好的性能提升。但是,分类准确率每提高百分之一的代价几乎是层数的两倍。所以训练非常深的残差网络有一个问题:特征利用率逐渐下降,这使得残差网络的训练非常慢。为了解决这些问题,本文中,我们对残差块进行了详细的实验研究。基于该研究,我们提出了一个新架构,这个架构减少了深度并且增加了残差网络的宽度。我们称这个新的架构为wide residual networks (WRNs),WRN比通常使用的细且深的残差网络有着更好的性能。在文中,我们研究了一个简单的16层深的WRN网络。这个WRN网络比以前的残差网络(包括上千层的网络)的准确率更高且效率更高。并且在CIFAR、SVHN、COCO数据集上取得了新的state of art,在ImageNet上大福度地提高了性能。我们的模型的代码详见 https://github.com/szagoruyko/wide-residual-networks.
摘要(英文)
Deep residual networks were shown to be able to scale up to thousands of layers and still have improving performance. However, each fraction of a percent of improved accuracy costs nearly doubling the number of layers, and so training very deep residual networks has a problem of diminishing feature reuse, which makes these networks very slow to train. To tackle these problems, in this paper we conduct a detailed experimental study on the architecture of ResNet blocks, based on which we propose a novel architecture where we decrease depth and increase width of residual networks. We call the resulting network structures wide residual networks (WRNs) and show that these are far superior over their commonly used thin and very deep counterparts. For example, we demonstrate that even a simple 16-layer-deep wide residual network outperforms in accuracy and efficiency all previous deep residual networks, including thousand-layer deep networks, achieving new state-of-the-art results on CIFAR, SVHN, COCO, and significant improvements on ImageNet. Our code and models are available at https://github.com/szagoruyko/wide-residual-networks.
1. 简介
从AlexNet、VGG、Inception到ResNet,卷积神经网络在近几年越来越深,深度的增加与性能的提升直接相关。近几年的一些研究已经表明了网络深度至关重要。但是训练深度神经网络有很多难点:梯度爆炸、梯度消失和网络性能退化。现在已经有很多方法来训练更深的神经网络,例如:精心设计的初始化策略(well-designed initialization strategies),更好的优化器(better optimizers),跳跃连接(skip connections)、网络迁移(knowledge transfer)和逐层训练(layer-wise training)。
最新的残差网络在ImageNet和COCO 2015比赛中获胜并且在很多基准上取得了state of art(ImageNet和CIFAR的分类比赛,PASCAL VOC及MS COCO数据上的物体探测,分割比赛)。与Inception架构相比,ResNet表现出更好的泛化性能,这意味着提取到的特征在迁移学习中有很高的效率。同时,对ResNet的其它研究表明残差连接能够加速网络的收敛速度。ResNet_v2探究了残差网络的activations的次序,并且提高了非常深的网络的训练。highway网络的使用使得非常深的网络的训练变得可能。highway的提出早于ResNet网络。ResNet和highway的主要区别是resnet中的残差连接有门(gated)并且门的权重是学习得到的(weights of these gates are learned)。
因此,到目前为止,残差网络的研究主要关注ResNet块内部的activations的顺序 和 残差网络的深度。在本文,我们尝试去进行一个实验研究。通过这个研究,我们的目标是去进一步地探索残差块,并且进一步地研究除activations的顺序之外的一些影响性能的因素。正如我们下面解释的一样,这样的架构探索让我们对残差网络有了有趣的新发现。
Width vs depth in residual networks
网络的深浅问题在机器学习中已经讨论了很长时间,circuit complexity theory的研究表明在复杂性相同的情况下,浅层网络比深层网络多指数倍的部件(shallow circuits can require exponentially more components than deeper circuits)。残差网络的作者尝试去加深网络深度来使得网络变得细长并且有更少的参数,甚至引入了一个瓶颈块(使得残差单元更加细长)。
但是,我们注意到包含identity mapping的残差块允许我们去训练非常深的网络的同时,这个残差块也是残差网络的一个缺点。当梯度流通过整个网络时,网络不会强迫梯度流过权重层(这会导致训练中学习不到什么)。所以很有可能少量的块能够学习有用的表达,或者很多的块分享非常少的信息,对最终结果影响很小。(As gradient flows through the network there is nothing to force it to go through residual block weights and it can avoid learning anything during training, so it is possible that there is either only a few blocks that learn useful representations, or many blocks share very little information with small contribution to the final goal.)这个问题可以被总结为diminishing feature reuse。有人尝试通过随机停用残差网络的一些块的思路来解决这个问题。这个方法被看作dropout的一个特例,每一个残差块有一个identity权重,dropout就是对这个权重进行dropout。这个方法的有效性证明了上面的假设。
受上述观察的启发,我们的工作建立在resnet_v2的基础上,并试图回答wide deep residual networks应该如何解决和解决训练问题。在这种情况下,我们表明,以正确的方式加宽残差块提供了一种更加高效的提高残差网络性能的方法,而不是增加网络深度。尤其,我们提出的wider deep residual网络(WRN)在ResNet_v2的基础上提高了挺多。WRN的深度只有原始深度的五十分之一,推理速度快2倍。我们称产生的网络架构为wider residual networks。在实践中,16层深的WRN网络和1000层的ResNet有着相同的准确率,参数量基本一样,但训练快了很多倍。这种类型的实验看起来表明了深度残差网络的main power是残差块,深度的效应是补充。我们注意到我们能够训练更宽的残差网络(参数量比原始的resnet的两倍或更多),这暗示我们如果想通过增加深度来提高性能,我们需要去增加上千层。
Use of dropout in ResNet blocks
Dropout是Hinton等人提出的,然后被很多成功的架构所使用。Dropout一般用在有很多参数的顶层去防止过拟合。后来,dropout主要被BN替代,提出BN是为了去减少神经网络activations的内部协方差(通过标准化),从而activations是一个特殊的分布。BN同时也作为一个正则器,BN的作者用实验说明包含BN的网络能够获得比不包含dropout的网络更高的准确率。在我们的例子中,加宽残差块导致参数量增加,所以我们在WRN里研究了dropout在训练过程中的正则效果和预防过拟合的效果。前人的研究中x,dropout被插入到了残差网络中的identity连接上,这导致性能下降。与前人不同,我们认为dropout应该被插入到卷积层之间。WRN的实验结果表明这能产生性能提升,甚至达到新的state of art(例如,16层的WRN-dropout在SVHN数据集上取得了1.64%的错误率)。
总结一下,本文的主要贡献:
- 我们对残差网络架构进行了一个详尽的实验研究,对残差块结构的很多重要方面进行了彻底的测试。
- 我们提出了一个新的WRN架构(将ResNet块进行了加宽)。WRN架构相对与ResNet,性能有了较大提高。
- 我们提出了一个在深度残差网络内部使用dropout的新方法,从而在训练中,进行正确的正则并且防止过拟合。
- 最后,我们说明了我们提出的WRN架构取得了在很多数据集上取得了state of art,并且准确率和速度都提高了很多。
2. Wide residual networks(WRN)
包含identity mapping的残差块能够用下面的公式表示:
这里 xl+1 x l + 1 和 xl x l 是网络第 l l 个单元的输入和输出, F F 是一个残差函数, Wl W l 该块的参数。残差网络包含很多顺序堆叠的残差块。
在残差网络中包含两种类型的块:
- basic b a s i c :包含两个3x3卷积,卷积后面都跟BN及ReLU。卷积的堆叠顺序是: conv3×3−conv3×3 conv 3 × 3 − conv 3 × 3 ,图1a。
- bottleneck b o t t l e n e c k :包含一个3x3卷积,3x3卷积前后都是1x1卷积,两个1x1卷积分别用来降维和升维。卷积的堆叠顺序是: conv1×1−conv3×3−conv1×1 conv 1 × 1 − conv 3 × 3 − conv 1 × 1 ,图1b。
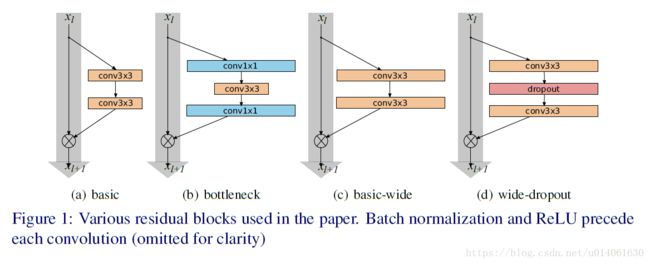
与ResNet_v1和v2的原始残差架构相比,BN、ReLU和卷积在块中的顺序从原始的 conv-BN-ReLU conv-BN-ReLU 改为了 BN−ReLU−conv B N − R e L U − c o n v 。更改顺序后,训练的更快,并且能取得更好的结果(不考虑原始版本)。进一步,bottleneck块使用的初衷是去减少因为层数的增加带来的计算量。因为我们想要去研究加快的作用,而bottleneck的作用是使得网络变得细长,所以我们也不考虑bottleneck,只关注于basic残差架构。
基本上有三种简单的方法去增加残差块的表示能力:
- 每个残差块内部增加更多的卷积层
- 通过增加特征面来加宽卷积层(to widen the convolutional layers by adding more feature planes)
- 增加卷积层的卷积核的尺寸
因为在VGG和Inception v4中,已经说明小卷积核在很多情况下更高效,所以我们使用的卷积核都不超过3x3。让我们引入两个系数:深度系数 l l 和宽度系数 k k ,这里 l l 为一个残差块内部的conv的数量; k k 为卷积层的特征平面数(multiplies the number of features in convolutional layers),因此在basic块中, l=2 l = 2 , k=1 k = 1 。图1a和1c说明了basic和basic-wide块的方案。
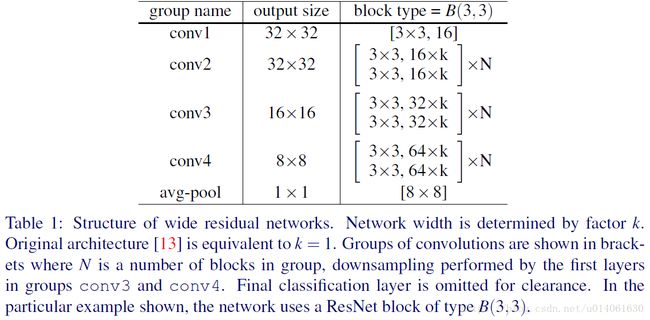
表1是我们的残差网络的通用框架。它包含一个初始的卷积层 conv1 c o n v 1 ,conv1后跟三组(每组的尺寸为N)残差块: conv2 c o n v 2 , conv3 c o n v 3 , conv4 c o n v 4 ,最后接 averagepooling a v e r a g e p o o l i n g 和分类层。在我们的实验中,conv1的尺寸是固定的,引入的宽度系数 k k 用来缩放三组残差块( conv2−4 c o n v 2 − 4 )的尺寸。我们想要去研究残差块的表达能力的影响,我们进行并测试很多basic的修改版本,这在下面的章节会进行详细描述。
2.1 残差块里的卷积的类型(Type of convolutions in residual block)
用 B(M) B ( M ) 表示残差块的结构,这里 M M 是块内使用的卷积层的卷积核的尺寸组成list。例如, B(3,1) B ( 3 , 1 ) 表示由一个3x3卷积层和一个1x1卷积层组成的残差块(这里假设所有的卷积核都是?x?)。注意,因为我们没有考虑 bottleneck bottleneck ,特征平面数在块中保持不变。我们想要去探究 basic basic 块中的每个3x3卷积层的重要性,另外,它们是否能用计算量更低的1x1卷积层或者1x1和3x3卷积层的结合来替代(例如 B(1,3) B ( 1 , 3 ) , B(3,1) B ( 3 , 1 ) )。这能够增加或降低块的表示能力。我们因此对下面的几种结合方案进行了试验,例如 B(3,1,1) B ( 3 , 1 , 1 ) 与NIN网络的效率相似:
- B(3,3) B ( 3 , 3 ) :原始的 basic basic 块
- B(3,1,3) B ( 3 , 1 , 3 ) :在 basic basic 的基础上增加一个1x1卷积层
- B(1,3,1) B ( 1 , 3 , 1 ) :所有的卷积的维度是一样,可以看作是straightened的 bottleneck bottleneck
- B(1,3) B ( 1 , 3 ) :1x1和3x3卷积交替
- B(3,1) B ( 3 , 1 ) :与上一种情况类似
- B(3,1,1) B ( 3 , 1 , 1 ) :NIN网络风格的块
2.2 每一个残差块中的卷积层的数量(Number of convolutional layers per residual block)
我们也对深度系数 l l 进行了试验,去看下 l l 对性能的影响。对比的网络的参数量相同,所以我们需要去用不同的 l l 和 d d 来构建网络(这里 d d 表示块的总数量),从而保证网络的总的复杂性大概保持不变。这意味着,当 l l 增加时, d d 应该减小。
2.3 残差块的宽度(Width of residual blocks)
除了上面的实验,我们也对宽度系数 k k 进行了实验。模型的参数量随 l l 线性增加,模型的参数和计算量与 k k 为立方次关系。但是,因为GPU在大的tensor上的并行计算更加高效,所以加宽层的方法比上千个小核更加高效,所以我们对 d d 和 k k 的最优比例很感兴趣(However, it is more computationally effective to widen the layers than have thousands of small kernels as GPU is much more efficient in parallel computations on large tensors, so we are interested in an optimal d to k ratio)。
对于WRN的一个观点是残差网络之前,几乎所有的架构(包括Inception、VGG)都比ResNet_v2宽的多。例如,WRN-22-8和WRN-16-10(详细解释见后面)的宽度、深度和参数量和VGG架构非常接近。
我们将原始的ResNet( k=1 k = 1 )称为“thin”,当 k>1 k > 1 时称为“wide”。在后面,我们使用下面的标记:WRN- n n - k k 表示一个有 n n 个卷积层,宽度系数为 k k 的残差网络(例如,40层, k=2 k = 2 的网络将被记作WRN-40-2)。同时,必要时,我们将用后缀表明块的类型(例如WRN-40-2- B B (3,3))。
2.4 残差网络中的dropout(Dropout in residual blocks)
因为网络的加宽导致参数量增加,所以我们将研究正则化方法。残差网络中的BN已经提供了一个正则,但是它需要强有力的数据增强(heavy data augmentation),我们想要避免使用它,并且这并不总是可能的(it is not always possible)。我们在每个残差块中的卷积层之间增加一个dropout层(图1d),并且在ReLU之后去对下一个残差块内的BN进行扰动,防止它过拟合(after ReLU to perturb batch normalization in the next residual block and prevent it from overfitting)。在非常深的残差网络中,这应该有助于解决特征重用问题(In very deep residual networks that should help deal with diminishing feature reuse problem enforcing learning in different residual blocks)。
3. 实验结果
对于实验,我们选择著名的CIFAR-10、CIFAR-100、SVHN和ImageNet图像分类数据集。CIFAR-10和CIFAR-100数据集包含32x32的彩色图像,50000张训练图片,10000张测试图片。对于数据增强,我们使用水平翻转和随机裁剪(首先在图片的各个边填充4个像素,再随机裁剪,填充的像素值采用reflections of original image)。我们不使用参考文献9中的heavy数据增强。SVHN是谷歌的一个数据集,大概包含600000张图片。对于SVHN上的实验,不进行任何预处理(除了像素值除以255)。除ImageNet外的实验都采用ResNet_v2中的预激活残差块,我们将这组实验作为基线。对于ImageNet,我们发现在少于100层的网络中使用预激活与否没有差异,所以我们去使用原始的ResNet架构。除了特殊说明,对于CIFAR,我们对图片进行ZCA白化处理。但是对于一些CIFAR实验,我们只是用简单的mean/std标准化,这样我们能够直接与参考文献13进行对比。其他的残差网络相关工作根据对比决定是否需要。
在下面,我们描述了WRN架构并且分析了WRN的性能。
CIFAR上的实验
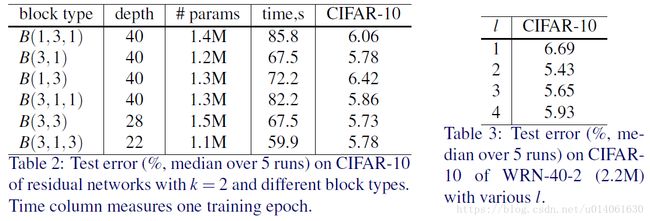
几种方案差别不大,B(3,3)能稍微好点,就选B(3,3)
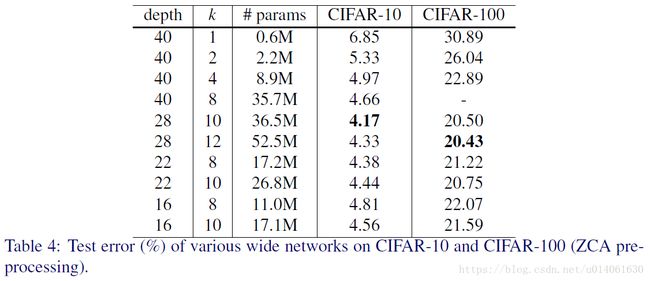
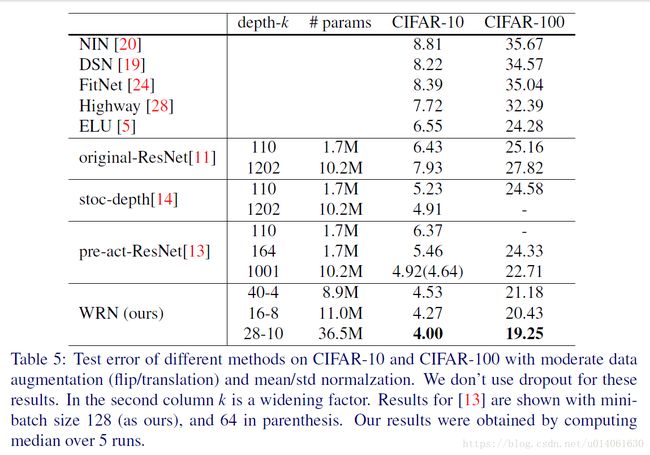
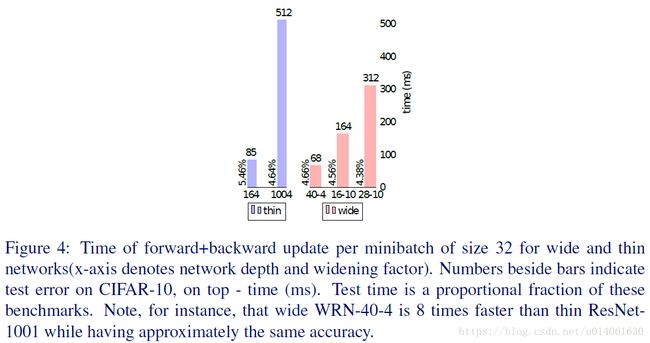
WRN40-4与ResNet1001结果相似,参数数量相似,但是前者训练快8倍。
总结:
1. 宽度的增加提高了性能
2. 增加深度和宽度都有好处,直到参数太大,regularization不够
3. 相同参数时,宽度比深度好训练
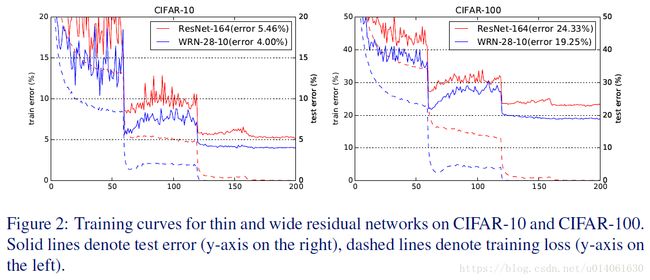
ResNet-164不如WRN28-10了
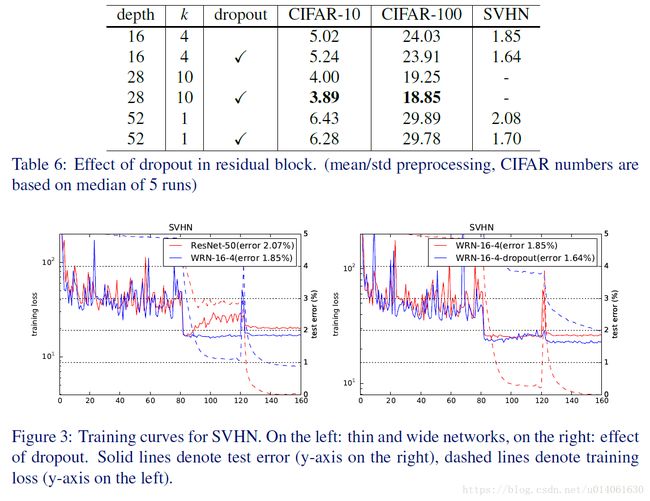
在卷积层之间加dropout确实能提高性能
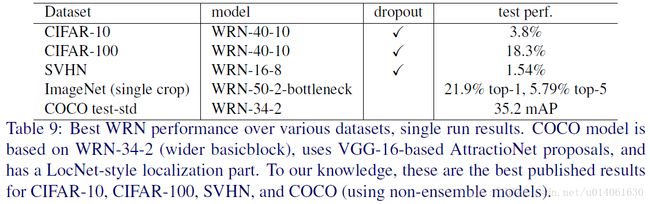
ImageNet和COCO上的实验
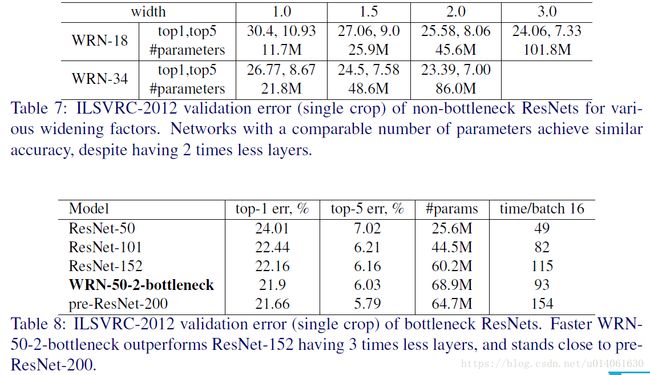
计算效率
WRN简介:https://blog.csdn.net/bea_tree/article/details/51865100