Spark Streaming整合Flume的两种方式
Spark Streaming整合Flume的两种方式
整合方式一:基于推
1、flume和spark一个work节点要在同一台机器上,flume会在本机器上通过配置的端口推送数据
2、streaming应用必须先启动,receive必须要先监听推送数据的端口后,flume才能推送数据
a、pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.kinglone</groupId>
<artifactId>scala-train</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
</properties>
<dependencies>
<!--Scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${
scala.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>${
spark.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_2.11</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>net.jpountz.lz4</groupId>
<artifactId>lz4</artifactId>
<version>1.3.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${
project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.6</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<!-- If you have classpath issue like NoDefClassError,... -->
<!-- useManifestOnlyJar>false</useManifestOnlyJar -->
<includes>
<include>**/*Test.*
**/ *Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${
scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
b、FlumePushWordCount 代码
package com.kinglone.streaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{
Seconds, StreamingContext}
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
if(args.length != 2){
System.err.println("Usage: FlumePushWordCount " )
System.exit(1)
}
val Array(hostname,port) = args
//val sparkConf = new SparkConf().setMaster("local[2]").setAppName("FlumePushWordCount")
val sparkConf = new SparkConf()
val ssc = new StreamingContext(sparkConf,Seconds(5))
val flumeStream = FlumeUtils.createStream(ssc,hostname,port.toInt)
flumeStream.map(x => new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
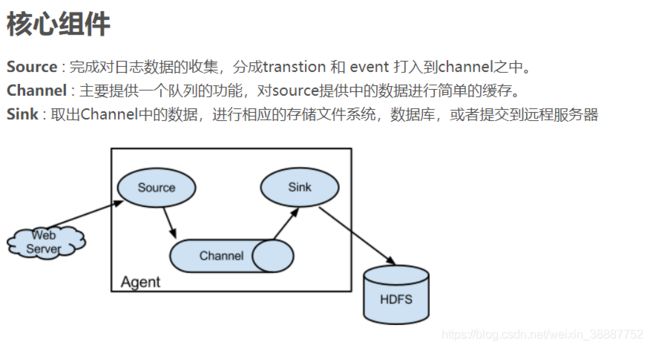
c、配置Flume
vim flume_push_streaming.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat -- 监听资源(日志等)
a1.sources.r1.bind = hadoop01
a1.sources.r1.port = 5900
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop01 -- 从channels中取出数据
a1.sinks.k1.port = 5901
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
d、在服务器上运行
用maven打包工程
使用saprk-submit提交
开启flume
发送模拟数据
验证
1)打包工程
mvn clean package -DskipTest
2)spark-submit提交(这里使用local模式)
./spark-submit --class com.kinglone.streaming.FlumePushWordCount /
--master local[2] /
--packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 /
/opt/script/flumePushWordCount.jar hadoop01 5901
3)开启flume
./flume-ng agent --name a1 --conf $FLUME_HOME/conf
--conf-file $FLUME_HOME/conf/flume_push_streaming.conf
-Dflume.root.logger=INFO,console
4)发送模式数据
这里使用本地5900端口发送数据
telnet hadoop01 5900
5)验证
查看streaming应用程序是否能出现对应的单词计数字样
注:–name a1 指flume中配置的agent 的name


整合方式一:基于拉(常用)
注意事项
1、先启动flume
2、使用自定义的sink,streaming主动去拉取数据,数据会先存放在缓冲区
3、事务保障机制,副本机制和数据被接收(Transactions succeed only after data is received and replicated by Spark Streaming.)
4、高容错保证
添加如下依赖
groupId = org.apache.spark
artifactId = spark-streaming-flume-sink_2.11
version = 2.2.0
groupId = org.scala-lang
artifactId = scala-library
version = 2.11.8
groupId = org.apache.commons
artifactId = commons-lang3
version = 3.5
配置Flume
和前面差别在配置sink,需要使用自定义的sink
vim flume_pull_streaming.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = hadoop01
a1.sources.r1.port = 5900
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = hadoop01
a1.sinks.k1.port = 5901
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
在服务上运行
业务逻辑大致和前面一样,这里使用下面的类
import org.apache.spark.streaming.flume._
val flumeStream = FlumeUtils.createPollingStream(streamingContext, [sink machine hostname], [sink port])
提交
思路如下:
用maven打包工程
mvn clean package -DskipTests
开启flume
./flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/flume_pull_streaming.conf -Dflume.root.logger=INFO,console
使用saprk-submit提交
./spark-submit --class com.kinglone.streaming.FlumePullWordCount --master local[2] --packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 /opt/script/flumePullWordCount.jar hadoop01 5901
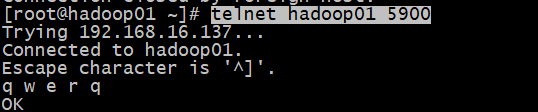
发送模拟数据
telnet hadoop01 5900
验证

注:
flume使用pull方式整合Streaming问题: Unable to load sink type: org.apache.spark.streaming.flume.sink.SparkSin
解决方式:
将从pom加载的spark-streaming-flume-sink_2.11-2.2.0.jar包,拷贝到flume的lib目录下,重新运行,即可