Lecture 10 Natural Language Generation(NLG)
Natural Language Generation(NLG)
LMS and decoding algorithms
文本生成的主要目的就是希望生成一段新的文本,它所涵盖的方向很广,主要包含以下几个NLP的子领域:
- Machine Translation
- Abstractive Summarization
- Dialogue
- Creative writing
- Freeform Question Answering
- Image captioning
- …
Language Modeling
语言建模型的主要就是为了在每个时刻根据已生成的部分来预测下一个词,即计算条件概率 P ( y t ∣ y 1 , . . . , y t − 1 ) P(y_{t}|y_{1},...,y_{t-1}) P(yt∣y1,...,yt−1)。如果语言建模过程是是基于RNN的,那么也可以称为RNN-LM。
如果在预测下一个词时不只是依赖于已生成的部分,同时还依赖于输入 x x x,那么这样的建模过程称为条件语言建模,即计算条件概率 P ( y t ∣ y 1 , . . . , y t − 1 , x ) P(y_{t}|y_{1},...,y_{t-1},x) P(yt∣y1,...,yt−1,x)。例如在NMT中,得到目标语言的过程不仅 x x x代表源语言语句;在文本摘要中, x x x代表输入语句。
传统的基于RNN建模过程如下所示

decoding algorithm
解码算法复杂解决在文本生成过程中根据什么原则来选择最终的预测词,常见的有:
- Greedy decoding
- Beam search
- Sampling-based decoding
- Softmax temperature
Greedy decoding思想简单,原理和普通的贪心算法是一致的,即在每个时间只考虑当前最好的选择。在文本生成任务中,即只考虑当前最有可能的词,不断的进行直到输入
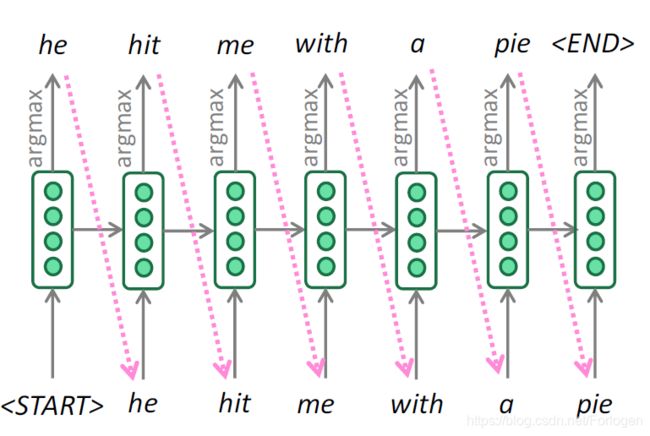
Beam search算法是一种不完全的图搜索算法,通常在图的解空间比较大的情况下使用,同时在深度遍历图的过程中会删除一些质量较差的节点,减少了空间消耗,提高了时间效率。

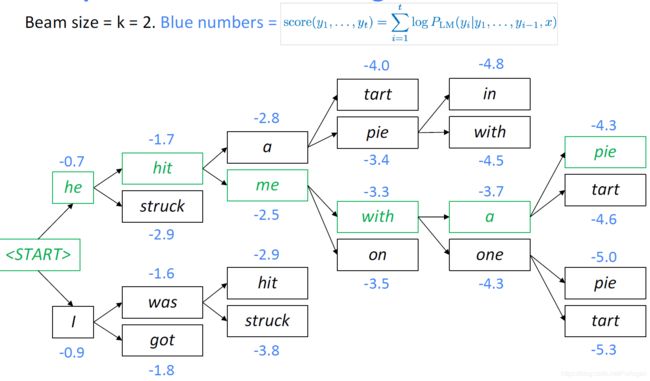
它的核心思想是在解码的每个时间步,选择K个最可能的词作为下一步的翻译,K这里称为beam size。
假设字典为[a,b,c],beam size = 2:
-
在生成第1个词的时候,选择概率最大的2个词,那么当前序列就是a或b
-
生成第2个词的时候,我们将当前序列a或b,分别与字典中的所有词进行组合,得到新的6个序列aa、 ab 、ac、 ba 、bb 、bc,然后从其中选择2个概率最高的作为当前序列,即ab或bb
-
不断重复这个过程,直到遇到结束符为止。最终输出2个概率最高的序列。
在 y 1 , . . . , y t y_{1},...,y_{t} y1,...,yt的产生过程中,每个 y i y_{i} yi都有一个分数,整个序列的得分为
score ( y 1 , … , y t ) = log P L M ( y 1 , … , y t ∣ x ) = ∑ i = 1 t log P L M ( y i ∣ y 1 , … , y i − 1 , x ) \operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\log P_{\mathrm{LM}}\left(y_{1}, \ldots, y_{t} | x\right)=\sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} | y_{1}, \ldots, y_{i-1}, x\right) score(y1,…,yt)=logPLM(y1,…,yt∣x)=i=1∑tlogPLM(yi∣y1,…,yi−1,x)
其中所有的得分都是非负的,得分越高表示越好。但是集束搜索同样不能保证找到最优的目标序列,但是比greedy decoding更加有效。
其中参数k的选取对于模型最后的效果有着很大影响,当k取值较小时,会遇到和greedy decoding相同的问题。当k取值较大时,在每一次选择序列时,面对的搜索空间就会很大,自然计算量也会随之增大。而且k取值的增大还会带来其他的问题,当在NMT中使用beam search时,k值过大反而会导致BLUE分数的下降;当在open-ended task中使用beam search时,过大的k值会得到很一般的输出。
例如在下面的例子中,当k值较小时,得到的回复看起来和主题相关,但是却是无意义的语句,并且在语法上也不成立;当k值较大时,看似得到了正确的回复,但是太过于一般化,以及相关性较差。

Sampling-based decoding通常有
- pure sampling:在每一时刻随机的从概率分布中采样作为下一个预测词
- Top-K sampling:在每一时刻随机的从概率分布中采样,但是预测词是从概率最高的K的词中选取。当n=1时相当于greedy search;当n=V(词汇表大小)时相当于pure sampling。
Softmax temperature并不是一种解码输出,只是一种可以控制输出的方式。在每一时刻t,语言模型对于向量 s s s使用softmax函数计算概率分布 p t p_{t} pt,即 P t ( w ) = exp ( s w ) ∑ w ′ ∈ V exp ( s w ′ ) P_{t}(w)= \frac{\exp(s_{w})}{\sum_{w' \in V} \exp(s_{w'})} Pt(w)=∑w′∈Vexp(sw′)exp(sw)
我们可以使用temperature这个超参数来控制softmax的输出,参数表示为 τ \tau τ,softmax的计算表示为 P t ( w ) = exp ( s w / τ ) ∑ w ′ ∈ V exp ( s w ′ / τ ) P_{t}(w)= \frac{\exp(s_{w}/ \tau)}{\sum_{w' \in V} \exp(s_{w'}/ \tau)} Pt(w)=∑w′∈Vexp(sw′/τ)exp(sw/τ)
当 τ \tau τ取值较大时,输出更加多样化;当 τ \tau τ取值较小时,自然输出的多样性就会较少。
小结

Text Summarization
文本摘要可以简单定义为:对于给定的输入文本 x x x,我们希望模型可以给出一段较短且包含文本大意的总结 y y y。按照处理文档的类型可以分为单文档和多文档。
对于单文档摘要生成来说,常用的数据集有:

与单文档摘要生成相似的一个任务是Sentence simplification,它所做的是使用更简单的语言来重写文本,常用的数据集有Simple WIkipedi和Newsela等。
从生成方式来看,文本摘要可分为:
- 抽取式(Extractive Summarization):它直接从文档中进行短语或是句子的抽取,通常较为简单,效果也较好,但是没有实现对于输入的改写
- 抽象式(Abstractive Summarization):它使用更接近人的方式来生成摘要,通常结果流畅性较好,但是有时表述和原文的相关性较差
传统的摘要生成流程如下所示

在神经网络流行之前,大多数的有关文本摘要的方法都是抽取式,通过从原文中抽取可能出现在摘要中的部分来得到结果。整体流程可以总结为: c o n t e n t s e l e c t i o n → i n f o r m a t i o n o r d e r i n g → s e n t e n c e r e a l i z a t i o n content selection \rightarrow information ordering \rightarrow sentence realization contentselection→informationordering→sentencerealization。
对应的评价指标最常用的就是ROUGE(Recall-Oriented Understudy for Gisting Evaluation),表达式为: R O U G E − N = ∑ S ∈ reference Summarization ∑ g r a m n ∈ S Count m a t c h ( g r a m n ) ∑ S ∈ reference Summarization ∑ g r a m n ∈ S Count ( g r a m n ) ROUGE-N = \frac{ \sum_{S \in \text{reference Summarization} \sum_{gram_{n} \in S} \text{Count}_{match}(gram_{n})}}{ \sum_{S \in \text{reference Summarization} \sum_{gram_{n} \in S} \text{Count}(gram_{n})}} ROUGE−N=∑S∈reference Summarization∑gramn∈SCount(gramn)∑S∈reference Summarization∑gramn∈SCountmatch(gramn)
它是文本摘要任务最常用、也最受到认可的指标,它是一个指标集合,包括一些衍生的指标,最常用的有ROUGE-n,ROUGE-L,ROUGE-SU:
- ROUGE-n:该指标旨在通过比较生成的摘要和参考摘要的n-grams(连续的n个词)评价摘要的质量。常用的有ROUGE-1,ROUGE-2,ROUGE-3
- ROUGE-L:不同于ROUGE-n,该指标基于最长公共子序列(LCS)评价摘要。如果生成的摘要和参考摘要的LCS越长,那么认为生成的摘要质量越高,不足之处在于,它要求n-grams一定是连续的
- ROUGE-SU:该指标综合考虑uni-grams(n = 1)和bi-grams(n = 2),允许bi-grams的第一个字和第二个字之间插入其他词,因此比ROUGE-L更灵活。
ROUGE作为自动评价指标,它和人工评定的相关度较高,在自动评价摘要中能给出有效的参考。但另一方面,从以上对ROUGE指标的描述可以看出,ROUGE基于字的对应而非语义的对应,生成的摘要在字词上与参考摘要越接近,那么它的ROUGE值将越高。但单一的使用ROUGE进行评估摘要的好坏也存在一些问题,ROUGE分数高的摘要可读性不一定好。
ROUGE侧重于召回率,而NMT中的BLIUE则侧重于精确率。
ROUGE: A Package for Automatic Evaluation of Summaries, Lin, 2004
有关文本摘要中的部分神经网络模型可见 :
- Development of Neural Network Models in Text Summarization - 1
- Development of Neural Network Models in Text Summarization - 2
- Development of Neural Network Models in Text Summarization - 3
- Development of Neural Network Models in Text Summarization - 4
后面有关Dialogue的部分课上将的很少,而且本身也不熟悉,后面了解了相关的内容后在针对PPT进行补充叭~