GAN 生成对抗网络
一、GAN简介
GAN:Generative Adversarial Network
Lan J.Goodfellow等于2014年10月在Generative Adversarial Network中提出的一个通过对抗过程估计生成模型的新框架。框架中同时训练两个模型:捕获数据分布的生成模型G,和估计样本来自训练数据的概率的判别模型D。
G的训练程序是将D错误的概率最大化。GAN主要针对是一种生成类问题。
目前深度学习领域的图像生成、风格迁移,图像变换,图像描述,无监督学习,甚至强化学习领域都能看到GAN的影子。
目前深度学习领域可分为两大类:
其一是检测识别,比如图像分类,目标识别等,此类模型主要有VGG,GoogLenet,residual net等,目前几乎所有的网络都是基于识别的;
其二是图像生成,即解决如何从一些数据里生成图像的问题,生成类模型主要有深度信念网络DBN、变分zibianmaqiVAE。而某种程度上,GAN的生成能力远超过DBN、VAE。经过改进后的GAN足以生成以假乱真的图像。
机器学习的模型大体可分为两类:生成模型(Generative model)和判别模型(Discriminative model)。
判别模型需要输入变量,通过某种模型来预测。
生成模型是给定某种隐含信息,来随机产生观测数据。
例:判别模型:给定一张图,判断这张图里的动物是猫还是狗
生成模型:给一系列猫的图片,生成一张新的猫咪(不在数据集中)
对于生成模型,损失函数容易定义,但对于生成模型,损失函数的定义就不那么容易,因为我们对于生成结果的期望往往模糊不清,难以用数学公理化定义其形式。所以把生成模型的回馈部分,交给判别模型处理。这就是Goodfellow他将机器学习中两大类模型:Generative和Discrimitive结合起来了。
二、GAN原理
GAN基本原理:以生成图片为例。假设我们有两个网络:G(Generator)和D(Discriminator)。他们的功能分别为:
G:一个生成图片的网络,它接收一个随机噪声z,通过这个噪声生成图片,记做G(z);
D:一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率。
如果为1,就带包100%是真实的图片,而输出为0,就代表不可能是真实图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D,而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈”。
理想状态下,G可以生成足以“以假乱真”的图片G(z)。对D来说,它难以判定G生成的图片究竟是不是真实的,这样我们的目的就达到了:我们得到了一个生成式的模型G,它可以用来生成图片。
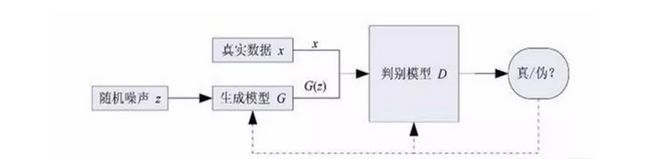
其中G为生成模型,D为判别模型。
GAN的大概流程是:G以随机噪声作为输入,生成一张图像G(z),暂且不管生成质量多好,然后D以G(z)和真实图像x作为输入,对G(z)和x做一个二分类,检测谁是真实图像,谁是生成的假图像。
D的输出是一个概率值,比如G(z)作为输入时D输出0.15,那么代表D认为G(z)有15%的概率是真图像。然后G和D会根据D输出的情况不断改进自己,G提高G(z)和x的相似度,尽可能的欺骗D,而D则会通过学习尽可能不被G欺骗。二者相当于一个极大极小的博弈过程,称为零和博弈。
用一个简单的例子描述他们之间的过程,我们把G想象成制作假币的团伙,视D为警察,G不断产生假币,而D的任务就是从真钱币中分辨出G的假币,刚开始的,G没有经验,制造的假币太假,D很容易就能分辨出来,所以G不断改进自己的技术,产生的假币越来越真实,D可能就没有那么容易判别出真假了,所以D也根据自己的情况不断改进自己,经过很多次这样的循环之后,G产生的假币足以以假乱真了,D很难分出真假。对应到图像生成上,此时G足以生成出一般的分类神经网络分辨不出真假的图像了,G从而获得了生成图像的能力。
与传统神经网络训练不一样的地方是训练生成器的方法不同,生成器参数的更新来自于D的反传递度。
![]()
这就是其损失函数的定义,其实是一个交叉熵,其中x表示真实图片,z表示输入G网络的噪声,G(z)表示G网络生成的图片,D(·)表示D网络判断图片是否真实的概率。判别器的目的是尽可能的令D(x)接近1,令D(G(z))接近0,所以D主要是最大化上面的损失函数,G恰恰相反,他主要是最小化上述损失函数。

上图展示了GAN训练的伪代码,
首先在迭代次数范围内,首先对z和x采样一个批次,获得他们的数据分布;
然后通过随机梯度下降的方法先对D做k次更新,之后对G做一次更新,这样做的目的是保障D一直有足够的能力去分辨真假。
实际在代码中我们可能会更新几次G只更新一个D,不然D学习的太好,会导致训练前期发生梯度消失的问题。
三、平衡点存在的证明
首先做个数学假设,即固定G情况下求G的最优形式,然后根据D的最优形式再去观察G最小化损失函数的问题。
假设在G固定的条件下,并将损失函数化为如下简单形式:
L = a log(y) + b log(1 - y )
D的目标是最大化L,我们可通过对L 求导,并令导数为0,计算出L 取最大值时y 的取值如下:
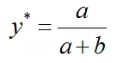
所以,D的最优解形式为:
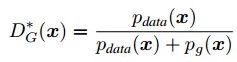
接下来在D最优时,G最小化损失函数到什么形式才能到达二者相互博弈的平衡点。
将其带入到损失函数里,损失函数可写为如下形式:
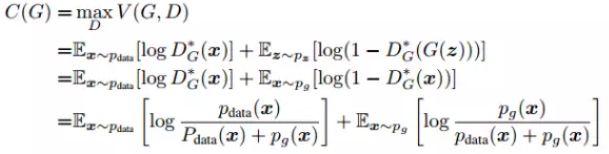
这时,你可发现上面的式子是一个相对熵,也称KL散度,KL散度通常用来衡量分布之间的距离,它是非对称的。
同样还有另一个衡量数据分布距离的散度 --- JS散度,他们之间有如下关系:
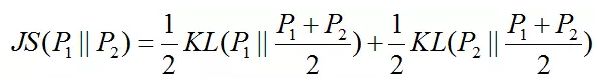
不过JS散度总是大于0的,当且尽当P1 = P2时,上面的式子取得最小值0,所以我们可以将C(G)写出JS散度的形式:

即当且尽当Pg=Pdata时,C(G)取得最小值-log(4),也即是D最优时,G能将损失函数最小化到-log(4),最小点处Pg=Pdata,即真实数据的分布和生成数据的分布相等。
Pg=Pdata意味着此时D恰好等于0.5,也就是D有一半的概率认为D(G(z))是真的数据,有一半的概率认为是假的数据,也说明此时G生成的数据足以以假乱真。
理论上GAN只要循规蹈矩的训练,G就可以完美的模拟数据分布并生成真实的图像,但是我们做数学推导时为了证明方便做了一些假设,实际上并不是这样的,GAN存在训练困难,梯度消失、模式崩溃的问题。
下面先介绍一下KL散度、JS散度和交叉熵
三者都是用来衡量两个概率分布之间的差异性的指标。不同之处在于其数学表达式形式。
对于概率分布P(x) 数据的真实分布和Q(x) 数据的理论分布、模型分布或P的近似分布
符号x的信息量定位为x出现概率的倒数,单位比特
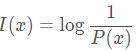
熵:平均信息量
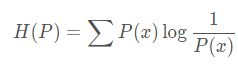
1、交叉熵(Ecross Entropy)
在神经网络中,交叉熵可作为损失函数,因为它可以衡量P和Q的相似性。

交叉熵和相对熵的关系:
![]()
2、KL散度(Kullback-Leibler divergence)
又称KL距离、相对熵、信息散度、信息增益。
KL散度是两个概率分布P和Q差别的非对称性的度量。
KL散度用来度量使用基于Q的编码来编码来自P的样本平局所需的额外的位元素。

因为对数函数都是凸函数,所以KL散度的值为非负数。当P(x)和Q(x)的相似度越高,KL散度越小。
KL散度主要有两个性质:
(1) 不对称性
尽管KL散度从直观上是个度量或距离,但它并不是一个真正的度量或距离,因为它不有对称性,即D(P||Q) !=D(Q||P)。
(2) 非负性
相对熵的值是非负值,即D(P||Q) > 0。
3、JS散度(Jensen-Shannon divergence)
也称JS距离,是KL散度的一种变形,度量了两个概率分布的相似度,解决了KL散度非对称问题。
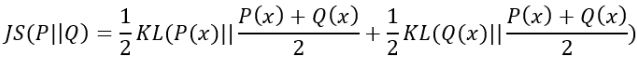
其不同于KL主要有两个方面:
(1) 值域范围
JS散度的值域范围是[0,1],相同为0,相反为1。相较于KL,对相似度的判别更确切了。
(2) 对称性
即 JS(P||Q) = JS(Q||P)
KL散度和JS散度度量的时候有一个问题:
如果两个分配P、Q离得很远,完全没有重叠的时候,那么KL散度值是没有意义的,而JS散度值是一个常数。这在学习算法中是比较致命的,这就意味合作者一点的梯度为0,梯度消失了。
以上都是基于离散分布的概率,如果是连续的数据,则需要对数据进行Probability Density Estimate来确定数据的概率分布,就不是求和而是求积分的形式进行计算。