深度学习入门简介
本博客主要用于总结自己在学习Deep Learning的一些基础知识,主要参考一些博客和机器学习相关的书籍,并加入了本人的一些理解,若有错误的地方请大家批评指定,当然也很乐意和大家讨论相关问题,欢迎大家留言。若有侵权的情况,请告知博主,本从将立即处理,谢谢!
1. 神经网络基础知识
本节讲述神经网络的一些基础知识,主要神经网络的基本结构和训练方法,反向传播算法应该是神经网络中最核心也是最难理解的部分。
1.1 概述

其中,权重(weight)用于决定输入值对输出值的贡献率,w0是一个阈值,只有输入值和权重的加权和大于一定阈值才输出1。
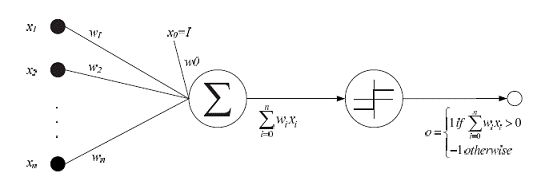

1.2 感知器法则
上述感知器的学习任务就是决定权重向量,目的是使神经网络的输出正确的标签。其中一种方法就是感知器法则。
感知器法则的原理就是随机给定权重,反复应用这个感知器到每个训练样例,只要有误分类样例就修改感知器的权值。重复这个过程,直到感知器正确分类所有的训练样例。每一步根据感知器训练法则(perceptron training rule)来修改权重。具体的法则如下:

1.3 delta法则
1.3.1 delta法则的定义

1.3.2 梯度下降法则


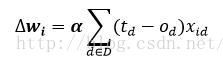
1.3.3 梯度下降的随机近似
梯度下降是一种重要的通用学习范例,所谓通用就是指该方法搜索庞大假设空间或无限假设空间的一种策略(假设空间饮食连续参数化的假设和误差对于假设参数可微)。但在实际应用中,梯度下降存在两个问题:1) 有时收敛过程可能非常慢;2) 如果在误差曲面上有多个局部极小值,无法保证这个过程会找到全局最小值。
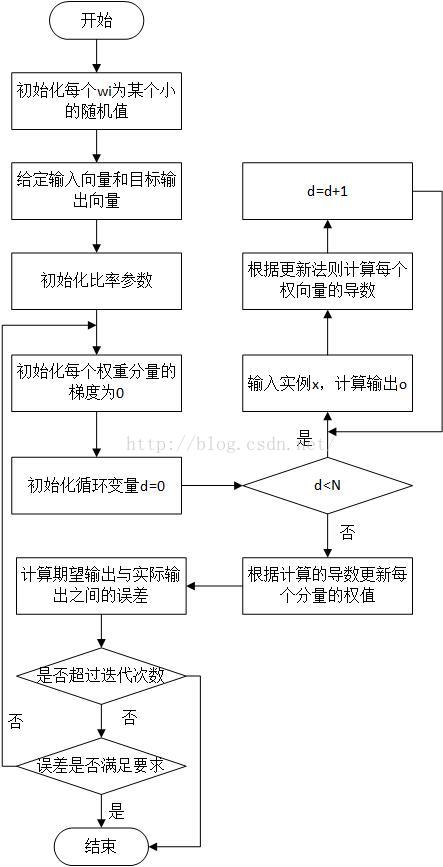
1.4 反向传播算法
1.4.1可微阈值单元

1.4.2 反射传播算法
对于一系列确定的单元互连形成的多层网络,反向传播算法可用来学习这个网络的权值。它采用梯度下降方法试图最小化网络输出值和目标值之间的误差平方。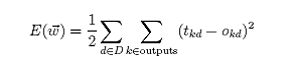
2. 特征表达与稀疏编码
2.1 特征表达
传统的机器学习方法在解决图像识别、语音识别、自然语言理解、天气预测等问题的思路都比较相似,以图像识别为例:

从传感器获取数据、预处理、特征提取、特征选择(组合)、识别(推理或预测)。而数据预处理、特征提取和特征选择可以看作是特征表达,特征表达的算法直接决定了算法的精度, 很多研究和设计都集中在这一部分。传统的特征表达一般是人工设计的完成的,比如SIFT、HOG等,这些特征可能可以解决很多图像相关的问题,但这些特征也是有局限性的,所以就有了特征选择和特征组合。
手工设计特征是一件非常费力且需要专业知识的方法,而且特征一般会有很多参数,参数的选择不仅耗费时间而且要有经验。那么能不能从数据中学习一些特征呢,Deep Learning就是一种能够从大量的数据中学习特征的方法,所以又称作Unsupervised Feature Learning。Deep Learning特征学习的原理就不得不说到讲到稀疏编码。
稀疏编码的发展来源于认知神经科学、生物学中对人脑视觉机理的发现。人们的神经系统或许是一个不断迭代、不断抽象的过程,人脑不断从原始信号做低级抽象,然后逐渐向高级抽象迭代。这也符合人类的逻辑思维方式,经常使用高度抽象的概念。例如人的视觉神经系统,从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
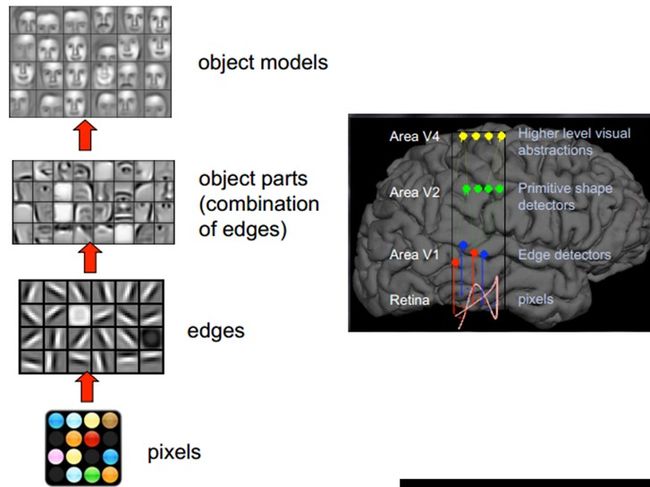
人的视觉系统的信息处理是分级的:从低级的V1区提取边缘特征,再到V2区的形状或者目标的部分等,再到更高层,整个目标和目标的行为等。也就是说,高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图;而抽象层次越高,可能的状态就越少,就越利于分类。
因些,神经系统的一个主要特征就是分层,这也就是Deep Learning要表达的内容,接下来就是特征表达了,《关于特征》这篇关于特征的解释个人觉得讲的不错,大家可以参考,现在是一些个人总结。
2.2 稀疏编码
在计算机中,图像是以像素值的方式存储的,就特征而言,像素级的特征没有任何信息,所以就需要设计能够用于识别的特征。1996年Cornell大学心理学院的Bruno Olshausen和 David Field在Nature上发表了一篇题名为:“Emergence of simple-cell receptive field properties by learning a sparse code for nature images”的文章,大意是讲哺乳动物的初级视觉的简单细胞的感受野具有空域局部性、方向性和带通性(在不同尺度下,对不同结构具有选择性),和小波变换的基函数具有一定的相似性。他们提出的最大化稀疏编码假说,成功描述了上述初级视觉细胞感受野的性质。
他们收集了很多黑白风景照片,从这些照片中,提取出400个小碎片,每个照片碎片的尺寸均为 16x16 像素,不妨把这400个碎片标记为 S[i], i = 0,.. 399。接下来,再从这些黑白风景照片中,随机提取另一个碎片,尺寸也是 16x16 像素,不妨把这个碎片标记为 T。 他们提出的问题:如何从这400个碎片中,选取一组碎片,通过叠加的办法,合成出一个新的碎片,而这个新的碎片,应当与随机选择的目标碎片 T,尽可能相似,同时,S[k] 的数量尽可能少。用数学的语言来描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
为了解决这个问题,他们提出了稀疏编码(Sparse Coding)算法。算法的过程比较简单,采用重复迭代的策略,每次迭代分两步:
1)选择一组S[k],然后调整a[k],使得Sum_k (a[k] * S[k])最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
最终的结果与之前的生理发现不谋而合,复杂图形,往往由一些基本结构(不同物体的边缘线)组成。
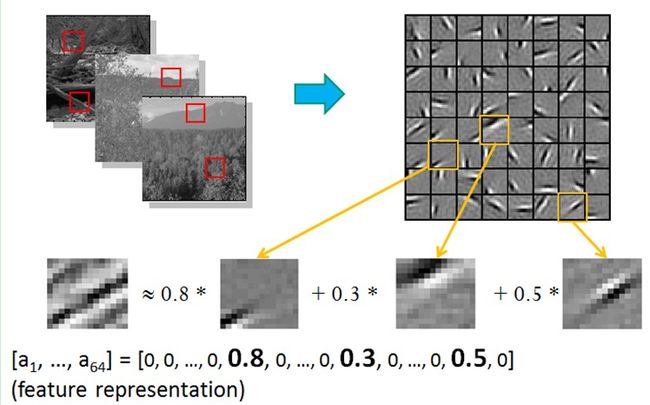
这就是稀疏编码的来源,相当于视觉系统中的V1层。具体的原理就比较复杂了,大家可以参考《稀疏编码(Sparse Coding)的前世今生》。
3. 深度学习的特征表达
稀疏编码对图像块的表达(由基础的edge表示)相当于视觉系统的V1层,那么更抽象层的表达就需要用到Deep Learning。从原理上讲,Deep Learning的每一层都可以看作低一层的图像块的组合,比如从脸的抽象过程:像素、边缘、部分(鼻子、眼睛、眉毛等)、目标(人脸)。而不同的目标,最底层的边缘是非常相似的,而边缘的上层抽象,不同的目标类型差别就比较大了。

对于Deep Learning的特征表达来说,一个最重要的参数就是层数和每一层的特征个数。对于机器学习的方法,特征越多,有用的信息就越多,准确性会得到提升。但特征多意味着探索的空间大,计算复杂,需要大量的训练数据,并不一定特征越多越好。
4. 总结和感想
这些对于深度学习入门应该差不多了,可能有一些疏忽的地方和错误的地方,本人才疏学浅,敬请见谅。
终于写完了,之前没有这么系统地总结一下,写完收获还是挺多的,如果能够帮到大家那就太荣幸了。
五、参考文献
(1) BP人工神经网络的介绍与实现
http://www.cnblogs.com/luxiaoxun/archive/2012/12/10/2811309.html
(2) Tom M.Mitchell著,曾华军等译,机械工业出版社出版,机器学习
(3) Deep Learning(深度学习)学习笔记整理系列
http://blog.csdn.net/zouxy09/article/details/8775360
(4) 稀疏编码
http://deeplearning.stanford.edu/wiki/index.php/%E7%A8%80%E7%96%8F%E7%BC%96%E7%A0%81
(5) 稀疏编码(Sparse Coding)的前世今生
http://blog.csdn.net/marvin521/article/details/8980853