第90讲,Spark streaming基于kafka 以Receiver方式获取数据 原理和案例实战
有兴趣想学习国内整套Spark+Spark Streaming+Machine learning最顶级课程的,可加我qq 471186150。共享视频,性价比超高!
1:SparkSteaming基于kafka获取数据的方式,主要有俩种,即Receiver和Derict,基于Receiver的方式,是sparkStreaming给我们提供了kafka访问的高层api的封装,而基于Direct的方式,就是直接访问,在sparkSteaming中直接去操作kafka中的数据,不需要前面的高层api的封装。而Direct的方式,可以对kafka进行更好的控制!同时性能也更好。
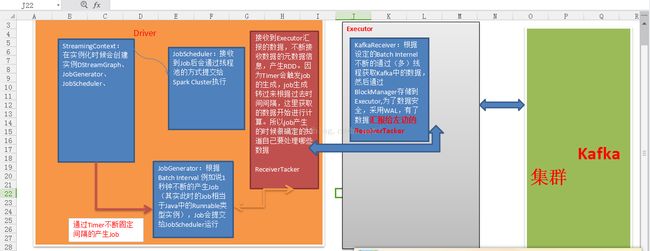
2:实际上做kafka receiver的时候,通过receiver来获取数据,这个时候,kafka receiver是使用的kafka高层次的comsumer api来实现的。receiver会从kafka中获取数据,然后把它存储到我们具体的Executor内存中。然后spark streaming也就是driver中,会根据这获取到的数据,启动job去处理。
3:注意事项:
1)在通过kafka receiver去获取kafka的数据,在正在获取数据的过程中,这台机器有可能崩溃了。如果来不及做备份,数据就会丢失,切换到另外一台机器上,也没有相关数据。这时候,为了数据安全,采用WAL的方式。write ahead log,预写日志的方式会同步的将接收到的kafka数据,写入到分布式文件系统中。但是预写日志的方式消耗时间,所以存储时建议Memory_and_Disc,不要2.如果是写到hdfs,会自动做副本。如果是写到本地,这其实有个风险,就是如果这台机器崩溃了,再想恢复过来,这个是需要时间的。
2):我们的kafka receiver接收数据的时候,通过线程或者多线程的方式,kafka中的topic是以partition的方式存在的。sparkstreaming中的kafka receiver接收kafka中topic中的数据,也是通过线程并发的方式去获取的不同的partition,例如用五条线程同时去读取kafka中的topics中的不同的partition数据,这时你这个读取数据的并发线程数,和RDD实际处理数据的并发线程数是没任何关系的。因为获取数据时都还没产生RDD呢。RDD是Driver端决定产生RDD的。
3)默认情况下,一个Executor中是不是只有一个receiver去接收kafka中的数据。那能不能多找一些Executor去更高的并发度,就是使用更多的机器去接收数据,当然可以,基于kafa的api去创建更多的Dstream就可以了。很多的Dstream接收kafka不同topics中的不同的数据,最后你计算的时候,再把他优联就行了。其实这是非常灵活的,因为可以自由的组合。
kafka + spark streaming 集群
前提:
spark 安装成功,spark 1.6.0
zookeeper 安装成功
kafka 安装成功
启动集群和zookeeper和kafka
步骤:
1:创建topic为test
kafka-topics.sh --create --zookeeper master1:2181,work1:2181,work2:2181 --replication-factor 3 --partitions 1 --topic test
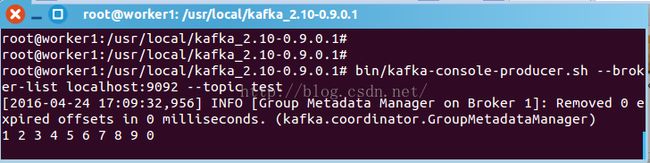
在worker1中启动kafka 生产者:
root@worker1:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
在worker2中启动消费者:
root@worker2:/usr/local/kafka_2.10-0.9.0.1# bin/kafka-console-consumer.sh --zookeeper master1:2181 --topic test

生产者生产的消息,消费者可以消费到。说明kafka集群没问题。进入下一步。
在master中启动spark-shell
./spark-shell --master local[2] --packages org.apache.spark:spark-streaming-kafka_2.10:1.6.0
笔者用的spark 是 1.6.0 ,读者根据自己版本调整。
shell中的逻辑代码(wordcount),启动完成,把下面代码直接丢进去:
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Durations, StreamingContext}
val ssc = new StreamingContext(sc, Durations.seconds(5))
// 第二个参数是zk集群信息,zk的client host:port,生动的说明了kafka读取数据获取offset
//等元数据等信息,是从zk里面获取的。所以要连zk
// 第三个参数是Consumer groupID,随便写的
//第4个参数是消费的topic,以及并发读取topic中Partition的线程数,这个Map指定了你
//要消费什么topic,以及怎么消费topic
KafkaUtils.createStream(ssc, "master:2181,worker1:2181,worker2:2181", "StreamingWordCountSelfKafkaScala", Map("test" -> 1)).map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
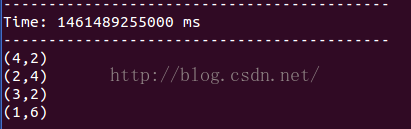
生产者再生产消息:

spark streaming的反应:
返回worker2查看消费者

可见,groupId不一样,相互之间没有互斥。
上述是使用 createStream 方式链接kafka
还有更高效的方式,请使用createDirectStream
参考:
http://spark.apache.org/docs/latest/streaming-kafka-integration.html