深度可分离卷积Depthwise Separable Convolution
从卷积神经网络登上历史舞台开始,经过不断的改进和优化,卷积早已不是当年的卷积,诞生了分组卷积(Group convolution)、空洞卷积(Dilated convolution 或 À trous)等各式各样的卷积。今天主要讲一下深度可分离卷积(depthwise separable convolutions),这是 Xception 以及 MobileNet 系列的精华所在。
对于卷积来说,卷积核可以看做一个三维的滤波器:通道维+空间维(Feature Map 的宽和高),常规的卷积操作其实就是实现通道相关性和空间相关性的联合映射。Inception 模块的背后存在这样的一种假设:卷积层通道间的相关性和空间相关性是可以退耦合的,将它们分开映射,能达到更好的效果。
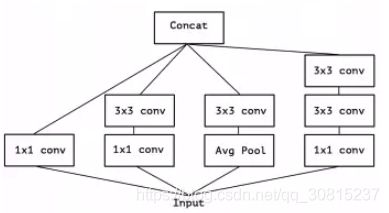
上图是一个典型的 Inception 模块,它先在通道相关性上利用 1×1 卷积将输入的 Feature Map 映射到几个维度比原来更小的空间上,相当于每个通道图乘上不同的因子做线性组合,再用 3×3 卷积这些小空间,对它的空间和通道相关性同时做映射。以第二个分支为例,假设 Input 是 28×28×192 的 Feature Maps,在通道相关性上利用 32 个 1×1×192 的卷积核做线性组合,得到 28×28×32 大小的 Feature Maps,再对这些 Feature Maps 做 256 个 3×3×32 的卷积,即联合映射所有维度的相关性,就得到 28×28×256 的 Feature Maps 结果。可以发现,这个结果其实跟直接卷积 256 个3×3×192 大小的卷积核是一样。也就是说,Inception 的假设认为用 32 个 1×1×192 和 256 个 3×3×32 的卷积核退耦级联的效果,与直接用 256个 3×3×192 卷积核等效。而两种方式的参数量则分别为32×1×1×192 + 256×3×3×32 = 79872 和 256×3×3×192 = 442368。
下图是简化后的 Inception 模块(仅使用3×3卷积并去除 Avg pooling),基于该简化模块可以将所有的 1×1 卷积核整合成一个大的 1×1 卷积。如将 3 组 32 个 1×1×192 的卷积核重组为 96个 1×1×192 的卷积核,后续再接3组 3×3卷积, 3×3卷积的输入为前序输出的1/3,如右下图: ,
,
Xception 论文进而提出在此的基础上,做出进一步的假设:通道相关性和空间相关性是完全可分的,由此得到下图中的 “extreme” Inception。先进行 1×1 的通道相关性卷积,后续接的 3×3 卷积的个数与 1×1 卷积的输出通道数相同。

Figure 4 中的 Inception 模块与本文的主角-深度可分离卷积就近乎相似了,但仍然存在两点区别:
1、深度可分离卷积先进行 channel-wise 的空间卷积,再进行1×1 的通道卷积,Inception则相反;
2、Inception中,每个操作后会有一个ReLU的非线性激活,而深度可分离卷积则没有。
从常规卷积 -> 典型的Inception -> 简化的Inception -> “极限”Inception,实际上是输入通道分组的一个变化过程。常规卷积可看做将输入通道当做整体,不做任何分割;Inception则将通道分割成3至4份,进行1×1的卷积操作;“极限”Inception则每一个通道都对应一个1×1的卷积。
深度可分离卷积
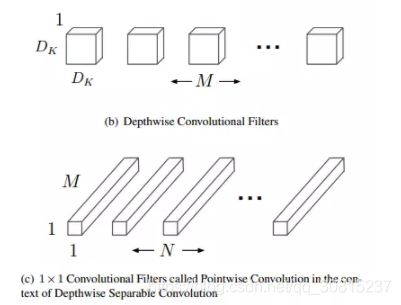
深度可分离卷积将传统的卷积分解为一个深度卷积(depthwise convolution)+ 一个 1×1的卷积(pointwise convolution)。如下图所示,(a)是传统卷积,(b)、(c)分别对应深度可分离卷积的深度卷积和 1×1的卷积:
 ,
,
例如:
输入图像W*H*M,对于深度分离卷积,把标准卷积(4,4,M,5)分解为:
- 深度卷积部分:大小为(4,4,1,M) ,作用在输入的每个通道上,输出特征映射为(W*H*M)
- 逐点卷积部分:大小为(1,1,M,5),作用在深度卷积的输出特征映射上,得到最终输出为(W,H,5)
假设输入特征图大小为 ![]() ,输出特征图大小为
,输出特征图大小为 ![]() ,卷积核大小为
,卷积核大小为 ![]() ,则传统卷积的计算量为:
,则传统卷积的计算量为:![]() (这里的D_F指的是输出的特征图的尺寸吧???)
(这里的D_F指的是输出的特征图的尺寸吧???)
深度可分离卷积的计算量为深度卷积和 1×1 卷积的计算量之和:
![]()

深度可分离卷积与传统卷积的计算量之比为:
![]()
以上文中 28×28×192 的输入,28×28×256 的输出为例,卷积核大小为 3×3,两者的计算量之比为:
![]()
深度可分离卷积的计算量缩减为传统卷积的 1/9 左右。下图是传统卷积(左)与MobileNet中深度可分离卷积(右)的结构对比。Depth-wise卷积和1×1卷积后都增加了BN层和ReLU的激活层。

from :https://www.jianshu.com/p/38dc74d12fcf?utm_source=oschina-app
把标准卷积(4,4,3,5)分解为:
- 深度卷积部分:大小为(4,4,1,3) ,作用在输入的每个通道上,输出特征映射为(3,3,3)
- 逐点卷积部分:大小为(1,1,3,5),作用在深度卷积的输出特征映射上,得到最终输出为(3,3,5)
例中深度卷积卷积过程示意图如下:

输入有3个通道,对应着有3个大小为(4,4,1) 的深度卷积核,卷积结果共有3个大小为(3,3,1) ,我们按顺序将这卷积按通道排列得到输出卷积结果(3,3,3) 。

from:https://blog.csdn.net/qq_21997625/article/details/87106152