Linux HA Cluster-Corosync+Pacemaker
Linux HA Cluster Corosync+Pacemaker
关于基本概念的内容都在上一篇博客中,此处不再赘述!
HA:
Message Layer:
heartbeat,corosync,cman,keepalive
CRM:
haresources,crm,pacemaker,rgmanager
LEM
RA:
heartbeat legacy,lsb,ocf,stonith
资源的类型:
primitive(native),group,clone,master/slave
资源的约束方式:
location,colocation,order
CIB:Cluster Information Base
cib.xml 存储集群配置信息的文件的格式;
其在heartbeat中的路径为:/var/lib/heartbeat/
我们可以通过直接编辑.xml的配置文件来设置集群属性,但是有的人可能不会XML的语法,这样的话编辑起来就会比较吃力;但是不用担心,我们可以通过各种命令行接口工具或GUI工具来直接设置集群属性,然后这些工具可以自动生成XML格式的配置信息并将其写到.xml的配置文件中;
DC:Designation Coordinator
一般配置信息都会首先在DC上实现,然后通过DC通知给其他进群成员;
高可用集群架构层;
Messaging and Infrastructure Layer(HeartBeat Layer)
1.发送心跳信息,通知其他节点自己的状态信息;
2.传递集群事务状态信息;
Membership Layer
1.计算集群中的所有状态信息,构建成员关系视图,然后将信息同步给其他节点成员;
2. Cluster Consensus Membership(CCM):为较高层的集群组件提供了一个有组织的集群拓扑概述;
Resource Allocation Layer
CRM:管理集群资源
CIB:运行于内存中的XML格式的保存了全部集群配置和状态信息的组件;
在集群中的所有CRM中会选举出一个DC,由DC维护一个主CIB;修改CIB中集群配置信息只能在DC上,然后再由DC同步给其他CRM中的CIB;
PE:Policy Engine 只存在于DC中;
集群改变时的策略,决定集群的某个节点出现问题后takeover到哪个节点上(根据设置的约束关系计算出应该选择哪个节点);并且还要将状态改变信息保存在CIB中;
TE:Transition Engine 只存在DC中;
将PE生成的策略发送给其他CRM;
LRM:接收CRM的指令,通知指定的RA去执行;
Resource Layer
1.包含各种资源代理(RA)
LSB,OCF等
partitioned cluster(split brain):
当集群发生分裂时,通过投票系统(vot system)决定当前节点是否有资格代表集群继续运行;
能够代表集群继续运行的为:with quorum(大于总票数的一半),否则为without quorum(小于等于总票数的一半);处于without quorum的节点可以有这几种处理方式:stopped,ignore,freeze,suicide;
以上为HeartBeat的架构;
Pacemaker Stack:
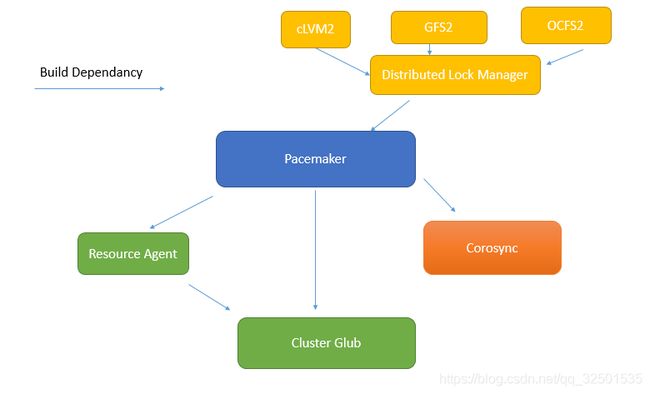
底层为提供心跳功能的corosync,pacemaker在底层还需要依赖Resource Agent和Cluster Glue这两个组件来实现将本身不具备高可用能力的资源构建成高可用服务;其中Resource Agent是依赖于Cluster Glue的;pacemaker在上层还支持集群共享文件系统:cLVM2、GFS2、OCFS2(只能在集群中使用);集群共享文件系统需要分布式锁管理器来解决多节点挂载文件系统会导致文件系统崩溃的问题;由于普通的文件系统无法同时让不同主机挂载,因为不同的主机之间是无法识别对方内核中对同一文件的锁信号的,所以当不同主机要对同一文件进行读写时,是可以被操作的,但是在文件被读写后要由各主机内存写入到磁盘中时,就会导致文件系统崩溃;在某些情况中,集群必须要共享文件系统,才能使从不同节点访问的数据是一样的(比如mysql数据库的共享),这个分布式锁管理器就可以解决上面的问题,它可以将内核对文件的锁信息通过底层的事物消息层传递给其他主机,使其了解某文件正在被使用,其他人此时无法使用;
共享存储:
NAS:Network Attached Storage,网络附加存储
在文件系统级别为其他主机提供存储,比如NFS提供的是格式化完成以后的文件系统;同时挂载同一文件系统不会导致文件系统崩溃;
SAN:Storage Area Network,存储局域网
在块级别为其他主机提供存储,输出的是未格式化的文件系统,由欲使用的主机自己格式化成自己想要的文件系统格式;同时挂载会导致文件系统崩溃;
Corosync:集群管理引擎,openAIS的一个子组件;
corosync v1没有完整的投票系统,一般会结合cman一起使用;
corosync v2具有完整的投票系统,完全可以自己独立实现运行;
Centos5:cman+rgmanager
Centos6:cman+rgmanager,corosync+pacemaker
命令行工具:
crmsh:SUSE,Centos6.5之后不再提供crmsh,欲使用,需自装;
pcs:RedHat
下载地址:http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-6/x86_64/
配置实例:首先关闭防火墙(iptables -F)
1.安装corosync+pacemaker
yum install corosync pacemaker
2.时间同步
crontab –e
*/3 * * * * /usr/sbin/ntpdate ntp.api.bz &> /dev/null
3.添加名称解析
vim /etc/hosts
192.168.80.131 clone1
192.168.80.134 clone2
4.设置ssh免密登录
ssh-keygen -t -dsa
ssh-copy-id -i ~/.ssh/id_rsa_pub root@clone2
5.配置文件
corosync默认给了一个配置文件的案例,我们可以将它复制一份命名为corosync.conf
cd /etc/corosync
cp corosync.conf.example corosync.conf
vim corosync.conf
totem {
secauth:on 打开安全信息认证功能,需执行sorority-keygen命令生成相关的秘钥文件;
threads:0 表示不使用线程模式工作,仅适用进程模式;
interface {
bindnetaddr:192.18.80.0 指定各节点所在的网段地址;
mcastaddr:239.25.12.12 指定组播地址;
mcastaddr:5405 指定组播地址监听的端口;确保你的网卡是支持组播的;
} :定义各节点通信方式;
} :定义底层信息层如何通信;
logging {
to_stderr: off 是否将日志发往标准输出,也就是终端中;
to_logfile:yes 是否记录到日志文件中;
logfile:/var/log/cluster/corosync.log 指定日志文件位置;
to_syslog:no 是否记录到rsyslog中;
} :设置其日志系统;
service {
ver: 0
name: pacemaker
use_mgmtd: yes
} :指定pacemaker以corosync插件的方式运行;
aisexec {
user: root
group: root
} :指定以什么用户和用户组的身份运行;
corosync-keygen 这个命令会使用熵池中的随机数来生成秘钥,如果随机数不够,可以通过敲击键盘或者复制文件来生成随机数,建议通过复制文件来操作,因为敲击键盘生成随机数实在是太慢了;会累死人!!!
然后会在/etc/corosync/目录中生成一个authkey的文件,权限为400;
scp -p authkey corosync.conf root@clone2:/etc/corosync/
service corosync start
ss -nutl 查看5405端口是否已经监听;
Note:上面的配置在每个节点上都要操作一遍;
grep ERROR /var/log/cluster/corosync.log
Feb 17 11:57:59 corosync [pcmk ] ERROR: process_ais_conf: You have configured a cluster using the Pacemaker plugin for Corosync. The plugin is not supported in this environment and will be removed very soon.
Feb 17 11:57:59 corosync [pcmk ] ERROR: process_ais_conf: Please see Chapter 8 of 'Clusters from Scratch' (http://www.clusterlabs.org/doc) for details on using Pacemaker with CMAN
Feb 17 11:58:00 corosync [pcmk ] ERROR: pcmk_wait_dispatch: Child process mgmtd exited (pid=3610, rc=100)
这三个错误都可以忽略
6.安装crmsh来进行集群的配置 →在一个节点上配置即可
vim /etc/yum.repos.d/suse.repo
[suse]
name=suse
baseurl=http://download.opensuse.org/repositories/network:/ha- clustering:/Stable/CentOS_CentOS-6/
enabled=1
gpgcheck=0
7.键入crm命令即可开始配置集群信息;
crm status 查看集群信息;
crm shell的使用:键入crm命令会进入crm shell
在crm shell中键入help可以查看支持的命令帮助信息;
主要的一些命令集:每个命令集中包含多个子命令,使用这些子命令进行具体的配置;
cibstatus/ CIB status management and editing CIB状态管理和编辑
cluster/ Cluster setup and management 集群设置和管理信息
configure/ CIB configuration CIB配置信息,也就是配置集群各种属性的地方
property:设置集群的各种属性
verify:检查集群配置信息是否有错
因为我们没有STONITH设备所以直接键入verify会出现错误信息,所以建议首先禁止STONITH设备:property stonith-enabled=false
show:查看配置信息
commit:提交配置信息到cib文件中,使其永久生效(因为默认的新配置的属性是保存在内存中的)
monitor:向primitive资源中添加监控器
primitive:定义一个基本资源
group:定义一个组资源
clone:定义一个克隆资源
ms:定义一个主从资源
location:定义位置约束
colocation:定义排列约束
order:定义顺序约束
history/ Cluster history 集群历史
ra/ Resource Agents (RA) lists and documentation RA列表和帮助文档
classes:显示资源类别
lsb,ocf/heartbeat pacemaker,service,stonith
list:查看指定资源类别包含的资源代理
info:查看指定资源代理的帮助信息
corosync/ Corosync management corosync管理信息
node/ Nodes management 节点管理信息
clearstate:清理指定note的状态信息
delete:删除指定节点
online:使指定节点上线
show:查看所有节点的状态信息
standby:设置指定节点为备用状态
options/ User preferences 设置使用者优先权
resource/ Resource management 资源管理信息
migrate:手动迁移资源到其他节点上
unmigrate:将其他节点上的资源迁移至本节点
restart:重启一个资源
start:启动一个资源
stop:停止一个资源
unmanage:使资源脱离集群的管理
manage:使资源可被集群管理
Note:每个命令集中的子命令可以通过键入help sub_comm来查看其使用方法;以上的crm命令也可以通过在bash中直接键入连续的命令来执行;
配置案例:HA Web Service
~]#crm configure
crm(live)configure#primitive webip ocf:heartbeat:IPaddr params ip=192.168.80.12 cidr_netmask=24
crm(live)configure# property no-quorum-policy=ignore 当配置两节点集群时,建议设置此属性,便于当一个节点宕掉的时候另一个节点还可以继续使用资源提供服务;
crm(live)configure#verify 检查配置正确性
crm(live)configure#commit 提交配置
crm(live)resource# migrate webip clone2 将资源迁移至clone2上
crm(live)configure#primitive webserver lsb:httpd
crm(live)configure#verify
crm(live)configure#commit 之所以由来一遍是因为我刚才切换出去做了一些测试
~]#crm status 查看集群信息,会发现webip和webserver这两个资源分别在不同的节点上,这是因为为了平均负载,集群默认会将资源分发到不同的节点上,但是我们的web service要求ip和httpd必须要在同个节点上啊!所以我们还要继续设置资源的约束关系,使之运行在合适的节点上以满足我们的需求;
crm(live)configure#group webservice webip webserver 将这个两个资源加入组中
~]#crm status 查看集群信息,发现资源已经在同一节点上了
当我们要删除一个资源时,首先应该停止该资源然后再进行删除:
crm(live)resource# stop webservice
crm(live)configure# delete webservice
crm(live)configure# verify
crm(live)configure# commit
Note:当我们将组删除以后,各个资源又会被分配到不同的节点上;
上面我们使用了组的方法将资源绑定在一起,现在我们使用排列约束的方式将ip和httpd绑定在一起:
crm(live)configure# colocation webip_with_webserver inf: webip webserver
crm(live)configure# verify
crm(live)configure# commit
crm(live)# status
crm(live)configure# order webip_then_webserver Mandatory: webip webserver
顺序约束:先启动webip再启动webservice
crm(live)configure# location webip_on_clone2 webip rule 50: #uname eq clone2
设置位置约束:让webip更倾向于运行在clone2上;
crm(live)configure# verify
crm(live)configure# commit
如果我们各个节点之间的优先级差别不大的话,我们不想让资源来回迁移的话,就可以通过设置资源对当前节点的粘性大于其他的优先级即可(这个粘性是相对于每个资源来说的,我下面设置的是50,如果是两个资源的话就是100,以此类推):
crm(live)configure# property default-resource-stickiness=50
crm(live)configure# verify
ERROR: Warnings found during check: config may not be valid
crm(live)configure# commit
ERROR: Warnings found during check: config may not be valid
Do you still want to commit (y/n)? y
忽略错误信息
Note:上面设置的所有属性,其实只能在整个节点出现故障以后,集群才会意识到出现问题,开始转移;当只是其中的资源出现错误时是不会进行转移的(比如httpd进程不小心被杀死了,进群是不会发现故障的);所以我们需要一个监控机制来解决这个问题;
添加监控功能:
crm(live)resource# stop webip
crm(live)resource# stop webserver
crm(live)configure# edit 编辑刚才配置的属性文件,将刚才设置的资源以及约束关系全部删除;
node clone1 \
attributes standby=off
node clone2 \
attributes standby=off
property cib-bootstrap-options: \
have-watchdog=false \
dc-version=1.1.18-3.el6-bfe4e80420 \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes=2 \
stonith-enabled=false \
no-quorum-policy=ignore \
default-resource-stickiness=50
crm(live)configure# commit
crm(live)configure# primitive webip ocf:heartbeat:IPaddr params ip=192.168.80.12 cidr_netmask=24 op monitor interval=10s timeout=20s
每十秒钟查看一次资源状态,二十秒钟还没恢复就切换到其他节点;
crm(live)configure# primitive webserver lsb:httpd op monitor interval=10s timeout=20s
同上
crm(live)configure# group webservice webip webserver
crm(live)configure# verify
crm(live)configure# commit 可以使用killall httpd实验一下,使用ss -tnl查看端口,不到十秒钟80端口就会重启,也可以使用其他(nginx)进程占用80端口,就会发现webserver会转移到其他节点;
其实还差一个共享的存储设备,我们可以通过使用nfs来提供共享目录给httpd作为其主目录,关于文件系统的资源类型可以通过 ra info ocf:heartbeat:Filesystem来查看其帮助信息,操作过程跟以上相似,动动脑壳,自己做一下!!!
注:根据马哥视频做的学习笔记,如有错误,欢迎指正;侵删;