LSTM和GRU网络的高级运用实例
接着我们看看LSTM网络更复杂的运用,那就是用来预测气温。在这个例子中,我们可以使用很多高级数据处理功能,例如我们可以看到如何使用”recurrent dropout”来预防过度拟合,第二我们会把多个LTSM网络层堆积起来,增强怎个网络的解析能力,第三我们还会使用到双向反复性网络,它会把同一种信息以不同的形式在网络内传递,从而增加网络对信息的理解。
我们首先要做的重要一步,那就是获取数据,打开迅雷,输入下面URL以便下载原始数据:
https://s3.amazonaws.com/keras-datasets/jena_climate_2009_2016.csv.zip
下载后解压,我们就可以用代码将其加载到内存中:
import os
data_dir = '/Users/chenyi/Documents/人工智能/'
fname = os.path.join(data_dir, 'jena_climate_2009_2016.csv')
f = open(fname)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
print(header)
print(len(lines))上面代码运行后结果如下:
[‘“Date Time”’, ‘“p (mbar)”’, ‘“T (degC)”’, ‘“Tpot (K)”’, ‘“Tdew (degC)”’, ‘“rh (%)”’, ‘“VPmax (mbar)”’, ‘“VPact (mbar)”’, ‘“VPdef (mbar)”’, ‘“sh (g/kg)”’, ‘“H2OC (mmol/mol)”’, ‘“rho (g/m**3)”’, ‘“wv (m/s)”’, ‘“max. wv (m/s)”’, ‘“wd (deg)”’]
420551
数据总共有420551个条目,每个条目的内容如上面显示所示。接下来我们把所有条目转换成可以被处理的数组格式:
import numpy as np
float_data = np.zeros((len(lines), len(header) - 1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
from matplotlib import pyplot as plt
temp = float_data[:, 1]
plt.plot(range(len(temp)), temp)上面代码转换数据后,将数据描绘出来,结果如下:
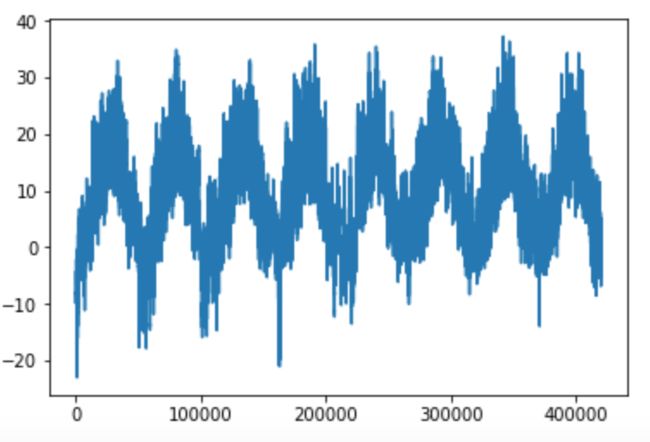
从上图可以看出,温度呈现一种周期性的变化。由于数据记录了2009年到2016年间每天的温度变化,并且温度记录是每十分钟完成一次,于是一天就有144个记录点,我们截取10天的温度信息,也就是总共1440个数据点,我们把这些数据图绘制出来看看:
plt.plot(range(1440), temp[:1440])
我们将构造一个网络,分析当前的天气数据,然后预测未来天气的可能状况。当前数据格式比较理想,问题在于不同数据对应的单位不一样,例如气温和气压采用不同的计量单位,因此我们需要对数据做归一化处理。我们打算使用前200000个数据条目做训练数据,因此我们仅仅对这部分数据进行归一化:
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std接着我们用代码把数据分成三组,一组用来训练网络,一组作为校验数据,最后一组作为测试数据:
'''
假设现在是1点,我们要预测2点时的气温,由于当前数据记录的是每隔10分钟时的气象数据,1点到2点
间隔1小时,对应6个10分钟,这个6对应的就是delay
要训练网络预测温度,就需要将气象数据与温度建立起对应关系,我们可以从1点开始倒推10天,从过去
10天的气象数据中做抽样后,形成训练数据。由于气象数据是每10分钟记录一次,因此倒推10天就是从
当前时刻开始回溯1440条数据,这个1440对应的就是lookback
我们无需把全部1440条数据作为训练数据,而是从这些数据中抽样,每隔6条取一条,
因此有1440/6=240条数据会作为训练数据,这就是代码中的lookback//step
于是我就把1点前10天内的抽样数据作为训练数据,2点是的气温作为数据对应的正确答案,由此
可以对网络进行训练
'''
def generator(data, lookback, delay, min_index, max_index, shuffle=False,
batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows), lookback//step, data.shape[-1]))
targets = np.zeros((len(rows), ))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets有了上面的数据处理函数,我们就可以调用它将原始数据分成三组,一组用于训练,一组用于校验,最后一组用于测试,代码如下:
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data, lookback=lookback,
delay=delay, min_index=0,
max_index=200000, shuffle=True,
step=step,batch_size=batch_size)
val_gen = generator(float_data, lookback=lookback,
delay=delay, min_index=200001,
max_index=300000,
step=step, batch_size=batch_size)
test_gen = generator(float_data, lookback=lookback,
delay=delay, min_index=300001,
max_index=400000,
step=step, batch_size=batch_size)
val_steps = (300000 - 200001 - lookback) // batch_size
test_steps = (len(float_data) - 300001 - lookback) //batch_size神经网络要有效,它就必须做的比人预测的准确度高。对于温度预测而言,人本能直觉会认为温度具有连续性,也就是下一刻的温度应该会比当前时刻的温度差别不了多少,根据人的经验,不可能现在温度是20度,然后下一刻温度里面变成60度,或零下20度,只有世界末日才会出现这样的情形,于是如果要让人来预测,他通常会认为接下24小时内的温度与当前温度是一样的,基于这种逻辑,我们计算一下这种预测方法的准确度:
def evaluate_naive_method():
batch_maes = []
for step in range(val_steps):
samples, targets = next(val_gen)
#preds是当前时刻温度,targets是下一小时温度
preds = samples[:, -1, 1]
mae = np.mean(np.abs(preds - targets))
batch_maes.append(mae)
print(np.mean(batch_maes))
evaluate_naive_method()上面代码运行后得到结果为0.29,注意到前面我们对数据的每一列都做了归一化处理,因此0.29的解释应该是0.29*std[1]=2.57,也就是说如果我们用前一个小时的温度来预测下一个小时的温度,那么误差是2.57度,这个误差不算小。如果我们的网络要真有效,那么它预测的温度误差应该比2.57要小,小得越多就越有效。
为了比较不同网络模型的效果,我们将分别构造几个不同类别的网络然后分别看看他们的预测效果,首先我们先建立前面几章讲过的全连接网络看看效果如何:
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Flatten(input_shape=(lookback // step,
float_data.shape[-1])))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen, steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)我们把上面代码运行结果绘制出来看看:
import matplotlib.pyplot as plt
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and Validation loss')
plt.show()上面代码运行后结果如下:

从上图看,网络预测的结果在0.4和0.3之间,也就是说网络预测的精确度还不如人的直觉好。当前网络存在一个问题,就是它把有时间次序的数据条目一下子碾平,从而使得数据之间的时间联系消失了,可是时间信息对结果的预测非常重要,如果像上面做法,先把多条数据集合在一起传入网络,就会使得数据的时间特性消失,而时间是影响判断结果的一个重要变量。
这回我们使用反复性神经网络,因为这样的网络能够利用数据间存在的时间联系来分析数据潜在规律进而提升预测的准确性,这次我们使用的反复性网络叫GRU,它是LSTM的变种,两者基本原理一样,只不过前者是对后者的优化,使得在训练时效率能够加快,我们看看相关代码:
model = Sequential()
model.add(layers.GRU(32, input_shape=(None, float_data.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen, steps_per_epoch=500,
epochs = 20, validation_data=val_gen,
validation_steps=val_steps)代码运行后,我们绘制出来的训练效果如下图:

从上图我们看到,蓝色实线在循环次数为4的时候,网络对校验数据判断的误差达到了接近0.26,这已经远远好于由人的直觉猜测的0.29错误率,这次改进相当明显。这次改进显示出深度学习对数据模式的抽取能力比人的直觉要好很多,同时也表明反复性网络对数据的识别能力要好于我们以前开发的全连接网络。0.26转换为错误值大概是2.3左右,也就是网络对一小时后的温度预测与实际值相差2.3度。
从上图我们也看出,网络对训练数据的识别准确率不断提升,对校验数据的识别准确率越来越差,两种分道扬镳很明显,也就是说网络出现了过度拟合。以前我们处理过度拟合时的办法是把权重随机清零,但是这种方式不能直接使用到反复性网络上,因为网络中很多链路权重在用于记录不同数据在时间上的内在关联,如果随机把这些权重清零,就会破坏网络对数据在时间上关联性的认识,从而造成准确率的下降。在2015年时研究贝叶斯深度学习的博士生Yarin Gal 发现了处理反复性网络过度拟合的方法,那是每次都将同样的若干比例权重清零,而不是随机清零,而这种清零机制内内嵌在keras框架中。相关代码如下:
model = Sequential()
model.add(layers.GRU(32, dropout=0.2, recurrent_dropout=0.2,
input_shape=(None, float_data.shape[-1])))
model.add(Dense(1))
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen, steps_per_epoch=500,
epochs = 40, validation_data=val_gen,
validation_steps = val_steps)上面代码运行后,网络的训练效果如下:

从上图实现和点线的发展趋势不断重合,也就是网络对校验数据的识别正确率跟训练数据的正确率一样不断提高,因此过度拟合的现象消失了。至此我们就把LSTM和GRU这两种反复性网络在具体实例上的应用展示完成,如果你运行过上面代码会发现,普通CPU的机子运行代码起来效率很慢,它再次证明了算力和数据是人工智能中两道极难迈过去的坎儿。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
