第1课:通过案例对SparkStreaming 透彻理解三板斧
1 Spark Streaming另类在线实验
16/05/01 17:00:31 INFO scheduler.DAGScheduler: ResultStage 1 ( start at OnlineBlanckListFilter.scala:40) finished in 4.234 s
16/05/01 17:00:31 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Job 0 finished: start at OnlineBlanckListFilter.scala:40, took 81.504046 s
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: Starting 1 receivers
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: ReceiverTracker started
16/05/01 17:00:32 INFO dstream.ForEachDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.MappedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.TransformedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.MappedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.SocketInputDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Initialized and validated org.apache.spark.streaming.dstream.SocketInputDStream@2f432294
16/05/01 17:00:32 INFO dstream.MappedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.MappedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.MappedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Initialized and validated org.apache.spark.streaming.dstream.MappedDStream@99b8aa7
16/05/01 17:00:32 INFO dstream.TransformedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.TransformedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.TransformedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.TransformedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.TransformedDStream: Initialized and validated org.apache.spark.streaming.dstream.TransformedDStream@7e9127a
16/05/01 17:00:32 INFO dstream.MappedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.MappedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.MappedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Initialized and validated org.apache.spark.streaming.dstream.MappedDStream@bc51cce
16/05/01 17:00:32 INFO dstream.ForEachDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.ForEachDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.ForEachDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.ForEachDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.ForEachDStream: Initialized and validated org.apache.spark.streaming.dstream.ForEachDStream@3d24c8a0
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Got job 1 (start at OnlineBlanckListFilter.scala:40) with 1 output partitions
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Final stage: ResultStage 2 (start at OnlineBlanckListFilter.scala:40)
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Parents of final stage: List()
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Missing parents: List()
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Submitting ResultStage 2 (Receiver 0 ParallelCollectionRDD[4] at makeRDD at ReceiverTracker.scala:588), which has no missing parents
16/05/01 17:00:32 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 61.2 KB, free 69.7 KB)
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: Receiver 0 started
16/05/01 17:00:32 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 20.5 KB, free 90.1 KB)
16/05/01 17:00:32 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.74.130:48586 (size: 20.5 KB, free: 152.8 MB)
16/05/01 17:00:32 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (Receiver 0 ParallelCollectionRDD[4] at makeRDD at ReceiverTracker.scala:588)
16/05/01 17:00:32 INFO scheduler.TaskSchedulerImpl: Adding task set 2.0 with 1 tasks
16/05/01 17:00:33 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 2.0 (TID 70, Worker2, partition 0,PROCESS_LOCAL, 2294 bytes)
16/05/01 17:00:33 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on Worker2:42963 (size: 20.5 KB, free: 169.6 MB)
16/05/01 17:00:33 INFO util.RecurringTimer: Started timer for JobGenerator at time 1462093260000
16/05/01 17:00:33 INFO scheduler.JobGenerator: Started JobGenerator at 1462093260000 ms
16/05/01 17:00:33 INFO scheduler.JobScheduler: Started JobScheduler
16/05/01 17:00:34 INFO streaming.StreamingContext: StreamingContext started
16/05/01 17:00:35 INFO scheduler.ReceiverTracker: Registered receiver for stream 0 from Worker2:51587
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235000 in memory on Worker2:42963 (size: 12.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235000 in memory on Worker1:40373 (size: 12.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235200 in memory on Worker2:42963 (size: 24.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235200 in memory on Worker1:40373 (size: 24.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Starting job: collect at OnlineBlanckListFilter.scala:26
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Registering RDD 6 (map at OnlineBlanckListFilter.scala:23)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Registering RDD 0 (parallelize at OnlineBlanckListFilter.scala:20)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Got job 2 (collect at OnlineBlanckListFilter.scala:26) with 2 output partitions
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Final stage: ResultStage 5 (collect at OnlineBlanckListFilter.scala:26)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 3, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 3, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[6] at map at OnlineBlanckListFilter.scala:23), which has no missing parents
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 2.3 KB, free 92.4 KB)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 1454.0 B, free 93.8 KB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.74.130:48586 (size: 1454.0 B, free: 152.8 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 3 (MapPartitionsRDD[6] at map at OnlineBlanckListFilter.scala:23)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Adding task set 3.0 with 2 tasks
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 4 (ParallelCollectionRDD[0] at parallelize at OnlineBlanckListFilter.scala:20), which has no missing parents
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 3.0 (TID 71, Worker1, partition 0,NODE_LOCAL, 2058 bytes)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_4 stored as values in memory (estimated size 1808.0 B, free 95.6 KB)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 1133.0 B, free 96.7 KB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.74.130:48586 (size: 1133.0 B, free: 152.8 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 4 (ParallelCollectionRDD[0] at parallelize at OnlineBlanckListFilter.scala:20)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Adding task set 4.0 with 2 tasks
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 4.0 (TID 72, Master, partition 0,PROCESS_LOCAL, 2028 bytes)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on Master:57087 (size: 1133.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on Worker1:40373 (size: 1454.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 3.0 (TID 73, Worker1, partition 1,NODE_LOCAL, 2058 bytes)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 3.0 (TID 71) in 171 ms on Worker1 (1/2)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 4.0 (TID 74, Worker1, partition 1,PROCESS_LOCAL, 2039 bytes)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: ShuffleMapStage 3 (map at OnlineBlanckListFilter.scala:23) finished in 0.192 s
16/05/01 17:01:01 INFO scheduler.DAGScheduler: looking for newly runnable stages
16/05/01 17:01:01 INFO scheduler.DAGScheduler: running: Set(ResultStage 2, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 5)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: failed: Set()
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 3.0 (TID 73) in 23 ms on Worker1 (2/2)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
16/05/01 17:01:02 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 4.0 (TID 72) in 620 ms on Master (1/2)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on Worker1:40373 (size: 1133.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 4.0 (TID 74) in 1412 ms on Worker1 (2/2)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: ShuffleMapStage 4 (parallelize at OnlineBlanckListFilter.scala:20) finished in 1.573 s
16/05/01 17:01:03 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
16/05/01 17:01:03 INFO scheduler.DAGScheduler: looking for newly runnable stages
16/05/01 17:01:03 INFO scheduler.DAGScheduler: running: Set(ResultStage 2)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 5)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: failed: Set()
16/05/01 17:01:03 INFO scheduler.DAGScheduler: Submitting ResultStage 5 (MapPartitionsRDD[9] at leftOuterJoin at OnlineBlanckListFilter.scala:25), which has no missing parents
16/05/01 17:01:03 INFO storage.MemoryStore: Block broadcast_5 stored as values in memory (estimated size 3.1 KB, free 99.8 KB)
16/05/01 17:01:03 INFO storage.MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 1753.0 B, free 101.5 KB)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on 192.168.74.130:48586 (size: 1753.0 B, free: 152.8 MB)
16/05/01 17:01:03 INFO spark.SparkContext: Created broadcast 5 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:03 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 5 (MapPartitionsRDD[9] at leftOuterJoin at OnlineBlanckListFilter.scala:25)
16/05/01 17:01:03 INFO scheduler.TaskSchedulerImpl: Adding task set 5.0 with 2 tasks
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 5.0 (TID 75, Master, partition 0,PROCESS_LOCAL, 2019 bytes)
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 5.0 (TID 76, Worker1, partition 1,PROCESS_LOCAL, 2019 bytes)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on Master:57087 (size: 1753.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on Worker1:40373 (size: 1753.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to Worker1:40424
16/05/01 17:01:03 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 148 bytes
16/05/01 17:01:03 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 2 to Worker1:40424
16/05/01 17:01:03 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 2 is 165 bytes
16/05/01 17:01:04 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to Master:48964
16/05/01 17:01:04 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 2 to Master:48964
16/05/01 17:01:06 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 5.0 (TID 75) in 3733 ms on Master (1/2)
16/05/01 17:01:07 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 5.0 (TID 76) in 4126 ms on Worker1 (2/2)
16/05/01 17:01:07 INFO scheduler.DAGScheduler: ResultStage 5 (collect at OnlineBlanckListFilter.scala:26) finished in 4.128 s
16/05/01 17:01:07 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 5.0, whose tasks have all completed, from pool
16/05/01 17:01:07 INFO scheduler.DAGScheduler: Job 2 finished: collect at OnlineBlanckListFilter.scala:26, took 5.896825 s
(flink,(2056 flink,None))
(uity,(4589 uity,None))
(hdaoop,(4589 hdaoop,None))
16/05/01 17:01:09 INFO scheduler.JobScheduler: Added jobs for time 1462093260000 ms
2 瞬间理解Spark Streaming本质
Spark中程序最容易出错的是流处理,流处理也是目前spark技术瓶颈之一,所以要做出一个优秀的spark发行版的话,对流处理的优化是必需的。
根据spark历史演进的趋势,spark graphX,机器学习已经发展得非常好。对它进行改进是重要的,单不是最重要的。最最重要的还是流处理,而流处理最为核心的是流处理结合机器学习,图计算的一体化结合使用,真正的实现一个堆栈rum them all .
1 流处理最容易出错
2 流处理结合图计算和机器学习将发挥出巨大的潜力
3 构造出复杂的实时数据处理的应用程序
流处理其实是构建在spark core之上的一个应用程序
代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by hadoop on 2016/4/18.
* 背景描述 在广告点击计费系统中 我们在线过滤掉 黑名单的点击 进而包含广告商的利益
* 只有效的广告点击计费
*
* 1、DT大数据梦工厂微信公众号DT_Spark
* 2、IMF晚8点大数据实战YY直播频道号:68917580
* 3、新浪微博:http://www.weibo.com/ilovepains
*/
object OnlineBlanckListFilter extends App{
//val basePath = "hdfs://master:9000/streaming"
val conf = new SparkConf().setAppName("SparkStreamingOnHDFS")
if(args.length == 0) conf.setMaster("spark://Master:7077")
val ssc = new StreamingContext(conf, Seconds(30))
val blackList = Array(("hadoop", true) , ("mahout", true), ("spark", false))
val backListRDD = ssc.sparkContext.parallelize(blackList)
val adsClickStream = ssc.socketTextStream("192.168.74.132", 9000, StorageLevel.MEMORY_AND_DISK_SER_2)
val rdd = adsClickStream.map{ads => (ads.split(" ")(1), ads)}
val validClicked = rdd.transform(userClickRDD => {
val joinedBlackRDD = userClickRDD.leftOuterJoin(backListRDD)
joinedBlackRDD.filter(joinedItem => {
if(joinedItem._2._2.getOrElse(false)){
false
}else{
true
}
})
})
validClicked.map(validClicked => {
validClicked._2._1
}).print()
ssc.start()
ssc.awaitTermination()
}16/05/01 17:00:31 INFO scheduler.DAGScheduler: ResultStage 1 ( start at OnlineBlanckListFilter.scala:40) finished in 4.234 s
16/05/01 17:00:31 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Job 0 finished: start at OnlineBlanckListFilter.scala:40, took 81.504046 s
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: Starting 1 receivers
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: ReceiverTracker started
16/05/01 17:00:32 INFO dstream.ForEachDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.MappedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.TransformedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.MappedDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.SocketInputDStream: metadataCleanupDelay = -1
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.SocketInputDStream: Initialized and validated org.apache.spark.streaming.dstream.SocketInputDStream@2f432294
16/05/01 17:00:32 INFO dstream.MappedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.MappedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.MappedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Initialized and validated org.apache.spark.streaming.dstream.MappedDStream@99b8aa7
16/05/01 17:00:32 INFO dstream.TransformedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.TransformedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.TransformedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.TransformedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.TransformedDStream: Initialized and validated org.apache.spark.streaming.dstream.TransformedDStream@7e9127a
16/05/01 17:00:32 INFO dstream.MappedDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.MappedDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.MappedDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.MappedDStream: Initialized and validated org.apache.spark.streaming.dstream.MappedDStream@bc51cce
16/05/01 17:00:32 INFO dstream.ForEachDStream: Slide time = 30000 ms
16/05/01 17:00:32 INFO dstream.ForEachDStream: Storage level = StorageLevel(false, false, false, false, 1)
16/05/01 17:00:32 INFO dstream.ForEachDStream: Checkpoint interval = null
16/05/01 17:00:32 INFO dstream.ForEachDStream: Remember duration = 30000 ms
16/05/01 17:00:32 INFO dstream.ForEachDStream: Initialized and validated org.apache.spark.streaming.dstream.ForEachDStream@3d24c8a0
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Got job 1 (start at OnlineBlanckListFilter.scala:40) with 1 output partitions
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Final stage: ResultStage 2 (start at OnlineBlanckListFilter.scala:40)
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Parents of final stage: List()
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Missing parents: List()
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Submitting ResultStage 2 (Receiver 0 ParallelCollectionRDD[4] at makeRDD at ReceiverTracker.scala:588), which has no missing parents
16/05/01 17:00:32 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 61.2 KB, free 69.7 KB)
16/05/01 17:00:32 INFO scheduler.ReceiverTracker: Receiver 0 started
16/05/01 17:00:32 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 20.5 KB, free 90.1 KB)
16/05/01 17:00:32 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.74.130:48586 (size: 20.5 KB, free: 152.8 MB)
16/05/01 17:00:32 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:1006
16/05/01 17:00:32 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 2 (Receiver 0 ParallelCollectionRDD[4] at makeRDD at ReceiverTracker.scala:588)
16/05/01 17:00:32 INFO scheduler.TaskSchedulerImpl: Adding task set 2.0 with 1 tasks
16/05/01 17:00:33 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 2.0 (TID 70, Worker2, partition 0,PROCESS_LOCAL, 2294 bytes)
16/05/01 17:00:33 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on Worker2:42963 (size: 20.5 KB, free: 169.6 MB)
16/05/01 17:00:33 INFO util.RecurringTimer: Started timer for JobGenerator at time 1462093260000
16/05/01 17:00:33 INFO scheduler.JobGenerator: Started JobGenerator at 1462093260000 ms
16/05/01 17:00:33 INFO scheduler.JobScheduler: Started JobScheduler
16/05/01 17:00:34 INFO streaming.StreamingContext: StreamingContext started
16/05/01 17:00:35 INFO scheduler.ReceiverTracker: Registered receiver for stream 0 from Worker2:51587
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235000 in memory on Worker2:42963 (size: 12.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235000 in memory on Worker1:40373 (size: 12.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235200 in memory on Worker2:42963 (size: 24.0 B, free: 169.6 MB)
16/05/01 17:00:35 INFO storage.BlockManagerInfo: Added input-0-1462093235200 in memory on Worker1:40373 (size: 24.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Starting job: collect at OnlineBlanckListFilter.scala:26
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Registering RDD 6 (map at OnlineBlanckListFilter.scala:23)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Registering RDD 0 (parallelize at OnlineBlanckListFilter.scala:20)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Got job 2 (collect at OnlineBlanckListFilter.scala:26) with 2 output partitions
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Final stage: ResultStage 5 (collect at OnlineBlanckListFilter.scala:26)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 3, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 3, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 3 (MapPartitionsRDD[6] at map at OnlineBlanckListFilter.scala:23), which has no missing parents
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_3 stored as values in memory (estimated size 2.3 KB, free 92.4 KB)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 1454.0 B, free 93.8 KB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on 192.168.74.130:48586 (size: 1454.0 B, free: 152.8 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Created broadcast 3 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 3 (MapPartitionsRDD[6] at map at OnlineBlanckListFilter.scala:23)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Adding task set 3.0 with 2 tasks
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 4 (ParallelCollectionRDD[0] at parallelize at OnlineBlanckListFilter.scala:20), which has no missing parents
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 3.0 (TID 71, Worker1, partition 0,NODE_LOCAL, 2058 bytes)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_4 stored as values in memory (estimated size 1808.0 B, free 95.6 KB)
16/05/01 17:01:01 INFO storage.MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 1133.0 B, free 96.7 KB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on 192.168.74.130:48586 (size: 1133.0 B, free: 152.8 MB)
16/05/01 17:01:01 INFO spark.SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:01 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 4 (ParallelCollectionRDD[0] at parallelize at OnlineBlanckListFilter.scala:20)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Adding task set 4.0 with 2 tasks
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 4.0 (TID 72, Master, partition 0,PROCESS_LOCAL, 2028 bytes)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on Master:57087 (size: 1133.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO storage.BlockManagerInfo: Added broadcast_3_piece0 in memory on Worker1:40373 (size: 1454.0 B, free: 169.6 MB)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 3.0 (TID 73, Worker1, partition 1,NODE_LOCAL, 2058 bytes)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 3.0 (TID 71) in 171 ms on Worker1 (1/2)
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 4.0 (TID 74, Worker1, partition 1,PROCESS_LOCAL, 2039 bytes)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: ShuffleMapStage 3 (map at OnlineBlanckListFilter.scala:23) finished in 0.192 s
16/05/01 17:01:01 INFO scheduler.DAGScheduler: looking for newly runnable stages
16/05/01 17:01:01 INFO scheduler.DAGScheduler: running: Set(ResultStage 2, ShuffleMapStage 4)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 5)
16/05/01 17:01:01 INFO scheduler.DAGScheduler: failed: Set()
16/05/01 17:01:01 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 3.0 (TID 73) in 23 ms on Worker1 (2/2)
16/05/01 17:01:01 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
16/05/01 17:01:02 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 4.0 (TID 72) in 620 ms on Master (1/2)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_4_piece0 in memory on Worker1:40373 (size: 1133.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 4.0 (TID 74) in 1412 ms on Worker1 (2/2)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: ShuffleMapStage 4 (parallelize at OnlineBlanckListFilter.scala:20) finished in 1.573 s
16/05/01 17:01:03 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 4.0, whose tasks have all completed, from pool
16/05/01 17:01:03 INFO scheduler.DAGScheduler: looking for newly runnable stages
16/05/01 17:01:03 INFO scheduler.DAGScheduler: running: Set(ResultStage 2)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 5)
16/05/01 17:01:03 INFO scheduler.DAGScheduler: failed: Set()
16/05/01 17:01:03 INFO scheduler.DAGScheduler: Submitting ResultStage 5 (MapPartitionsRDD[9] at leftOuterJoin at OnlineBlanckListFilter.scala:25), which has no missing parents
16/05/01 17:01:03 INFO storage.MemoryStore: Block broadcast_5 stored as values in memory (estimated size 3.1 KB, free 99.8 KB)
16/05/01 17:01:03 INFO storage.MemoryStore: Block broadcast_5_piece0 stored as bytes in memory (estimated size 1753.0 B, free 101.5 KB)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on 192.168.74.130:48586 (size: 1753.0 B, free: 152.8 MB)
16/05/01 17:01:03 INFO spark.SparkContext: Created broadcast 5 from broadcast at DAGScheduler.scala:1006
16/05/01 17:01:03 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 5 (MapPartitionsRDD[9] at leftOuterJoin at OnlineBlanckListFilter.scala:25)
16/05/01 17:01:03 INFO scheduler.TaskSchedulerImpl: Adding task set 5.0 with 2 tasks
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 5.0 (TID 75, Master, partition 0,PROCESS_LOCAL, 2019 bytes)
16/05/01 17:01:03 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 5.0 (TID 76, Worker1, partition 1,PROCESS_LOCAL, 2019 bytes)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on Master:57087 (size: 1753.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO storage.BlockManagerInfo: Added broadcast_5_piece0 in memory on Worker1:40373 (size: 1753.0 B, free: 169.6 MB)
16/05/01 17:01:03 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to Worker1:40424
16/05/01 17:01:03 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 1 is 148 bytes
16/05/01 17:01:03 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 2 to Worker1:40424
16/05/01 17:01:03 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 2 is 165 bytes
16/05/01 17:01:04 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 1 to Master:48964
16/05/01 17:01:04 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 2 to Master:48964
16/05/01 17:01:06 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 5.0 (TID 75) in 3733 ms on Master (1/2)
16/05/01 17:01:07 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 5.0 (TID 76) in 4126 ms on Worker1 (2/2)
16/05/01 17:01:07 INFO scheduler.DAGScheduler: ResultStage 5 (collect at OnlineBlanckListFilter.scala:26) finished in 4.128 s
16/05/01 17:01:07 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 5.0, whose tasks have all completed, from pool
16/05/01 17:01:07 INFO scheduler.DAGScheduler: Job 2 finished: collect at OnlineBlanckListFilter.scala:26, took 5.896825 s
(flink,(2056 flink,None))
(uity,(4589 uity,None))
(hdaoop,(4589 hdaoop,None))
16/05/01 17:01:09 INFO scheduler.JobScheduler: Added jobs for time 1462093260000 ms
16/05/01 17:01:09 INFO scheduler.JobScheduler: Starting job streaming job 1462093260000 ms.0 from job set of time 1462093260000 ms
下面是WEBUI展示的内容:

我们看到这里有2次真正的StreamingJOB
我们一个一个看下这些任务都是什么?
JOB 0 :
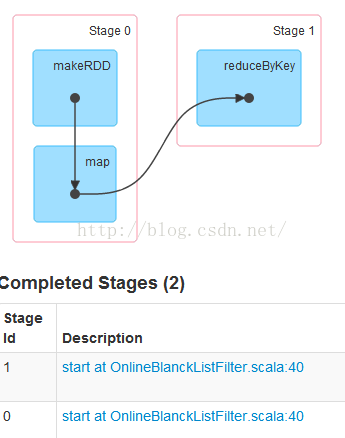
思考一个问题:这里为啥有这个任务 ,我们写的代码中并有没这些转换?
我们查看Stage0 的详情:
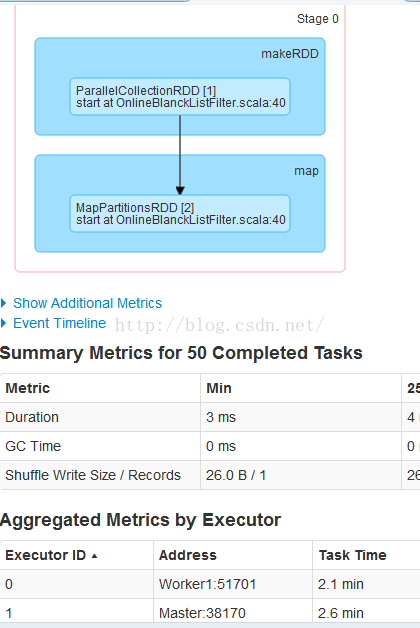
这里启动了50个JOB 我们从源码中找答案:
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map(nis => {
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
})
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
endpoint.send(StartAllReceivers(receivers))
} 我们关注 runDummySparkJob 这个方法:/**
* Run the dummy Spark job to ensure that all slaves have registered. This avoids all the
* receivers to be scheduled on the same node.
*
* TODO Should poll the executor number and wait for executors according to
* "spark.scheduler.minRegisteredResourcesRatio" and
* "spark.scheduler.maxRegisteredResourcesWaitingTime" rather than running a dummy job.
*/
private def runDummySparkJob(): Unit = {
if (!ssc.sparkContext.isLocal) {
ssc.sparkContext.makeRDD(1 to 50, 50).map(x => (x, 1)).reduceByKey(_ + _, 20).collect()
}
assert(getExecutors.nonEmpty)
}
这里启动了50个JOB,这个注释说明了这个方法是为了避免在同一个节点上启动 receivers 我们回到JOB 1:

我们继续查看详情:

我们看到这个任务是在Worker2 上执行的 而我打开Scoket 也是在Worker2 ,任务发生在数据产生的节点!!! 我们从源码中找到答案: RegisterReceiver 中的 startReceiver
// Function to start the receiver on the worker node
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) => {
if (!iterator.hasNext) {
throw new SparkException(
"Could not start receiver as object not found.")
}
if (TaskContext.get().attemptNumber() == 0) {
val receiver = iterator.next()
assert(iterator.hasNext == false)
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
} else {
// It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
}
}
// Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] =
if (scheduledLocations.isEmpty) {
ssc.sc.makeRDD(Seq(receiver), 1)
} else {
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite()))
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ()) 思考:数据的接收是一个节点上,那计算发生在哪里?