Kaggle宠物收养比赛亚军复盘
写在前面
这个比赛是在19年4月结束的,已经过去一段时间。完赛时我是季军,但后面由于冠军大哥作弊被发现并除名,我在排行榜上的位置也变成了亚军。这个比赛很有特点,是难得一见的“多模态数据”比赛,也是我唯一的Solo金牌,初学者应该能从中学到不少东西。
正文的内容其实也是去年写的,但原来是放在自己的博客里,一共也没几个人看过。后面我会把之前的一些复盘都发出来,希望可以启发到有需要的人。
赛题概况
这是一次很有意思的比赛,主办方是马来西亚的动物慈善组织PetFinder。比赛是要根据小动物的信息来预测他们多久之后会被好心人收养。这次比赛的数据种类非常的丰富,基础数据集包含了了图像数据、文本数据和结构化数据,通过不同的数据类型的组合,可以探索很多有意思的算法。而且这次比赛允许使用外部数据,只要在官方的论坛里把你使用到的数据公开给所有的参赛者,你就可以进行使用了。我一开始以为这种方式会让这个比赛变得比较蛋疼,但到最后几天我发现,通过观察排在前面队伍使用的外部数据,可以对我们自己的模型产生一些帮助:P。
 PetFinder网站,是一个收养流浪小动物的充满爱心的组织
PetFinder网站,是一个收养流浪小动物的充满爱心的组织
这道题也是一个只能用Kagge提供的kernel执行代码的比赛,GPU版kernel规定时间是两小时以内,所以对编程实现的效率也有一定的要求。
这道题的评价指标是qwk(quadratic weighted kappa,基本介绍可以看这里[1],详细介绍可以看这里[2])。这种指标是没有办法直接优化的,参考前面的crowdflower的比赛,大家通常把这种题目转换成回归问题来做,然后使用一个额外的模块去获得切分的阈值点。
公开的kernel里大多数使用了一种优化器去获得一个比较好的切分点。但在我阅读了crowdflower第一名的解题方案之后(Chenglong大神的解题报告[3])我发现,这种优化器可能没法超越直接通过训练集的分布来获得阈值点的土办法。因为可使用的所有信息都在训练集分布里了,只需要决定用还是不用。如果测试集训练集同分布的,那自然皆大欢喜,如果不同分布,也只能暗暗骂一句主办方**。所以我在最后并没有使用那些优化器而是直接把训练集的分布搬到了测试集上。
数据处理和特征工程
图像特征
首先来说一下我对图像数据的处理,我的处理方法和公开的kernel差不太多。公开kernel的做法是用预训练的模型,提取特征。由于目前常用的模型在分类器前得到的feature map维度一般很高(比如resnet50达到了2048维),比较难放进树模型;kernel里大多使用SVD对这种高维特征进行的降维,然后把降维后的数据当作特征,放到模型里训练。
我在这个基础上做了两个比较有意思的操作。一是我用一个全连接神经网络直接训练了一个基于这种高维图像特征的回归模型,直接回归得到一个y,然后进行stacking。二是我用kmeans对高维特征进行了聚类,获得了一列类别label,这组特征也对后面的建模提供了一些帮助。
曾经想过在训练这个回归器的同时也finetune backbone网络,但一方面是实在无法在规定时间里完成,另一方面发现效果其实并没有不finetune好(应该是过拟合了)。
文本特征
对于文本数据,公开的kernel里大多只采用了词频tfidf变换的方式,再结合svd获得特征。熟悉nlp的朋友应该都知道,词频特征虽然很强,但这只能获得浅层文本特征。稍微更进一步可以做一些主题模型,比如lda。但对于深层的语义信息必须用神经网络来进行提取。这道题比较有趣的是description字段文本的长度范围比较大,有的文本可以到几百个词。这对编程实现有一些技巧上的要求。
meta特征
Meta特征指数据集中用googleAPI获取的对图像和文本的分析结果,例如有图片分类的结果、描述文本的NER结果等等。在处理的时候我感觉有两点需要注意,一是尽可能全面的去读取结果json文件,然后进行特征构建,公开的kernel都只读取了小部分的内容。二是需要对处理代码做一些优化,公开kernel的实现比较缓慢。假设用kernel的写法去读取我最终使用的信息,可能这部分就要花费30分钟,我最终的代码在4分钟左右就可以完成所有操作。
统计特征和未解之谜
这道题还有一个比较有意思的地方,是一个叫rescuerID的字段,测试集合训练集中没有重叠的rescuerID。如果我们在训练模型的时候采用普通的kfold,那么验证集和训练及之间可能会有重合的ID。这样的后果就是,验证集的分数特别的高,和LB成绩有一个明显的gap。
为了避免这种情况,我在这个比赛中是全程使用了Groupkford,这种做法可以得到和测试集划分同样的不带重叠rescuerID的验证集和训练集。而且这这种方式训练时收敛的轮数会比普通kfold的少很多。而且获得的线下验证成绩跟LB成绩差的比较小。我在公开排行榜的后期,线下成绩和线上成绩基本上是完全一致的。
但我在最后提交的时候,选择了一个stratifiedkfold和一个groupkfold,结果普通kfold的成绩在B榜是略好于groupkfold的。这里不得不称赞一下Kaggle可以选两个submission的设计,可以让参赛者发挥尽可能多的实力,少留下遗憾。
对于提供的表格数据,我只进行一些非常常规的统计,没有什么特别的。在特征工程的时候,完全参考local CV来进行,只要这个特征能够提高CV成绩我就会使用它。在做CV时使用的指标主要是RMSE,QWK成绩由于不太稳定,只是作为一个辅助信息来参考。
模型
我的模型架构如下图所示,是一个比较复杂stacking的架构。第一层及以下是特征提取层,第二层是模型,第三层是融合。图像部分我用了四种ImageNet预训练分类模型来提取图片特征(图中image feature),并传入DNN进行处理获得对目标预测结果,然后将预测结果作为其他模型的特征。第二层使用了lightgbm,xgboost,catboost三种树模型,以及一个融合了文本、图像、统计特征的RNN+DeepFM网络。
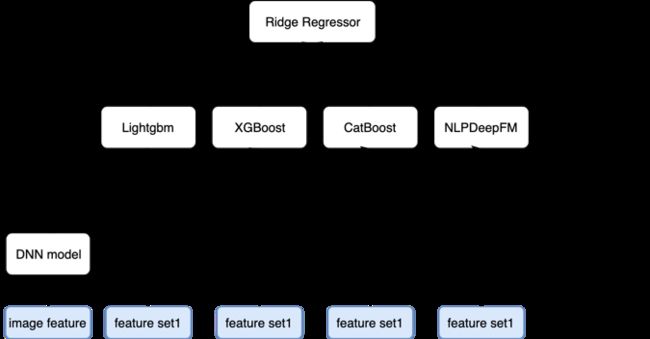 总体模型架构
总体模型架构
比较有意思的模型是那个NLPDeepFM模型,处理NLP信息的神经网络是一个双向GRU+Attention。由于表格数据里有大量的categorical列,所以我构造了一个FM来处理类别数据。对于统计特征等等其他的浮点特征则将他们直接放到网络里的DNN部分。最后将各部分的中间结果进行拼接,传入一个回归器得到最终的结果。
 NLPDeepFM细节
NLPDeepFM细节
从线下成绩来看神经网络模型虽然很复杂,但是他的能力还是和树模型有较大的差距。但是两者的差异性是比较明显的,在最后的融合过程中能带来很好的收益。最后将所有模型的结果通过一个岭回归器进行stacking。
写在最后
不得不说的是这次比赛的运气还是挺好的,因为qwk metric其实是很不稳定的。最后我的B榜排名相比A榜成绩有了非常大的提升,这个是我没有预料到的。但我在B榜的线下成绩和线上成绩是比较吻合的,这说明我原来采用的线下验证策略应该比较靠谱的。其实做比赛真的还是要尽量合理地去构建验证集,然后提高验证集的成绩,强行拟合LB没有任何意义,也学不到东西。心态也要放平,尽人事,听天命,不要有太多杂念。
最后,感谢论坛里的大神写了这么多优秀的公开kernel给我们学习。我的kernel也已经开源,感兴趣的朋友可以看这里[4]。
参考资料
[1] QWK简介: https://www.kaggle.com/c/petfinder-adoption-prediction/overview/evaluation
[2] QWK详细介绍: https://www.kaggle.com/aroraaman/quadratic-kappa-metric-explained-in-5-simple-steps
[3] CrowdFlower比赛冠军方案: https://github.com/ChenglongChen/Kaggle_CrowdFlower
[4] 我的代码: https://www.kaggle.com/wuyhbb/final-small