centos7搭建hadoop完全分布式集群
搭建步骤
1.安装centos7,并进行准备工作(可以安装一个之后然后克隆)
2.修改各个centos7的hostname和hosts
3.创建用户和用户组
4.配置centos7网络,是centos7系统之间以及和hosts主机之间可以通过互相ping通
5.安装jdk和配置环境变量,检查是否配置成功
6.配置ssh,实现节点间的无密码登录ssh node1/2指令验证时候成功
7.master配置hadoop,并将hadoop文件传输到node节点
8.配置环境变量,并启动hadoop,检查是否安装成功,执行wordcount检查是否成功
采用三台机器
主机名 ip 对应的角色
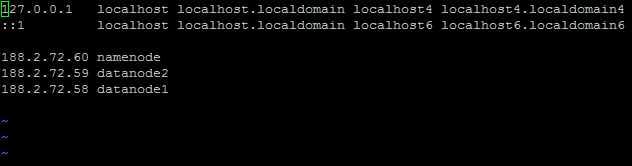
namenode 188.2.72.57 namenode(主)
datanode1 188.2.72.58 datanode1(从1)
datanode2 188.2.72.59 datanode2(从2)
由于是现有三台centos系统,所以省略安装centos系统的步骤
1.修改主机名 (以namenode举例)
hostnamectl set-hostname namenode(永久修改主机名)
reboot(重启系统)

2.修改hosts(以namenode举例)
188.2.72.60 namenode
188.2.72.59 datanode2
188.2.72.58 datanode1
![]()
3.尝试看看能不能ping通(以namenode举例)
ping -c 3 datanode1

4.准备安装oracle的jdk,但安装之前需要查看有没有安装jdk
java-version

5.查看有jdk,且是centos7系统自带的openjdk,我们需要删除掉安装oracle的jdk
rpm -qa | grep java(查询java版本)
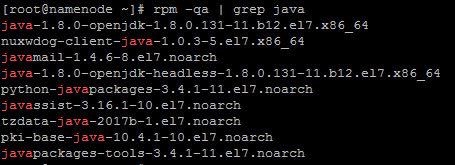
rpm -e --nodeps xxx(逐个删除完)


rpm -qa | grep java(没有显示任何)

那么就删除完了。我们可以安装oracle的jdk了
6. 来到java目录(注,我是已经提前创建了java目录跟将tar.gz包复制到了java目录中)
cd /usr/java
ls

7.解压jdk
tar zxvf jdk-8u144-linux-x64.tar.gz
ls
![]()

8. Jdk的环境变量配置
方式一:
设置环境变量,执行vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_144
export PATH=$JAVA_HOME/bin
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:${JRE_HOME}/lib

方式二:
sudo vi ~/.bashrc
![]()
在打开的文件的末尾添加以下信息:
export JAVA_HOME=/usr/java/jdk1.8.0_144
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

9. 使用source命令来使刚才的jdk环境变量配置文件生效
source ~/.bashrc
![]()
10. 在root用户下给hadoop用户增加sudo权限
chmod u+w /etc/sudoers
vi /etc/sudoers
chmod u-w /etc/sudoers
![]()
![]()
![]()
11.ssh生成密钥
ssh-keygen -t rsa(连续三次回车)

12. 切换到.ssh目录下,进行查看公钥和私钥
cd .ssh
ls

13.将id_rsa.pub复制到authorized_keys,并且给设置权限
cp id_rsa.pub authorized_keys
然后将三个authorized_keys都下载到本地,对三个authorized_keys的内容都合并,意思就是说。三台机器中的authorized_keys的内容都是相同的。
![]()
chmod 700 .ssh
chmod 600 .ssh/authorized_keys
![]()
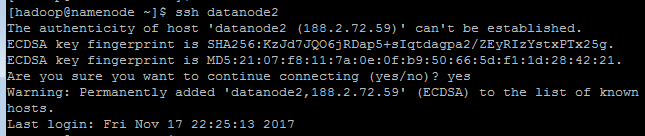
14.ssh 与别的节点无密钥连接(每个节点都需要进行连接)
ssh datanode1(连接到datanode1)
hostname(查看主机名,是否连接到)
exit(登出,不然会在连接到的机器上操作)

ssh datanode2(连接到datanode1)
hostname(查看主机名,是否连接到)
exit(登出,不然会在连接到的机器上操作)

15.hadoop环境配置
16.首先,切换到/usr/java/ ,再切换到root用户下,再 /root/java
cd /usr/java
su root
16.解压hadoop (因为之前已经将hadoop的tar.gz安装包移动过来,所以就略过移动那一步)
tar zxvf hadoop-2.7.4.tar.gz
![]()
17. 将文件名hadoop-2.7.4改为hadoop
mv hadoop-2.7.4 hadoop
ls

18. 将刚改名的hadoop文件,权限赋给hadoop用户
chown -R hadoop:hadoop hadoop
ls -l(查看权限)

19. 创建目录
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data

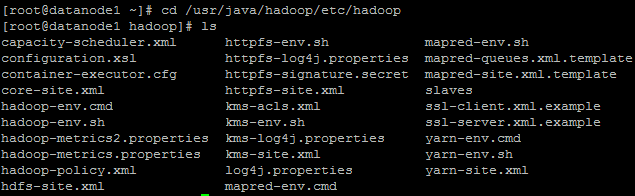
20.修改配置文件
cd /usr/java/hadoop/etc/hadoop
ls
vi hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_144
![]()

21.修改slaves
vi slaves
将里面的localhost删除,增加:
datanode1
datanode2
![]()
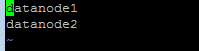
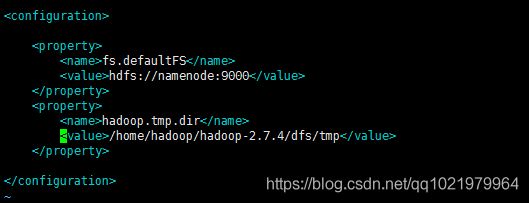
22.修改core-site.xml文件
vi core-site.xml
在
23. 新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,
复制该文件,然后改名为mapred-site.xml,命令是:
cp mapred-site.xml.template mapred-site.xml(复制文件)
vi mapred-site.xml(修改配置文件)
在
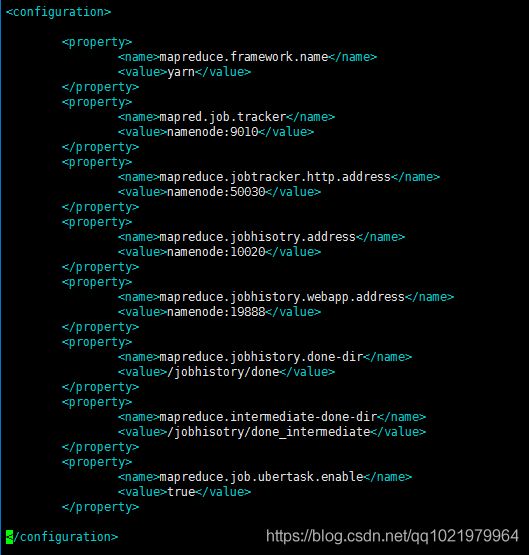
24. 修改vi hdfs-site.xml配置文件,添加以下信息
vi hdfs-site.xml
在
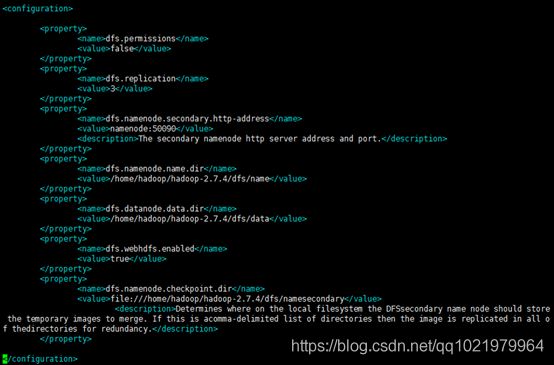
25. 修改yarn-site.xml配置文件
vi yarn-site.xml
在
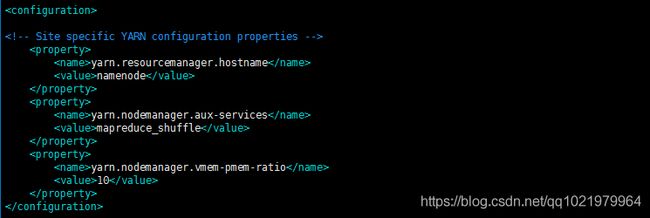
26.hadoop需要配置的文件

27.关闭防火墙
systemctl stop firewalld.service (关闭防火墙)
注:如果不关闭防火墙,可能导致无法使用集群
28.初始化namenode,因为namenode是namenode,datanode1和datanode2都是datanode,所以只需要对namenode进行初始化操作,也就是对hdfs进行格式化。
bin/hadoop namenode -format(在usr/java/hadoop目录下执行该命令)
![]()

29.启动集群
sbin/start-all.sh
30.查看集群是否启动
jps
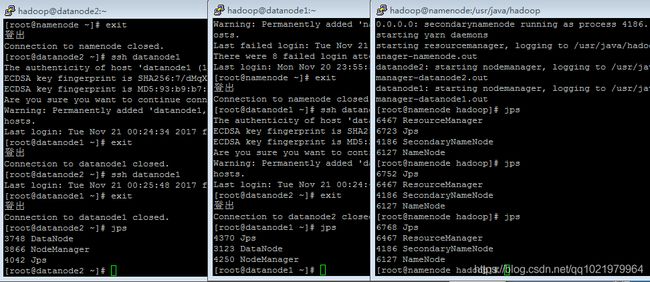
31.管理员身份运行记事本
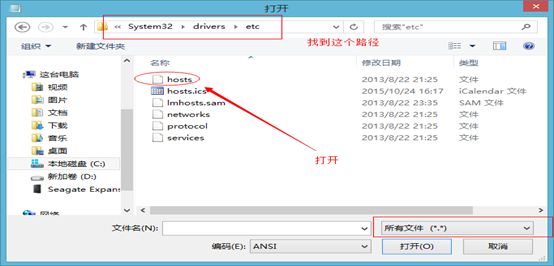
32.打开本地的host文件
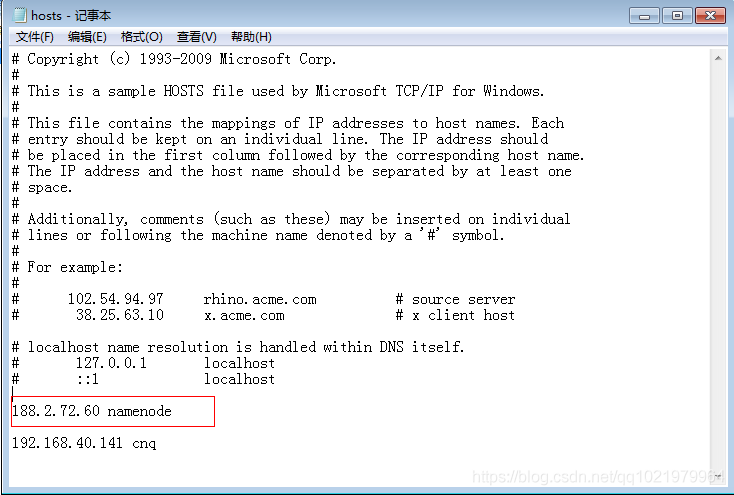
188.2.72.60 namenode
33.最后,现在是来验证hadoop是否安装成功。在Windows上可以通过 http://cnq:50070 访问WebUI来查看NameNode,集群、文件系统的状态。这里是HDFS的Web页面
http://namenode:50070
