知识表示学习 TransE 代码逻辑梳理 超详细解析
知识表示学习
网络上已经存在了大量知识库(KBs),比如OpenCyc,WordNet,Freebase,Dbpedia等等。

这些知识库是为了各种各样的目的建立的,因此很难用到其他系统上面。为了发挥知识库的图(graph)性,也为了得到统计学习(包括机器学习和深度学习)的优势,我们需要将知识库嵌入(embedding)到一个低维空间里(比如10、20、50维)。我们都知道,获得了向量后,就可以运用各种数学工具进行分析。它为许多知识获取任务和下游应用铺平了道路。
总的来说,废话这么多,所谓知识表示学习,就是将知识库给映射成向量,同时满足属于同一个三元组的(h,t,l)满足h+l≈t,而不是一个三元组的不满足这个条件。
TransE思路
TranE是一篇Bordes等人2013年发表在NIPS上的文章提出的算法。它的提出,是为了解决多关系数据(multi-relational data)的处理问题。我们现在有很多很多的知识库数据knowledge bases (KBs),比如Freebase、 Google Knowledge Graph 、 GeneOntology等等。
TransE的直观含义,就是TransE基于实体和关系的分布式向量表示,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译(其实我一直很纳闷为什么叫做translating,其实就是向量相加),通过不断调整h、r和t(head、relation和tail的向量),使(h + r) 尽可能与 t 相等,即 h + r = t。

损失函数是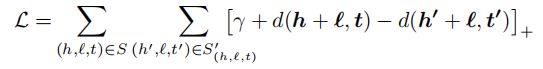
TransE代码逻辑梳理
首先注明,该代码不是出自我手,但由于最近需要使用并修改TransE,故从github上找到一个还不错的TransE实现,对其进行阅读,并梳理其逻辑,为后续工作做好铺垫。贴上其github链接,感谢前人辛苦付出。https://github.com/wuxiyu/transE/blob/master/tranE.py
下面对其代码进行分析。
首先,这里将整个代码封装成了一个类,该类的构造方法(由于平常用的语言是java,python只当做工具语言,没有系统学过语法,所以用词可能不当,见谅)中需要的参数如下所示:
:param entityList: 实体列表,读取文本文件,实体+id
:param relationList: 关系列表,读取文本文件,关系+id
:param tripleList: 三元组列表,读取文本文件,实体+实体+关系
:param margin: 表示正负样本之间的间距,是一个超参数,也就是公式中Loss里的γ
:param learingRate: 学习率,其实就是梯度下降中的步长
:param dim: 向量维度,即h,t,l向量的维度是1*dim,因为最终我们所有的实体和关系都是要表示为向量
:param L1: 距离公式采用矩阵1范数还是矩阵2范数
首先,我们将目光放到main方法,从main方法开始整个TransE的旅程。
dirEntity = "C:\\data\\entity2id.txt"
entityIdNum, entityList = openDetailsAndId(dirEntity)
dirRelation = "C:\\data\\relation2id.txt"
relationIdNum, relationList = openDetailsAndId(dirRelation)
dirTrain = "C:\\data\\train.txt"
tripleNum, tripleList = openTrain(dirTrain)
print("打开TransE")
transE = TransE(entityList,relationList,tripleList, margin=1, dim = 100)
print("TranE初始化")
transE.initialize()
transE.transE(15000)
transE.writeRelationVector("c:\\relationVector.txt")
transE.writeEntilyVector("c:\\entityVector.txt")
首先是通过三个Open方法分别获取实体数量和实体列表、关系总数量和关系列表、三元组总数量和三元组列表。获取需要的数据。
例如,其中entityList是一个list,其样式就为[05451384,04958634,00620424,....];
而relationList样式为["_member_of_domain_topic","_member_meronym"...];
而tripleList例如[(03964744,04371774,_hyponym), (....)....],其中全是三元组,都是(h,t,l)的格式。
至于那些Num们,都只是用于计数?并没发现用在哪里,也不用管
然后就是实例化TransE这个类了,将实体列表,关系列表,和三元组列表放进去,设置间距γ为1(这个是超参数,可以调),然后对于输出向量,其维度设为100(这个也可以自己指定)。
之后调用transE的initialize()方法,进行初始化。这里初始化具体做了什么呢?答曰初始化向量,构建字典集合,分别来装实体向量们和关系向量们。那么问题就来了,这个向量如何生成呢,之前我们手里只有05451384这串数字来代表实体,但是,并没有向量啊。这里采用的方式就是···随机生成,对于个100维的向量,随机生成它,方式为每一个数字都是在-6/(dim**0.5), 6/(dim**0.5)之间随机生成,然后构成一个100个元素的列表,即代表这个实体的向量,同时,将这个实体和其对应的随机生成的向量放入新创建的字典entityVectorList中去,同理对于关系也是如此操作。当然,在向量生成之后对其做一个归一化,保证它是单位向量,做法就是每个元素除以元素总和的平方和的开平方,具体见norm方法,这个很简单。
entityVectorList = {
}
relationVectorList = {
}
for entity in self.entityList:
n = 0
entityVector = []
while n < self.dim:
ram = init(self.dim)
entityVector.append(ram) #注意到这里的ram和entity是毫无关系的,是一个随机的值,所以这里append之后,就是一个dim个元素的列表
n += 1
entityVector = norm(entityVector)#归一化
entityVectorList[entity] = entityVector
至此,我们便为每个关系和实体生成了一个向量,向量是一个100维的列表。
然后我们将entityList和relationList赋值成这两个字典,也就是我们最初的entityList是列表,而经过初始化之后却变成了字典,字典的样式为{实体名:对应向量,…}
之后,下一步就是进行训练了。调用transE的transE()方法,其中输入的15000意为迭代的次数。
for cycleIndex in range(cI):#迭代cI次
Sbatch = self.getSample(150) #随机获取150个三元组
Tbatch = []#元组对(原三元组,打碎的三元组)的列表 :[((h,r,t),(h',r,t'))]
for sbatch in Sbatch:#遍历获取到的元组,并获取它们的打碎三元组,从而获得<=150个元组对(防止重复)
tripletWithCorruptedTriplet = (sbatch, self.getCorruptedTriplet(sbatch)) #将sbatch传入,获取打碎的三元组,然后构成一个元组对
if(tripletWithCorruptedTriplet not in Tbatch):
Tbatch.append(tripletWithCorruptedTriplet)
self.update(Tbatch)#对整个集合进行更新
if cycleIndex % 100 == 0:
print("第%d次循环"%cycleIndex)
print(self.loss)
self.writeRelationVector("c:\\relationVector.txt")
self.writeEntilyVector("c:\\entityVector.txt")
self.loss = 0
这里cI参数就是迭代次数。
首先是调用getSample()方法,该方法作用为在tripleList中随机选取size个三元组并返回。所以这里的Sbatch就是随机获取的150个三元组。
然后Tbatch是一个新创建的列表,用于存储元组(元组是tuple,是python中一种数据结构,而三元组是知识图谱的一种结构,不要搞乱了),其中的样式为[((h,r,t),(h',r,t'))]。
下面就是对Sbatch进行遍历,遍历每一个三元组,调用getCorruptedTriplet()方法来获取某个三元组的打碎的三元组,也就是在上面算法中提到的,对一个三元组,我们假定它是h+l=t的,此时我们创建一个范例,一个绝对不满足假设的,如何创建呢,任意用别的h或t来替换掉我们这里的h或t,从而得到一个错误的三元组,即打碎的三元组(我也不知道为啥叫打碎,不过挺有意思哈哈哈)。将打碎的三元组和正确的三元组放在一起组成一个新的元组,然后将其放入Tbatch列表中,当然这里有个去重的判断,很简单,就不说了哈。
下面的操作就是最重要的了,进行更新。
首先,要明确,这里的更新,只是针对我们随机选出来的150个三元组进行更新。然后,更新什么呢?当然是更新它们的向量,所以假设我们的h,t都互不相同,那么这里最多也就更新了300个实体的向量,(关系因为数量肯定没那么多,就不举例了)。然后更新的方式是什么,那就是通过梯度下降法来求得损失函数的最小值,从而获得一个最优的向量们。
好,下面我们来看这个更新操作,这里是调用update()方法,将刚才的Tbatch传入。
首先在该方法的开始,进行了两次拷贝,将实体列表(其实是实体-向量字典)和关系列表分别进行拷贝,目的是为了之后更新,不相互影响。然后关于deepcopy和copy的区别大家可以去查一下,简单来说就是前者copy的更彻底,列表或字典中的每个元素都单独拷贝了一份。
然后便是遍历这里的Tbatch,对每个元组进行操作。
首先是前面是一长串的赋值操作,选其中一个来说明。
headEntityVector = copyEntityList[tripletWithCorruptedTriplet[0][0]]
首先我们知道tripletWithCorruptedTriplet的格式是这样的[((h,r,t),(h',r,t'))],那[0][0]就是获取其中的h实体,然后根据h实体在entityList字典中获取其对应的向量。如此便是,其余也皆是同理。
然后根据L1参数是否为true来使用矩阵1范数或矩阵2范数,因为不同范数它的梯度是不一样的。
我们接下来矩阵2范数即L1==false来进行说明。此时进行计算Loss损失函数的值,根据公式 γ + d ( h + l , t ) − d ( h ′ + l , t ′ ) \gamma+d(h+l,t)-d(h'+l,t') γ+d(h+l,t)−d(h′+l,t′)来计算,当然这里的 d ( h + l , t ) d(h+l,t) d(h+l,t)要进行展开,就是普通的距离公式,展开之后的Loss函数为 γ + ( h + l − t ) 2 − ( h ′ + l − t ′ ) 2 \gamma+(h+l-t)^{2}-(h'+l-t')^{2} γ+(h+l−t)2−(h′+l−t′)2,等一下,是不是主要到这里和之前说的有些不同,对的,这里没有求和符号,因为这里相当于是把总的Loss给分开算的,所以没有求和符号了。累加起来便有。
然后当这个损失函数的值>0时,才进行更新,否则不进行更新。这里解释一下为什么这么操作。如此操作的原因在于我们喜欢正确的三元组的向量们满足h+l≈t,而打碎的三元组不满足,则正确三元组距离应该接近于0,而错误的应为一个不小的正值(因为是矩阵2范数),然后此时必然有损失函数值e<0的情况。当然,你也会说那假如两个值都不小,刚好前者小于后者呢,这种情况少,且没必要要求这么高,毕竟可以近似,同时这是算法层级的问题,这里不再讨论。
当e>0时,我们进行更新,这里更新的操作就是一个很简单的梯度下降方法。下面来介绍一下。首先损失函数Loss是 γ + ( h + l − t ) 2 − ( h ′ + l − t ′ ) 2 \gamma+(h+l-t)^{2}-(h'+l-t')^{2} γ+(h+l−t)2−(h′+l−t′)2,我们对其h进行求导得其梯度,则其结果是 ∂ ∂ h = 2 ( h + l − t ) \frac{\partial }{\partial h} = 2(h+l-t) ∂h∂=2(h+l−t),则h更新为 h ∗ = h − u ∗ ∂ ∂ h = h − u ∗ 2 ∗ ( h + l − t ) = h + u ∗ 2 ∗ ( t − h − l ) h^{*}=h-u*\frac{\partial }{\partial h}=h-u*2*(h+l-t)=h+u*2*(t-h-l) h∗=h−u∗∂h∂=h−u∗2∗(h+l−t)=h+u∗2∗(t−h−l),这里的u是梯度下降的步长,也就是上面提到的学习率,同理,t的更新也是一样, t ∗ = t − u ∗ 2 ∗ ( t − h − l ) t^{*}=t-u*2*(t-h-l) t∗=t−u∗2∗(t−h−l),然后同理l也是一样 l ∗ = l + u ∗ 2 ∗ ( t − h − l ) − u ∗ 2 ∗ ( t ′ − h ′ − l ) l^{*}=l+u*2*(t-h-l)-u*2*(t'-h'-l) l∗=l+u∗2∗(t−h−l)−u∗2∗(t′−h′−l)。
如此,进行更新,然后进行归一化,最终更新总的entityList和relationList。
至此,更新过程结束,至于后面的向量写入文件这里就不赘述了。
完整代码
这里代码我都加上了较为详细的注释,可以结合上面的代码梳理进行理解。
from random import uniform, sample
from numpy import *
from copy import deepcopy
class TransE:
def __init__(self, entityList, relationList, tripleList, margin = 1, learingRate = 0.00001, dim = 10, L1 = True):
'''
:param entityList: 实体列表,读取文本文件,实体+id
:param relationList: 关系列表,读取文本文件,关系+id
:param tripleList: 三元组列表,读取文本文件,实体+实体+关系
:param margin: gamma,目标函数的常数
:param learingRate: 学习率
:param dim: 向量维度,也就是h,t,l向量的维度是1*dim
:param L1: 距离公式
'''
self.margin = margin
self.learingRate = learingRate
self.dim = dim#向量维度
self.entityList = entityList#一开始,entityList是entity的list;初始化后,变为字典,key是entity,values是其向量(使用narray)。
self.relationList = relationList#理由同上
self.tripleList = tripleList#理由同上
self.loss = 0
self.L1 = L1
def initialize(self):
'''
初始化向量
'''
entityVectorList = {
}
relationVectorList = {
}
for entity in self.entityList:
n = 0
entityVector = []
while n < self.dim:
ram = init(self.dim)#初始化的范围
entityVector.append(ram) #注意到这里的ram和entity是毫无关系的,是一个随机的值,所以这里append之后,就是一个dim个元素的列表
n += 1
entityVector = norm(entityVector)#归一化
entityVectorList[entity] = entityVector
print("entityVector初始化完成,数量是%d"%len(entityVectorList))
for relation in self. relationList:
n = 0
relationVector = []
while n < self.dim:
ram = init(self.dim)#初始化的范围
relationVector.append(ram)
n += 1
relationVector = norm(relationVector)#归一化
relationVectorList[relation] = relationVector
print("relationVectorList初始化完成,数量是%d"%len(relationVectorList))
self.entityList = entityVectorList
self.relationList = relationVectorList
def transE(self, cI = 20):
print("训练开始")
for cycleIndex in range(cI):#迭代cI次
Sbatch = self.getSample(150) #随机获取150个三元组
Tbatch = []#元组对(原三元组,打碎的三元组)的列表 :{((h,r,t),(h',r,t'))}
for sbatch in Sbatch:#遍历获取到的元组,并获取它们的打碎三元组,从而获得<=150个元组对(防止重复)
tripletWithCorruptedTriplet = (sbatch, self.getCorruptedTriplet(sbatch)) #将sbatch传入,获取打碎的三元组,然后构成一个元组对
if(tripletWithCorruptedTriplet not in Tbatch):
Tbatch.append(tripletWithCorruptedTriplet)
self.update(Tbatch)#对整个集合进行更新
if cycleIndex % 100 == 0:
print("第%d次循环"%cycleIndex)
print(self.loss)
self.writeRelationVector("c:\\relationVector.txt")
self.writeEntilyVector("c:\\entityVector.txt")
self.loss = 0
def getSample(self, size):
'''
随机选取部分三元关系 sbatch
:param size:
:return:
'''
return sample(self.tripleList, size) #从tripleList中随机获取size个元素
def getCorruptedTriplet(self, triplet):
'''
training triplets with either the head or tail replaced by a random entity (but not both at the same time)
随机替换三元组的实体,h和t中任意一个被替换,但不同时替换。
也就是构建损坏的三元组集合
:param triplet:
:return corruptedTriplet:
'''
i = uniform(-1, 1)
if i < 0:#小于0,打坏三元组的第一项
while True:
entityTemp = sample(self.entityList.keys(), 1)[0]
if entityTemp != triplet[0]:
break
corruptedTriplet = (entityTemp, triplet[1], triplet[2])
else:#大于等于0,打坏三元组的第二项
while True:
entityTemp = sample(self.entityList.keys(), 1)[0]
if entityTemp != triplet[1]:
break
corruptedTriplet = (triplet[0], entityTemp, triplet[2])
return corruptedTriplet
def update(self, Tbatch):
'''
进行更新,更新的过程就是一个梯度下降
:param Tbatch:
:return:
'''
copyEntityList = deepcopy(self.entityList) #copy和deepcopy的区别在于,copy只拷贝整体,若局部改变,则拷贝整体的局部也改变,而deepcopy则全部拷贝过去
copyRelationList = deepcopy(self.relationList)
for tripletWithCorruptedTriplet in Tbatch:#遍历整个元组,最多迭代150次
# 这里的索引很好理解((h,t,l)(h',t',l)) 但是copyEntityList[h]
# 懂了,这里EntityList是类似于字典的,有id与向量这两个东西,所以是输入id,获取向量
headEntityVector = copyEntityList[tripletWithCorruptedTriplet[0][0]]#tripletWithCorruptedTriplet是原三元组和打碎的三元组的元组tuple
tailEntityVector = copyEntityList[tripletWithCorruptedTriplet[0][1]]
relationVector = copyRelationList[tripletWithCorruptedTriplet[0][2]]
headEntityVectorWithCorruptedTriplet = copyEntityList[tripletWithCorruptedTriplet[1][0]]
tailEntityVectorWithCorruptedTriplet = copyEntityList[tripletWithCorruptedTriplet[1][1]]
#下面的也是一模一样,感觉只是为了备份一份,进行比较
headEntityVectorBeforeBatch = self.entityList[tripletWithCorruptedTriplet[0][0]]#tripletWithCorruptedTriplet是原三元组和打碎的三元组的元组tuple
tailEntityVectorBeforeBatch = self.entityList[tripletWithCorruptedTriplet[0][1]]
relationVectorBeforeBatch = self.relationList[tripletWithCorruptedTriplet[0][2]]
headEntityVectorWithCorruptedTripletBeforeBatch = self.entityList[tripletWithCorruptedTriplet[1][0]]
tailEntityVectorWithCorruptedTripletBeforeBatch = self.entityList[tripletWithCorruptedTriplet[1][1]]
if self.L1:#这L1啥意思···哦是L1范数
distTriplet = distanceL1(headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch, relationVectorBeforeBatch)
distCorruptedTriplet = distanceL1(headEntityVectorWithCorruptedTripletBeforeBatch, tailEntityVectorWithCorruptedTripletBeforeBatch , relationVectorBeforeBatch)
else:#否则L2范数
distTriplet = distanceL2(headEntityVectorBeforeBatch, tailEntityVectorBeforeBatch, relationVectorBeforeBatch)
distCorruptedTriplet = distanceL2(headEntityVectorWithCorruptedTripletBeforeBatch, tailEntityVectorWithCorruptedTripletBeforeBatch , relationVectorBeforeBatch)
eg = self.margin + distTriplet - distCorruptedTriplet #损失函数 就跟论文上公式是一样的
if eg > 0: #[function]+ 是一个取正值的函数 似乎是只有大于0时才进行更新,想一下,也确实,因为前一个距离应该为0,后一个不为0,然后,0-正<0则不用改,正-正>则需要改
self.loss += eg
if self.L1:
#这个学习率有点懵
tempPositive = 2 * self.learingRate * (tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self.learingRate * (tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
tempPositiveL1 = []
tempNegtativeL1 = []
for i in range(self.dim):#不知道有没有pythonic的写法(比如列表推倒或者numpy的函数)?
if tempPositive[i] >= 0:
tempPositiveL1.append(1)
else:
tempPositiveL1.append(-1)
if tempNegtative[i] >= 0:
tempNegtativeL1.append(1)
else:
tempNegtativeL1.append(-1)
tempPositive = array(tempPositiveL1)
tempNegtative = array(tempNegtativeL1)
else:
#这里学习率就是y?对,应该这里的学习率就是梯度下降中的步长
#然后括号里是t-h-l
tempPositive = 2 * self.learingRate * (tailEntityVectorBeforeBatch - headEntityVectorBeforeBatch - relationVectorBeforeBatch)
tempNegtative = 2 * self.learingRate * (tailEntityVectorWithCorruptedTripletBeforeBatch - headEntityVectorWithCorruptedTripletBeforeBatch - relationVectorBeforeBatch)
#进行更新
headEntityVector = headEntityVector + tempPositive #h* = h + 增量
tailEntityVector = tailEntityVector - tempPositive #t* = t - 增量
relationVector = relationVector + tempPositive - tempNegtative #l* = l +y*2(t-h-l) -y*2(t'-h'-l)
headEntityVectorWithCorruptedTriplet = headEntityVectorWithCorruptedTriplet - tempNegtative #同理
tailEntityVectorWithCorruptedTriplet = tailEntityVectorWithCorruptedTriplet + tempNegtative #同理
#只归一化这几个刚更新的向量,而不是按原论文那些一口气全更新了
copyEntityList[tripletWithCorruptedTriplet[0][0]] = norm(headEntityVector)
copyEntityList[tripletWithCorruptedTriplet[0][1]] = norm(tailEntityVector)
copyRelationList[tripletWithCorruptedTriplet[0][2]] = norm(relationVector)
copyEntityList[tripletWithCorruptedTriplet[1][0]] = norm(headEntityVectorWithCorruptedTriplet)
copyEntityList[tripletWithCorruptedTriplet[1][1]] = norm(tailEntityVectorWithCorruptedTriplet)
self.entityList = copyEntityList #进行更新
self.relationList = copyRelationList
def writeEntilyVector(self, dir):
print("写入实体")
entityVectorFile = open(dir, 'w')
for entity in self.entityList.keys():
entityVectorFile.write(entity+"\t")
entityVectorFile.write(str(self.entityList[entity].tolist()))
entityVectorFile.write("\n")
entityVectorFile.close()
def writeRelationVector(self, dir):
print("写入关系")
relationVectorFile = open(dir, 'w')
for relation in self.relationList.keys():
relationVectorFile.write(relation + "\t")
relationVectorFile.write(str(self.relationList[relation].tolist()))
relationVectorFile.write("\n")
relationVectorFile.close()
def init(dim):
'''
向量初始化,随机生成值
:param dim: 维度
:return:
'''
return uniform(-6/(dim**0.5), 6/(dim**0.5)) #uniform(a, b)#随机生成a,b之间的数,左闭右开
def distanceL1(h, t ,r):
s = h + r - t
sum = fabs(s).sum()
return sum
def distanceL2(h, t, r):
'''
这里是对向量进行操作的,所以有个sum
:param h: 这里的都是向量
:param t:
:param r:
:return:
'''
s = h + r - t
sum = (s*s).sum()
return sum
def norm(list):
'''
归一化
:param 向量
:return: 向量/向量的能量
'''
var = linalg.norm(list)
i = 0
while i < len(list):
list[i] = list[i]/var
i += 1
return array(list)
def openDetailsAndId(dir,sp="\t"):
idNum = 0
list = []
with open(dir) as file:
lines = file.readlines()
for line in lines:
DetailsAndId = line.strip().split(sp)
list.append(DetailsAndId[0])
idNum += 1
return idNum, list
def openTrain(dir,sp="\t"):
num = 0
list = []
with open(dir) as file:
lines = file.readlines()
for line in lines:
triple = line.strip().split(sp)
if(len(triple)<3):
continue
list.append(tuple(triple))
num += 1
return num, list
if __name__ == '__main__':
dirEntity = "C:\\data\\entity2id.txt"
entityIdNum, entityList = openDetailsAndId(dirEntity)
dirRelation = "C:\\data\\relation2id.txt"
relationIdNum, relationList = openDetailsAndId(dirRelation)
dirTrain = "C:\\data\\train.txt"
tripleNum, tripleList = openTrain(dirTrain)
print("打开TransE")
transE = TransE(entityList,relationList,tripleList, margin=1, dim = 100)
print("TranE初始化")
transE.initialize()
transE.transE(15000)
transE.writeRelationVector("c:\\relationVector.txt")
transE.writeEntilyVector("c:\\entityVector.txt")
参考资料
https://blog.csdn.net/u011274209/article/details/50991385
https://blog.csdn.net/jiayalu/article/details/100543909
https://github.com/wuxiyu/transE/blob/master/tranE.py