zmq一些扩展模式 客户端服务器 一对多 多对多问题 订阅模式的扩展等
级联模式
通常,一个节点,即可以作为 Server,同时也能作为 Client,通过 PipeLine 模型中的 Worker,他向上连接着任务分发,向下连接着结果搜集的 Sink 机器。因此,我们可以借助这种特性,丰富的扩展原有的三种模式。例如,一个代理 Publisher,作为一个内网的 Subscriber 接受信息,同时将信息,转发到外网,其结构图

多个服务器
ZMQ 和 Socket 的区别在于,前者支持N:M的连接,而后者则只是1:1的连接,那么一个 Client 连接多个 Server 的情况是怎样的呢
ZMQ 的N:1的连接情况:(一对多)
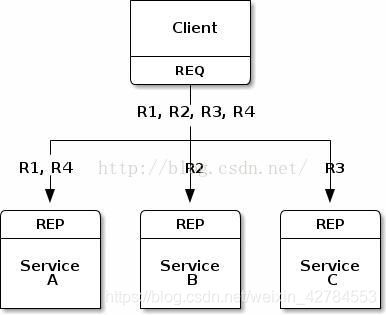
我们假设 Client 有 R1,R2,R3,R4四个任务,我们只需要一个 ZMQ 的 Socket,就可以连接四个服务,他能够自动均衡的分配任务。如图所示,R1,R4自动分配到了节点A,R2到了B,R3到了C。
N:M的连接(多对多)
如图:

我们通过一个中间结点(Broker)来进行负载均衡的功能。我们通过代码了解,其中的 Client 实际基础的zmq.REQ模式,而 Server 端的不同是,他不需要监听端口,而是需要连接 Broker 的端口,接受需要处理的信息。所以,我们重点阅读 Broker 的代码:
client.py
import zmq,time
# Prepare our context and sockets
context = zmq.Context()
socket = context.socket(zmq.REQ)
socket.connect("tcp://localhost:5559")
# Do 10 requests, waiting each time for a response
for request in range(1,11):
time.sleep(2)
socket.send(b"Hello")
message = socket.recv()
print("Received reply %s [%s]" % (request, message))
Broker.py
import zmq,time
# Prepare our context and sockets
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
backend = context.socket(zmq.DEALER)
frontend.bind("tcp://*:5559")
backend.bind("tcp://*:5560")
# Initialize poll set
poller = zmq.Poller()
poller.register(frontend, zmq.POLLIN)
poller.register(backend, zmq.POLLIN)
# Switch messages between sockets
while True:
socks = dict(poller.poll()) #轮询器 循环接收
if socks.get(frontend) == zmq.POLLIN:
message = frontend.recv_multipart()
backend.send_multipart(message)
if socks.get(backend) == zmq.POLLIN:
message = backend.recv_multipart()
frontend.send_multipart(message)
server.py
import zmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.connect("tcp://localhost:5560")
while True:
message = socket.recv()
print("Received request: %s" % message)
socket.send(b"World")
同时我们可以开多个客户端可多个服务端来同时进行,Broker.py可以根据收到消息的不同来进行相应的处理返回给对方
Broker 监听了两个端口,接受从多个 Client 端发送过来的数据,并将数据,转发给 Server。在 Broker 中,我们监听了两个端口,使用了两个 Socket,那么对于多个 Socket 的情况,我们是不需要通过轮询的方式去处理数据的,在之前,我们可以使用 libevent 实现,异步的信息处理和传输。而现在,我们只需要使用 ZMQ 的$poll->poll 以实现多个 Socket 的异步处理。
扩展 ZMQ 的订阅者模式
当我们将 WEB 代码部署到集群上的时候,如果需要实时的将最新的配置信息,主动的推送到各个机器节点。在此过程中,我们一定要保证,各个节点收到的信息的一致性和正确性,如果使用 HTTP,由于他的无状态性,我们无法保证信息的一致性,当然,你可以使用 HTTP 来实现,只是更复杂,ZMQ是更好的选择
我们使用 ZMQ 的信息订阅模式。在普通模式中,我们注意到,对于后来的加入节点,始终会丢失在他加入之前,已经发送的信息(Slow joiner)。我们可以开启另外一个 ZMQ 的通信通道,用于报告当前节点的情况(节点的身份、准备状态等),保证所有的节点都连接完成之后再开始推送消息,其结构如图所示:

使用 Request-Reply 连接来确认所有的节点连接完毕
Sub代码:
import time
import zmq
def main():
context = zmq.Context()
#创建接收订阅消息的连接
subscriber = context.socket(zmq.SUB)
subscriber.connect('tcp://localhost:5561')
#设置接收的连接头
subscriber.setsockopt(zmq.SUBSCRIBE, b'')
time.sleep(1)
#创建用来确认用户连接是否足够的连接
syncclient = context.socket(zmq.REQ)
syncclient.connect('tcp://localhost:5562')
#发送确认连接的消息 并接受`在这里插入代码片`
syncclient.send(b'')
syncclient.recv()
nbr = 0
while True:
msg = subscriber.recv()
if msg == b'END':
break
nbr += 1
print ('Received %d updates' % nbr)
if __name__ == '__main__':
main()
pub代码:
import zmq
# 确认节点数目达到要求
SUBSCRIBERS_EXPECTED = 10
def main():
context = zmq.Context()
# 创建用来发送需要的消息的连接
publisher = context.socket(zmq.PUB)
publisher.sndhwm = 1100000 # 设置高水位标记
publisher.bind('tcp://*:5561')
# 创建用来确认用户数量是否足够的连接
syncservice = context.socket(zmq.REP)
syncservice.bind('tcp://*:5562')
subscribers = 0
# 判断此时的连接数 不够的话继续接收并连接
while subscribers < SUBSCRIBERS_EXPECTED:
msg = syncservice.recv()
syncservice.send(b'')
subscribers += 1
print("+1 subscriber (%i/%i)" % (subscribers, SUBSCRIBERS_EXPECTED))
#当连接数量足够了开始发布消息
for i in range(1000000):
publisher.send(b'Rhubarb')
publisher.send(b'END')
if __name__ == '__main__':
main()
如果使用TCP连接并且订阅者是慢速的,那么消息将在发布方排队;可以使用高水位标记(High-Water Marks,HWM)来定义缓冲区的大小,在ZeroMQ v2.x版本中HWM默认是无限制的,而在v3.x中默认情况下它是1000。对于PUB套接字,当到达HWM时,将丢弃数据。设置HWM参数: