MLAPP————第八章 Logistic 回归
第八章 Logistic回归
8.1 简介
在这一章我们是介绍了用判别模型来进行分类问题的求解,而不是进行用生成模型。
8.2 模型的描述
正如我们在1.4.6讨论的,逻辑回归对应于以下的二分类模型:![]() ,下图给出了
,下图给出了![]() 在2维情况下的对于不同的
在2维情况下的对于不同的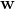 的这样的图:
的这样的图:

其实如果我们认定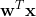 等于0,即
等于0,即![]() 等于0.5作为分类的界的话,那么分类的那条线就是与垂直的那条线。
等于0.5作为分类的界的话,那么分类的那条线就是与垂直的那条线。
8.3 模型拟合
在这一小节中,我么讨论相关算法去估计logistic回归模型中的相关参数。
8.3.1 MLE
logistic回归的NLL可以写成:
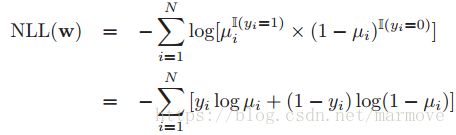
还有一种书写的方式就是我们假设![]() ,所以我们有
,所以我们有![]() ,
,![]() ,所以在这个情况下,NLL就可以写为:
,所以在这个情况下,NLL就可以写为: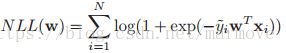 。在这里,logistic回归和线性回归不太一样,并不能够算出MLE的闭式表达式,所以我们只能使用凸优化的方法进行求解。那么我们就需要计算梯度或者汉森矩阵。我们计算
。在这里,logistic回归和线性回归不太一样,并不能够算出MLE的闭式表达式,所以我们只能使用凸优化的方法进行求解。那么我们就需要计算梯度或者汉森矩阵。我们计算![]() 情况下的梯度和汉森矩阵,结果为:
情况下的梯度和汉森矩阵,结果为:

其中![]() ,并且汉森矩阵是正半定的,所以NLL是凸的,我们可以收敛到全局最优解。下面进行证明:
,并且汉森矩阵是正半定的,所以NLL是凸的,我们可以收敛到全局最优解。下面进行证明:

8.3.2 最陡下降法
对于没有约束的凸优化问题,最简单的方法就是梯度下降法(gradient descent)也叫做最陡下降法(steepest descent)。这个可以被写成如下的形式:![]() ,其中
,其中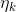 称为学习速率。那么比较关键的一个问题就是这个学习速率应该设置多大。这个其实是比较难的。如果我们使用一个常数的学习速率的话,如果我们设置这个学习速率比较的小,那么收敛的速度就会很慢。相反呢,如果这个学习速率设置的很大,那么就会在最优点来回震荡,从而不能够收敛到全局最优解。书中的图8.2举了一个相关的例子。
称为学习速率。那么比较关键的一个问题就是这个学习速率应该设置多大。这个其实是比较难的。如果我们使用一个常数的学习速率的话,如果我们设置这个学习速率比较的小,那么收敛的速度就会很慢。相反呢,如果这个学习速率设置的很大,那么就会在最优点来回震荡,从而不能够收敛到全局最优解。书中的图8.2举了一个相关的例子。
那么为什么叫最陡下降法或者是梯度下降法呢,我们从一阶泰勒展开入手,如下:![]() ,这个式子成立的条件就是
,这个式子成立的条件就是![]() 是非常小的一个变化,而
是非常小的一个变化,而![]() 就是在
就是在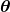 这个点的梯度。那么很显然,如果我们假设
这个点的梯度。那么很显然,如果我们假设![]() 的二范数是一个定值,那么它的方向与
的二范数是一个定值,那么它的方向与![]() 完全相反,此时目标函数下降的最多。但是又回到刚才的问题,首先
完全相反,此时目标函数下降的最多。但是又回到刚才的问题,首先 很小这个式子才成立,梯度下降才有意义,很小的是一定会慢慢收敛到全局最优解的(当然这要求函数是凸的),但是我们希望在有效的情况下,足够大,这样收敛的速度才会比较的快。
很小这个式子才成立,梯度下降才有意义,很小的是一定会慢慢收敛到全局最优解的(当然这要求函数是凸的),但是我们希望在有效的情况下,足够大,这样收敛的速度才会比较的快。
有一个方法叫做line minimization或者是line search,其实我们也明白如果我们可以求得函数的导数,那么导数为0的点就是最优点,但是往往用梯度下降法就是这个没有办法求,但是我们仍然希望我们找的是使得![]() 这个值最小的。详细我也每太弄懂,可以谷歌,只知道选择的步长满足wolf condition。个人理解,这个condition 包含两个意思,第一你的步长和你的函数的下降值要相当,即:
这个值最小的。详细我也每太弄懂,可以谷歌,只知道选择的步长满足wolf condition。个人理解,这个condition 包含两个意思,第一你的步长和你的函数的下降值要相当,即:![]() ,这样就避免你走了很远,但是只下降了一点,比如你步长太大,直接从最优点的右边走到了左边,第二个就是你的梯度要尽可能变化的大一点:
,这样就避免你走了很远,但是只下降了一点,比如你步长太大,直接从最优点的右边走到了左边,第二个就是你的梯度要尽可能变化的大一点: ,这样就避免你只走了一点点,斜率都没有什么变化。暂时只理解到这一步,也不太确定理解是否正确。
,这样就避免你只走了一点点,斜率都没有什么变化。暂时只理解到这一步,也不太确定理解是否正确。
但是呢,如果严格的遵守line search,就会导致zig-zag,就是收敛路径来回跳动,像走之字形一样。怎么来形象的理解呢,我们在做line search 的时候,出发点还是找![]() 这个的最小值,那么在求导数的时候其实就是要求
这个的最小值,那么在求导数的时候其实就是要求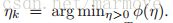 ,也就是
,也就是![]() ,即
,即![]() 为0,其中
为0,其中![]() 是上一时刻的导数,而
是上一时刻的导数,而![]() 是下一时刻的导数,那么要么下一时刻的导数为0,也就是找到了最优解,或者说下一时刻的导数与上一时刻正好正交,那么这时候就很容易走成z字形的样子。
是下一时刻的导数,那么要么下一时刻的导数为0,也就是找到了最优解,或者说下一时刻的导数与上一时刻正好正交,那么这时候就很容易走成z字形的样子。
那么怎么去缓和这一现象呢,一个启发式的方法就是加momentum项![]() ,也就是惯性项,即:
,也就是惯性项,即:![]() ,其中
,其中![]() 控制着这个momentum项的重要性。这个在优化领域里面也叫做重球方法,个人理解就是球很重,那么据有很强的惯性,这样你的下一步的动作就会收到上一步动作的影响,一方面呢可以缓和刚才上面说的zig-zag,另一方面呢其实也可以避免最终停在如鞍点以及一些比较浅的local minimum点上。
控制着这个momentum项的重要性。这个在优化领域里面也叫做重球方法,个人理解就是球很重,那么据有很强的惯性,这样你的下一步的动作就会收到上一步动作的影响,一方面呢可以缓和刚才上面说的zig-zag,另一方面呢其实也可以避免最终停在如鞍点以及一些比较浅的local minimum点上。
另一个可以缓解zig-zag的方法叫做共轭梯度,这个暂时我先不去了解了,23333。
8.3.3 牛顿法
当我们考虑曲线的曲率的时候,我们可以给出一个下降的更快的方法,这个就叫做二阶的优化方法。主要的一个例子就是牛顿法。牛顿法具体的更新步骤如下:![]() ,其中
,其中![]() 是汉森矩阵,同样也是叫做步长,整个的伪代码如下:
是汉森矩阵,同样也是叫做步长,整个的伪代码如下:

那么这个是怎么得到的呢,刚才上一个section我们讲到将函数近似成一阶泰勒展开,在这里我们考虑曲率信息后,就将函数近似成二姐泰勒展开,也就是把函数近似成一个二次函数,即:
![]() ,如果写成标准形式的话,即:
,如果写成标准形式的话,即:![]() ,其中我们有:
,其中我们有:![]() ,最小化这个函数就可以得到
,最小化这个函数就可以得到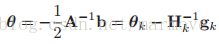 ,如果函数本身就是一个二次函数,那么直接这一步,就可以得到最优解,但是往往我们的函数并不是二次的,所以加一个步长,就是上面的形式。那么牛顿法要求汉森矩阵必须是正半定的,也就是函数必须是凸的,否则的话,会如下图所示不会沿着梯度的负方向下降:
,如果函数本身就是一个二次函数,那么直接这一步,就可以得到最优解,但是往往我们的函数并不是二次的,所以加一个步长,就是上面的形式。那么牛顿法要求汉森矩阵必须是正半定的,也就是函数必须是凸的,否则的话,会如下图所示不会沿着梯度的负方向下降:
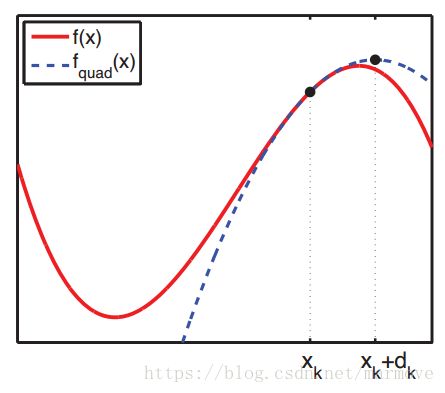
作为我人的理解就是在前面使用梯度下降法,因为一开始梯度下降法其实下降的速度还是可以的,但是随着梯度越来越小,那么收敛的速度会慢慢的降下来,但是这个时候很可能这个值就已经很接近minimum的值了,这个时候我们再去利用牛顿法使得更快的收敛到local或者global minimum。后面关于CG的我就不说了,这个我也不会,暂时跳过。
8.3.4 迭代重加权最小二乘(Iteratively reweighted least squares, IRLS)
下面我们将牛顿法运用到logistic回归的MLE的问题上来,这里我们假设步长为1,那么我们有:
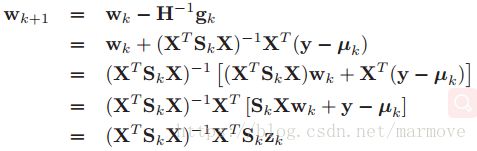
其中我们定义:![]() ,书中称之为working response,我也不太理解。对于加权最小二乘问题,即找一个使得:
,书中称之为working response,我也不太理解。对于加权最小二乘问题,即找一个使得: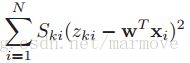 ,那么对于这个问题的解的闭式表达式就是:
,那么对于这个问题的解的闭式表达式就是:![]() 。由于
。由于![]() 是一个对角阵,所以我们可以把
是一个对角阵,所以我们可以把![]() 里面的每一个元素拿出来写,即:
里面的每一个元素拿出来写,即: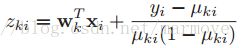 ,那么这个算法就叫做迭代重加权最小二乘(IRLS),整个算法的伪代码如下:
,那么这个算法就叫做迭代重加权最小二乘(IRLS),整个算法的伪代码如下:

8.3.5 拟牛顿法
可以这么说,上面所讲到的牛顿法,是所有的二阶的优化算法的鼻祖,但是对于汉森矩阵的计算是非常的复杂的,所以说拟牛顿法利用梯度的信息迭代的去更新汉森矩阵的近似值。最常见的方法是BFGS(这是根据四个人的人名首字母命名的)。它的更新规则如下:
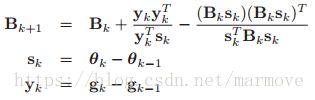
我们可以看到在每一次迭代的过程中,总是加上秩最多为2的矩阵,这样我们就能保证在设置合适的步长后,更新完的矩阵还能大概率的保证是正半定的。一般来说,我们初始化![]() ,所以说其实BFGS就可以想成是用一个对角阵加上一个低秩的矩阵去近似汉森矩阵。同样的BFGS也可以迭代的去更新汉森矩阵的逆
,所以说其实BFGS就可以想成是用一个对角阵加上一个低秩的矩阵去近似汉森矩阵。同样的BFGS也可以迭代的去更新汉森矩阵的逆![]() :
:![]() 。
。
正常情况下,上面的代码已经足够了,不过如果你的设备存储空间比较的小,那么上面存储一个汉森矩阵需要![]() 的空间,所以我们引入L-BFGS,其中汉森矩阵或者汉森矩阵的逆被近似成一个对角阵加上一个低秩的矩阵。事实上,我们可以把
的空间,所以我们引入L-BFGS,其中汉森矩阵或者汉森矩阵的逆被近似成一个对角阵加上一个低秩的矩阵。事实上,我们可以把 近似成最近的m个
近似成最近的m个![]() 而忽视掉之前更早的信息,这样就只需要
而忽视掉之前更早的信息,这样就只需要![]() ,这样空间就需要相对比较少。其实BFGS就是每一次迭代完更新,而L-BFGS就是只保留
,这样空间就需要相对比较少。其实BFGS就是每一次迭代完更新,而L-BFGS就是只保留![]() ,每一次要用到的时候迭代的计算出最新的汉森矩阵(用最近m次的数据),所以其实是增加了计算的复杂度的。
,每一次要用到的时候迭代的计算出最新的汉森矩阵(用最近m次的数据),所以其实是增加了计算的复杂度的。
8.3.6 二范数的正则化
对于logistic回归问题而言呢,我们同样要使用正则项来避免过拟合问题,为什么这么说呢,我们看下图:
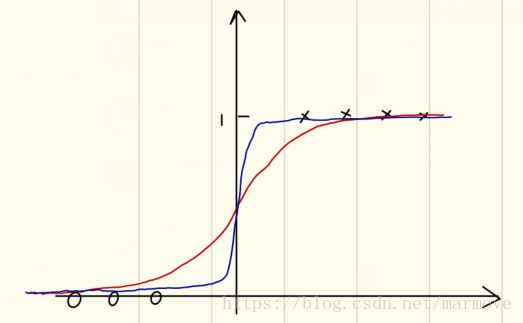
如果数据是如上分布的,那么我们在做拟合时红线和蓝色的线,哪一个更好,明显蓝色,因为当你的越大,趋向于无穷,其实针对这一组数据在训练的时候是最好的,但是其实这个就陷入了过拟合的情形,因为在0附近的点很有可能由于噪声的影响会出现左边等于1右边为0的情况,所以其实选择红色的线是更加稳健的做法。所以这样一看加入正则项就显得很有必要,加入正则化的项之后,整个函数,梯度,汉森矩阵更新如下:
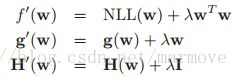
有个这三个计算公式之后,就可以利用梯度下降法或者是牛顿法进行计算了。
8.3.7 多类别的logistic回归
现在我们考虑多分类的logistic回归,有的时候也叫做最大熵分类器(只有一个概率为1,其余都为0,所以这样分类的结果确实是熵最大的),具体形式如下: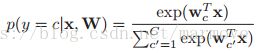 ,这个式子跟softmax函数是一样的。
,这个式子跟softmax函数是一样的。
下面定义一些符号,令![]() ,其中
,其中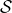 就是softmax函数。其中
就是softmax函数。其中![]() 是一个
是一个![]() 的向量,同时,令
的向量,同时,令![]() ,
,![]() 是
是![]() 所组成的向量。
所组成的向量。
这里设定![]() ,
,![]() 是一个
是一个![]() 的列向量。这里书中说是为了和(Krishnapuram et al. 2005)保持一致,我觉得虽然是总共C个分类,但是只要知道C-1个的结果,那么剩下的一个也就知道了。
的列向量。这里书中说是为了和(Krishnapuram et al. 2005)保持一致,我觉得虽然是总共C个分类,但是只要知道C-1个的结果,那么剩下的一个也就知道了。
那么根据以上的设定,似然函数可以写作:
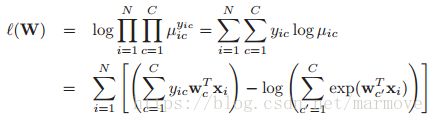
我们定义NLL为![]() 。下面我们定义一个符号叫做kronecker product,数学表示为
。下面我们定义一个符号叫做kronecker product,数学表示为![]() 。其中
。其中![]() ,
,![]() ,那么我们有:
,那么我们有:
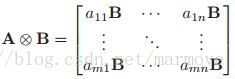
我们可以得到梯度为: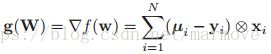 ,具体的证明过程如下:
,具体的证明过程如下:

其中:![]() ,
,![]()
![]() 。得到了梯度,下面我们继续去计算汉森矩阵。
。得到了梯度,下面我们继续去计算汉森矩阵。
汉森矩阵的结果为: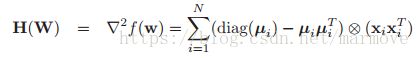 ,是一个
,是一个![]() 的矩阵。这个计算方法跟上面类似,计算一个任意的ij位置的值就可以了。有了梯度和汉森矩阵,就可以利用数值的方法去求得这个MLE的结果。
的矩阵。这个计算方法跟上面类似,计算一个任意的ij位置的值就可以了。有了梯度和汉森矩阵,就可以利用数值的方法去求得这个MLE的结果。
当然我们可以引入先验信息,即:![]() ,其中
,其中![]() ,那么我们就可以计算相应的函数,梯度和汉森矩阵:
,那么我们就可以计算相应的函数,梯度和汉森矩阵:
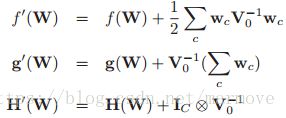
这样我们就可以利用数值的方法去计算MAP的结果了。
在这个问题上。呢,由于汉森矩阵的维度是巨大的,所以很明显利用L-BFGS是更加的合理的。
8.4 贝叶斯logistic回归
根据我们之前的经验,在贝叶斯的框架下,我们就是有似然,然后先验,然后计算整个的后验分布,得到后验分布是贝叶斯框架的核心,确实在线性回归中,这一套非常有用,但是对于logistic回归而言,我们并不能找到合适的共轭先验,所以在接下来的部分,我们考虑的是简单的近似。为了符号简单,我们考虑的是二元的情况。
8.4.1 拉普拉斯近似
在这一块中,我们将会讨论如何用一个高斯分布去近似后验分布。我们有![]() ,那么令
,那么令![]() ,其中
,其中![]() 叫做能量函数,具体形式为:
叫做能量函数,具体形式为:![]() ,同时Z是归一化常数
,同时Z是归一化常数![]() 。我们对于能量函数进行泰勒级数展开,即:
。我们对于能量函数进行泰勒级数展开,即: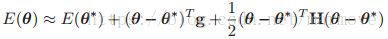 ,其中
,其中![]() 是MAP得到的结果。其中
是MAP得到的结果。其中![]() 一个是梯度一个是汉森矩阵。因此我们可以得到后验分布的高斯近似的样子
一个是梯度一个是汉森矩阵。因此我们可以得到后验分布的高斯近似的样子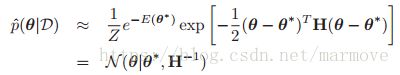 ,虽然书中说这个叫做拉普拉斯近似,不过其实叫做高斯近似更加的贴切。因为在另一篇文章中,拉普拉斯近似是一个更加复杂的方法。那么根据高斯分布归一化常数,可以得到:
,虽然书中说这个叫做拉普拉斯近似,不过其实叫做高斯近似更加的贴切。因为在另一篇文章中,拉普拉斯近似是一个更加复杂的方法。那么根据高斯分布归一化常数,可以得到: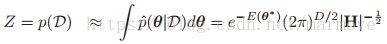 。高斯分布的设定其实也是比较合理的,因为根据中心极限定理,随着采样越来越多,后验分布是会接近高斯分布,不过说实话,采样多了之后似然就可以解决问题了,完全不用设定什么先验了。
。高斯分布的设定其实也是比较合理的,因为根据中心极限定理,随着采样越来越多,后验分布是会接近高斯分布,不过说实话,采样多了之后似然就可以解决问题了,完全不用设定什么先验了。
8.4.2 贝叶斯信息标准(BIC)的推导
通过上面的高斯的近似,我们可以得到边缘似然函数的近似结果,即: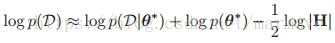 ,其实上面 已经有了结果,但是我们把它拉长,写的更具体了一些。这一块呢,第一个是似然函数,第二个是先验函数,在有先验的情况下,
,其实上面 已经有了结果,但是我们把它拉长,写的更具体了一些。这一块呢,第一个是似然函数,第二个是先验函数,在有先验的情况下,![]() 是MAP的结果,当我们使用的是uniform的先验,即
是MAP的结果,当我们使用的是uniform的先验,即![]() ,那么第二个部分就可以被扔掉。而
,那么第二个部分就可以被扔掉。而![]() 就可以用MLE的结果去代替。
就可以用MLE的结果去代替。
现在我们考虑去近似第三个部分。很显然,我们有![]() ,其中
,其中![]()
![]() 。我们把每一个汉森矩阵假设成一样的,那么就会有:
。我们把每一个汉森矩阵假设成一样的,那么就会有:![]() ,最后一个部分与N无关,可以扔掉。这里要说明一下,为什么与N无关,或者说之前的常数项都是可以扔掉的,这是因为随着N的增加,这些东西都被被似然所掩盖掉,所以可以忽略调,所以整体来说,高斯近似还是建立在N很大的时候比较有用。因此我们就可以得到:
,最后一个部分与N无关,可以扔掉。这里要说明一下,为什么与N无关,或者说之前的常数项都是可以扔掉的,这是因为随着N的增加,这些东西都被被似然所掩盖掉,所以可以忽略调,所以整体来说,高斯近似还是建立在N很大的时候比较有用。因此我们就可以得到:![]() 。这其实就是我们之前在5.3.2.4里面说的,用BIC准则去近似高斯分布的归一化常数。
。这其实就是我们之前在5.3.2.4里面说的,用BIC准则去近似高斯分布的归一化常数。
8.4.3 logistic回归的高斯近似
下面我们把高斯近似运用到logistic回归中。我们使用高斯先验![]() ,根据上文,那么我们就可以得到近似的高,斯分布具有如下的形式:
,根据上文,那么我们就可以得到近似的高,斯分布具有如下的形式:![]() ,其中:
,其中:![]() 。到这里近似已经结束了,下面我们来看看书上的仿真,总共有如下四幅图:
。到这里近似已经结束了,下面我们来看看书上的仿真,总共有如下四幅图:
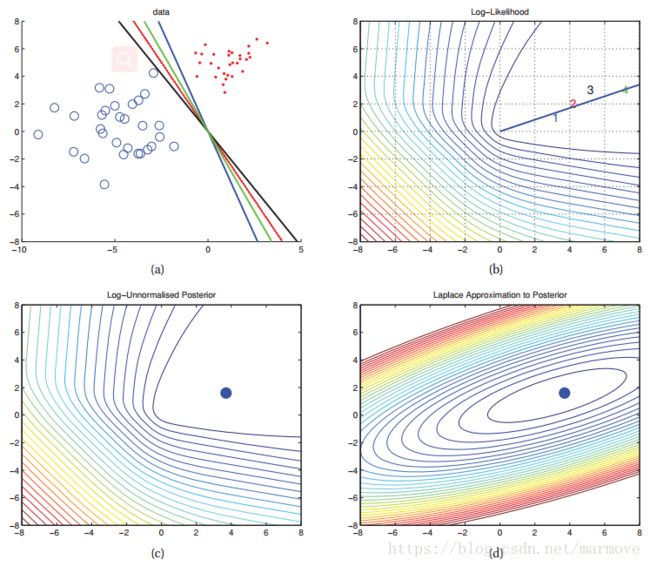
(a)图表示如果有一堆数据集,他们是可以被完全用一条直线分割开的,那么就会有图(b)的问题,就是你的最大似然解是趋向于无穷,那么这个就很不合适,其实就算是过拟合的一种表现。针对这样的一种现象,加入了正则化参数,即加先验![]() ,那么MAP的解就是(c)图的蓝色的点,这样就避免了MLE的尴尬。(d)是我们用高斯分布去近似这个后验分布,MAP的结果肯定是一样,这个就是补全了右边的空缺的部分,虽然这个近似其实跟真实的还是有很大的差距,但整体上比用MAP的delta函数要好。
,那么MAP的解就是(c)图的蓝色的点,这样就避免了MLE的尴尬。(d)是我们用高斯分布去近似这个后验分布,MAP的结果肯定是一样,这个就是补全了右边的空缺的部分,虽然这个近似其实跟真实的还是有很大的差距,但整体上比用MAP的delta函数要好。
8.4.4 近似的后验估计
有了后验分布,我们就可以用后验分布去进行估计。即:![]() ,但是很不幸的是,这个积分是非常的难算的。而比较简单的方法就是算后验的期望作为插入值,注意这个和之前的不一样,之前MAP是算后验的最大值,而这里是算后验的均值,不过如果后验是高斯的话好像是没什么区别。算出后验均值以后,可以得到
,但是很不幸的是,这个积分是非常的难算的。而比较简单的方法就是算后验的期望作为插入值,注意这个和之前的不一样,之前MAP是算后验的最大值,而这里是算后验的均值,不过如果后验是高斯的话好像是没什么区别。算出后验均值以后,可以得到![]() ,
,![]() 也称之为贝叶斯点。但是这个忽略了很多的不确定性,所以下面我们会考虑一些更好的估计方法。
也称之为贝叶斯点。但是这个忽略了很多的不确定性,所以下面我们会考虑一些更好的估计方法。
8.4.4.1 Monte Carlo 近似
一个更好的方法就是使用monte carlo近似,如下:
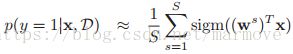
其中![]() 是从后验分布中采样的。通过这个方式我们已经得到了后验分布。
是从后验分布中采样的。通过这个方式我们已经得到了后验分布。
8.4.4.2 概率单位近似
在有了用高斯分布近似的后验分布之后,即:![]() ,通过这个我们可以进行后验分布估计,即:
,通过这个我们可以进行后验分布估计,即:
![]() ,其中:
,其中:
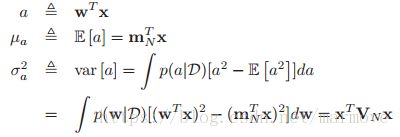
证明如下:
因此根据上面的式子,我们就是要计算在高斯分布下的,关于sigmoid函数的期望。但是这个不好算,那么怎么办,用近似的方法,我们发现sigmoid函数跟一个函数长得很像,就是probit函数,其实就是高斯分布的cdf,即:![]() 。下图展示了
。下图展示了![]() 和
和![]() 的关系,其中
的关系,其中![]() 。
。

几乎是重合的。那么使用probit函数有什么优势呢,因为这个是能够被计算的,即: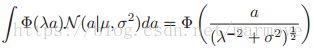 ,这里说明一下,这个式子右边的a是
,这里说明一下,这个式子右边的a是 ,应该是印刷错误,那么这个式子怎么来的呢,首先有一个式子:
,应该是印刷错误,那么这个式子怎么来的呢,首先有一个式子:![]() ,通过这个很容易得到上面的结论,更加具体的推导如下:
,通过这个很容易得到上面的结论,更加具体的推导如下:

我们可以把X,Y的分布反过来就很容易得到了。
到这一步,我们再次利用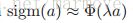 再近似回去,所以我们就得到了:
再近似回去,所以我们就得到了: 。我们可以看到
。我们可以看到![]() ,所以说其实有:
,所以说其实有:![]() ,这个式子表明了就是在做硬性判决的时候,其实是没有什么差别的,原来大于0.5的还是大于0.5,小于等于也一样。差别在于在confident变弱了,就是比如原来算出来是0.8的数据现在可能算出来0.6,这样其实就是分界线更加的平滑了,在分解点周围的点更不容易判断。
,这个式子表明了就是在做硬性判决的时候,其实是没有什么差别的,原来大于0.5的还是大于0.5,小于等于也一样。差别在于在confident变弱了,就是比如原来算出来是0.8的数据现在可能算出来0.6,这样其实就是分界线更加的平滑了,在分解点周围的点更不容易判断。
8.4.5 残差分析(异常点检测)*
8.5 在线学习和随机优化
传统的机器学习都是线下的,这表明我们有一堆的数据,一般来说,我们就是需要优化如下的公式: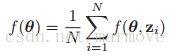 ,N就是我们拥有的数据的个数,在监督学习中,其中
,N就是我们拥有的数据的个数,在监督学习中,其中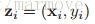 ,而在无监督学习中呢,标签就没有了。损失函数f可能是有很多样,就看怎么选了,这里就不说了。
,而在无监督学习中呢,标签就没有了。损失函数f可能是有很多样,就看怎么选了,这里就不说了。
然而在很多情况中,我们拥有的数据是流数据,这个时候数据是一点一点进来的,所以我们就需要用到在线学习,所以在这样的情况下,我们就需要每来一个数据就更新一下参数,而不是等到数据都有了,才整体进行更新。即使我们有的时候能够一次性的获得所有的数据,其实还是会用流数据的方式去处理,因为有时我们并没有足够的空间把数据整个都存储下来。
8.5.1 在线学习和regret最小化
假设在每一步,我们会得到一个采样值![]() ,那么得到采样值之后,我们就会考虑如何去更新参数
,那么得到采样值之后,我们就会考虑如何去更新参数![]() 。在理论机器学习这个领域中,在线机器学习其实对应的目标是regret,具体的形式如下:
。在理论机器学习这个领域中,在线机器学习其实对应的目标是regret,具体的形式如下:
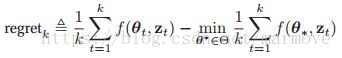
这个是什么意思呢,后面这个是我们实际上就是事后才能得到的数据,理论上在非在线学习中,后面这个![]() 是最好的结果,那么前面是我们针对每一个数据得到的相应的结果,两者做差,则体现了我们对于在线学习性能好坏的一种评价。
是最好的结果,那么前面是我们针对每一个数据得到的相应的结果,两者做差,则体现了我们对于在线学习性能好坏的一种评价。
在线学习的一个简单的算法就是在线梯度下降。具体的步骤如下:![]() ,其中
,其中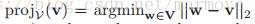 ,这是一个投影操作。这个投影操作就是相当于你的
,这是一个投影操作。这个投影操作就是相当于你的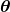 是被限制在某个空间内的,这样有可能更新之后会跳出这个限制,所以通过投影操作把他再次的回复到这个空间里面。
是被限制在某个空间内的,这样有可能更新之后会跳出这个限制,所以通过投影操作把他再次的回复到这个空间里面。
8.5.2 随机优化和风险最小化
对于regret其实我还是有点不太明白的,不过现在假设我们要去minimize另一个叫做期望损失的东西。具体的式子如下:![]() ,这个是关于未来的数据求期望。对目标中,有些变量是随机变量的优化称之为随机优化。
,这个是关于未来的数据求期望。对目标中,有些变量是随机变量的优化称之为随机优化。
假设我们从数据中获得了无穷多的数据流采样,那么优化随机目标的方法就是采用随机梯度下降法,由于我们只需要一个估计参数就好了,所以可以采用平均的方式: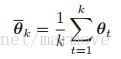 ,这个也叫做 Polyak-Ruppert averaging,也可以按照如下方式实现:
,这个也叫做 Polyak-Ruppert averaging,也可以按照如下方式实现:
![]()
8.5.2.1 设定步长
我们现在讨论一些关于学习率的一些条件,来保证SGD的收敛。这个被称之为Robbins-Monro条件:
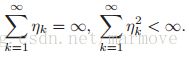
是随着时间的推移慢慢变化的,所以我们也称之为学习速率的一个时间表。一般会有如下的一些选择,比如:![]() 或者是:
或者是:![]() 。
。
需要调整这些参数是随机优化的主要缺点之一。一个简单的启发式(Bottou 2007)如下:存储数据的初始子集,在这个子集上尝试一些的,然后选择使得目标下降最快的一个,并将其应用到其他所有数据中。这个可能不会导致收敛,但是当整个性能不怎么提升的时候就可以终止。
8.5.2.2 每一个参数的步长
SGD的一个缺点就是它对于所有的参数都采用的是相同的步长,现在我们简单的提供一个叫做adagrad的方法。这个是怎么做的呢,假设![]() 是在第k个时间的参数i,
是在第k个时间的参数i,![]() 是他的梯度,采用如下的更新方法:
是他的梯度,采用如下的更新方法:
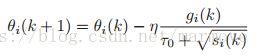
其中![]() ,这个方法考虑到了每一个维度的曲率的信息,根据之前整个的梯度的信息,来进行更新。
,这个方法考虑到了每一个维度的曲率的信息,根据之前整个的梯度的信息,来进行更新。
8.5.2.3 SGD和batch learning之间的比较
如果我们假设有无限多组数据的话,比如online可以算是无线数据,那么随机梯度下降法就是来一个数据做一次梯度下降,那么实际上我们并没有无限多组数据(这个往往就是offline),我们只是有很多组数据,这些数据不完全的刻画了数据的分布,那么我们怎么做随机梯度下降呢,算法如下:

首先初始化参数和步长,然后外循环就是不停的repeat,且每一次将数据随机的打乱(理论上是要进行置换抽样的,但是实际上我们不进行置换,就重复的利用相同排序的数据,反而效果更好),而内循环则是对这N个数据,一个一个经过梯度下降法去更新参数,并且也实时更新步长。
之前我们讲过最陡梯度下降法,就是一次性的对N个数据,利用梯度下降法进行计算,这个计算量会很大,那么我们还有一种折中的方法,不是一个一个的,也不是全部,而是比如一次五个数据进行梯度下降,这个就叫批次梯度下降法,即batch descent。
看上去好像SGD比较的简单,但其实SGD不仅计算上要更快,其实效果也更加的好,而且SGD不太容易会卡在一些浅的局部最优值点上,因为你每次用一个数据,所以往往是由噪声的,所以他相对比较容易会跳出这些局部最优点。所以SGD是一个很好的梯度下降的方法。
8.5.3 LMS算法
下面就是举一个例子,将SGD应用到online linear regression,7.14给的是batch的梯度,但是在在线学习中,用SGD,所以梯度就是:![]() 。我们可以看到其实这里
。我们可以看到其实这里![]() 其实就是该时刻的估计值,即
其实就是该时刻的估计值,即![]() ,所以利用梯度下降法,我们就可以得到:
,所以利用梯度下降法,我们就可以得到:![]() 。这里我们就称该算法为LMS算法,书中给了相关的仿真。
。这里我们就称该算法为LMS算法,书中给了相关的仿真。
8.5.4 感知器算法
现在我们来考虑在线学习的binary logistic regression。8.5给出了batch gradient的梯度,那么在在线学习中,我们可以得到更加简单的形式:![]() ,其中
,其中![]() ,这个其实是有具体表达式的。我们发现上面更新参数的这个式子其实和LMS长得基本上是一样的。
,这个其实是有具体表达式的。我们发现上面更新参数的这个式子其实和LMS长得基本上是一样的。
我们现在做一个近似,首先我们令![]() ,我们刚才参数更新的式子中,
,我们刚才参数更新的式子中,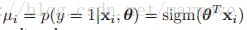 ,用
,用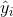 去近似
去近似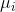 ,那么我们就有
,那么我们就有![]() 。
。
为了使得代数更加的简单,我们假设![]() 而不是
而不是![]() ,那么
,那么![]() ,那么这个时候我们就有
,那么这个时候我们就有![]() 就是错误的情况,相反就是正确的。
就是错误的情况,相反就是正确的。
那么在每一次的更新,我们发现如果![]() ,那么梯度就等于0,如果=1,
,那么梯度就等于0,如果=1, ,那么梯度就是
,那么梯度就是![]() ,反过来就是
,反过来就是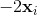 。那么根据这个我们的参数的更新公式就可以改写为:
。那么根据这个我们的参数的更新公式就可以改写为:![]() 。(这里我要说明一下自己的疑惑,由于上面一开始的参数更新公式是y=0或者1的情况下的,而理论上y=-1,1的话这个公式是不一样的,但是在后面更改了y的取值,却没有更新公式而是直接带入进去得到结论,这样的做法是否合适)
。(这里我要说明一下自己的疑惑,由于上面一开始的参数更新公式是y=0或者1的情况下的,而理论上y=-1,1的话这个公式是不一样的,但是在后面更改了y的取值,却没有更新公式而是直接带入进去得到结论,这样的做法是否合适)
伪代码如下:

这个算法其实在做logistic回归时效果并不太好,当训练数据是完全线性可分的,那么可以收敛,否则很有可能不能收敛或者收敛速度很慢。但感知器算法时第一个机器学习算法,具有很强的历史意义。
8.5.5 一个贝叶斯的观点
在线学习的另一个方法就是利用贝叶斯的观点去做。我们使用如下的公式:![]() ,这就是典型的后验的似然乘以先验,如果具有共轭先验的特点,那么这就是序贯的方法,在计算上会特别的简单,只是参数上的基本运算。另外由于在在线学习的时候,模型阶是没有办法用验证集去挑选的,但是贝叶斯可以自适应的去学习模型阶,变成联合分布就好了。
,这就是典型的后验的似然乘以先验,如果具有共轭先验的特点,那么这就是序贯的方法,在计算上会特别的简单,只是参数上的基本运算。另外由于在在线学习的时候,模型阶是没有办法用验证集去挑选的,但是贝叶斯可以自适应的去学习模型阶,变成联合分布就好了。
8.6 生成模型分类器和判别模型分类器的对比
首先我们知道logistic是判别模型,GDA是生成模型。在模块4.2.2中,我们可以看到在高斯判别分析中的后验和我们logistic回归的这个形式是一样的,都是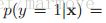
![]() ,当然4.2.2中是多分类的,转化为两分类就是一样的了。那么实际上书上说很多的生成类的模型啊,最终都可以转化为logistic回归后验的这样的形式,就比如说我们不假设是高斯的,而是泊松的,
,当然4.2.2中是多分类的,转化为两分类就是一样的了。那么实际上书上说很多的生成类的模型啊,最终都可以转化为logistic回归后验的这样的形式,就比如说我们不假设是高斯的,而是泊松的,![]() ,其实也是的。所以说其实logistic回归的这样的假设是要比GDA这样的假设更弱(更加广泛的)。
,其实也是的。所以说其实logistic回归的这样的假设是要比GDA这样的假设更弱(更加广泛的)。
另一个关于生成模型和判别模型的不同点就是,对于判别模型,我们总是通过最大化conditional log likelyhood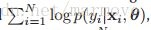 ,但是在生成模型中,我们是最大化joint log likelyhood
,但是在生成模型中,我们是最大化joint log likelyhood![]() 。
。
总的来说,对于GDA来说,如果说你的高斯的假设是对的,那么相比于logistics回归来说,你将需要更少的数据量就能获得相同的性能,所以总体来说GDA是更加复杂的模型,而logistic回归是相对一般化的模型,所以往往来说如果你对GDA的假设存在质疑,那么用logistic回归可能效果更加的好。
8.6.1 每种方法的优缺点
Easy to fit?相比而言,生成模型例如朴素贝叶斯,LDA更加的容易拟合,在计算上是比较的简单的,但是对于logistic模型来说,就比较的复杂,他需要通过一些优化的算法去解一些优化问题,这样是更慢的。
Fit classes separately?在生成分类器中,我们需要估计的参数是类条件独立的,就是不同的类是不相互干扰的,这样我们在加入新的类别相关数据的时候,并不需要对于之前的数据进行重新的训练。但是在判别模型中不一样,所有的参数都是互相关联的,所以说当数据有更新加入了新的类别之后,整个模型都要重新训练。
Handle missing features easily?在生成分类器模型中,其实是比较容易能够解决的,后面8.6.2能够很好的解决。但是对于判别模型来说很难处理。
Can handle unlabeled training data?使用生成模型,甚至可以用没有标签的数据去处理监督学习的任务,但是这一点上对于判别模型就不可能
Symmetric in inputs and outputs?对于生成模型来说,由于我们会得到最终的联合概率分布,所以说对于输入和输出的关系是对等的。这就意味着我们可以通过![]() 来推断输入数据的合理性,这一点是判别模型没有办法做到的。
来推断输入数据的合理性,这一点是判别模型没有办法做到的。
Can handle feature preprocessing?判别模型的一个很大的好处就是能够预处理数据,我们可以对于输入进行任何方式的预处理,我们可以用![]() 去代替原来的数据,但是生成模型就不可以,因为通过这样的处理吗,数据本身的关系可能就不再满足生成模型的假设了。
去代替原来的数据,但是生成模型就不可以,因为通过这样的处理吗,数据本身的关系可能就不再满足生成模型的假设了。
Well-calibrated probabilities?对于生成模型来说,做了很多太强的假设,所以后验类概率往往比较极端,但是判别模型往往更加的准确。
总体来说,两种方法各有优缺点,所以在应用的是侯还是要具体问题具体分析
8.6.2 处理缺失的数据(有点看不懂)
有些时候由于部分传感器出现了问题,我们的输入数据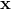 的部分是missing的,那么这个问题就叫做missing data problem。而生成模型的最大的优点之一就是可以去处理这个问题。
的部分是missing的,那么这个问题就叫做missing data problem。而生成模型的最大的优点之一就是可以去处理这个问题。
为了更加正式的做一些假设,我们引入一个二值的变量![]() 来指明
来指明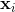 是否被观测到了。那么联合的模型具有如下的形式:
是否被观测到了。那么联合的模型具有如下的形式:![]() ,其中
,其中![]() 其实就是控制是否被观测到的参数。我们假设有如下的三种情况:
其实就是控制是否被观测到的参数。我们假设有如下的三种情况:![]() ,这个就是没有观测到任何数据的,叫missing completely at random(MCAR)。第二种情况就是
,这个就是没有观测到任何数据的,叫missing completely at random(MCAR)。第二种情况就是![]() ,其中
,其中![]() 是中被观测到的部分,那么我们称之为missing at random(MAR),如果这两个假设都不成立的话,那么就称之为not missing at random(NMAR)。我们假设我们后面二点模型是MAR的情况。
是中被观测到的部分,那么我们称之为missing at random(MAR),如果这两个假设都不成立的话,那么就称之为not missing at random(NMAR)。我们假设我们后面二点模型是MAR的情况。
当我们处理缺失数据问题的时候,我们最好要去区分是否只是在测试集里面会出现,或者是更复杂的情况在训练集里面也有缺失的数据。甚至在训练数据的时候,有可能会出现标签缺失的情况,这个问题就叫做半监督学习(semi-supervised learning)
8.6.2.1 在测试时间缺失数据
在生成模型中,我们怎么去处理缺失的数据呢,对于MAR模型来说,我们的处理方式就是把没有观测到的那些缺失特征,通过边缘化消掉。例如假设我们的 是缺失的,那么我们可以计算得到:
是缺失的,那么我们可以计算得到:
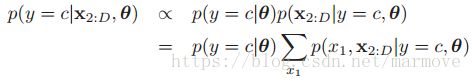
右边的式子两个部分,一个是先验![]() ,另一个我们也是很容易算的,所以这个模型是可算的。
,另一个我们也是很容易算的,所以这个模型是可算的。
如果我们作的是朴素贝叶斯的假设,那么边缘化的具体计算如下(这个是更容易的):

这个由于朴素贝叶斯假设的特殊性,更容易计算得到。不过在高斯判别分析中,其实我们利用4.3的公式也是很容易得到:
![]()
8.6.2.2 在训练时间缺失数据
这个是比较难的,在第十一章会考虑到这一点
8.6.3 Fisher's 线性判别分析(FLDA*)
之前我们说到的高斯判别分析有一个问题就是维度太高了,导致参数很多,那么我们就想到能否通过压缩特征的数目来降低维度。那么比较简单的方法就是找一个映射的矩阵![]() ,其中
,其中![]() 的矩阵,L肯定是比D要小很多的。那么有一个去寻找W的方法就是PCA,这个在后面会具体讲到,这个方法其实和前面的RDA结果很类似,因为PCA方法其实就是用SVD去做。但是这个带来一个问题,PCA只关注特征本身,并不关注标签,这样其实是不太合理的,我们希望压缩完的特征还能够很好的被高斯模型去刻画,所以接下来我们提出一个叫做Fisher‘s线性判别分析的方法(FLDA),这个方法是判别和生成方法的一个折中,但是这个方法有一个缺点就是它的维度必须被限制在
的矩阵,L肯定是比D要小很多的。那么有一个去寻找W的方法就是PCA,这个在后面会具体讲到,这个方法其实和前面的RDA结果很类似,因为PCA方法其实就是用SVD去做。但是这个带来一个问题,PCA只关注特征本身,并不关注标签,这样其实是不太合理的,我们希望压缩完的特征还能够很好的被高斯模型去刻画,所以接下来我们提出一个叫做Fisher‘s线性判别分析的方法(FLDA),这个方法是判别和生成方法的一个折中,但是这个方法有一个缺点就是它的维度必须被限制在![]() 的这个情况下。下面我们先来分析二分类的情况,然后再去分析更加复杂的多分类的情况。
的这个情况下。下面我们先来分析二分类的情况,然后再去分析更加复杂的多分类的情况。
8.6.3.1 关于二分类情况下的推导
首先我们定义二分类下的均值为: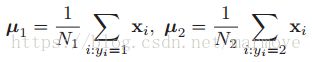 ,令
,令![]() 是对均值作的投影,同样令
是对均值作的投影,同样令![]() 是对数据作的投影。那么投影后的数据的方差就是
是对数据作的投影。那么投影后的数据的方差就是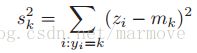 ,我们希望经过投影操作之后,数据能够被区分的很开,那么中心点就要尽量的远,然后方差要能够尽量的小(数据更加的紧密),所以我们定义:
,我们希望经过投影操作之后,数据能够被区分的很开,那么中心点就要尽量的远,然后方差要能够尽量的小(数据更加的紧密),所以我们定义: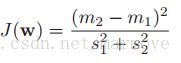 ,要使得这个尽量的大才好。
,要使得这个尽量的大才好。
我们作如下的定义:![]() 以及:
以及: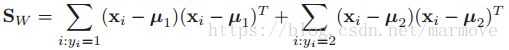 ,那么我们可以有:
,那么我们可以有:![]() 以及:
以及:
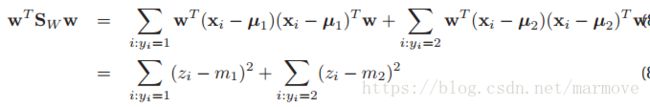 ,那么原来的优化函数就可以改写为:
,那么原来的优化函数就可以改写为:
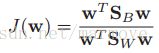 ,我们对该优化函数求导,得出
,我们对该优化函数求导,得出![]() ,后面我觉得书上写的有问题,所以按照自己的liji理解写了,这里我觉得这个
,后面我觉得书上写的有问题,所以按照自己的liji理解写了,这里我觉得这个 可以是任意的常数,而且我们只关注于的方向,因为根据目标函数ye也可以看出来,目标函数的值与的长度无关。如果我们假设
可以是任意的常数,而且我们只关注于的方向,因为根据目标函数ye也可以看出来,目标函数的值与的长度无关。如果我们假设![]() 是可逆的,那么我们就可以得到
是可逆的,那么我们就可以得到![]() ,事实上我们有:
,事实上我们有:![]() ,因此,
,因此,![]() ,我们不妨就假设
,我们不妨就假设![]() ,所以说我们就可以得到
,所以说我们就可以得到![]() 。
。
8.6.3.2 拓展到多分类高维的情况
拓展到高维的情况,整个的结果与之前是非常类似的:
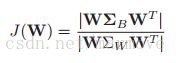

其中![]() =
= ![]() ,这里推da导就不推了,高维的求导什么的我也是很晕。然后这里假设的是
,这里推da导就不推了,高维的求导什么的我也是很晕。然后这里假设的是![]() 是非奇异的,如果是奇异的话,我们可以先对数据进行PCA预处理。
是非奇异的,如果是奇异的话,我们可以先对数据进行PCA预处理。
之前我们说过FLDA的一个很大的问题就是它限制维度最多为C-1,这是限制FLDA应用的一个很大的问题,为什么会这样,因为![]() 的秩是C-1,所以的维度再高也会被压缩。
的秩是C-1,所以的维度再高也会被压缩。
8.6.3.3 FLDA的概率解释*
这一块就跳了,不太重要,而且打了*