从零学python必备知识(三、机器学习库)(附示例代码)
文章目录
-
- (一)、函数+类
- (二)、并发+正则表达式
- 安装
- 17、Numpy
-
- 1)数组与数据类型
- 2)数组和标量的计算
- 3)数组的索引和切片
- 18、Pandas
-
- 1)Series基本操作
- 2)DataFrame基本操作
- 19、Matplotlib
-
- 1)简单曲线
- 2)绘制numpy进行计算的值
- 3)绘制多条线
- 4)绘制直方图
- 5)散点图
- 6)使用csv数据画有分类(不同颜色)的散点图
- 20、Tensflow
(一)、函数+类
从零学python必备知识(一、函数+类)(附示例代码)
(二)、并发+正则表达式
从零学python必备知识(二)
安装
使用pip安装,使用了清华的镜像速度会快很多:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ***
17、Numpy
numpy是用于高性能科学计算和数据分析,是常用的高级数据分析库的基础包。
1)数组与数据类型
根据输入数据的类型可以自动进行转换,数据类型比如有:int8,int16,int32,int64,float…
还可以使用numpy实现两个列表的数学计算,比如相加
import numpy as np
arr1 =np.array([2,3,4])
print(arr1)
print(arr1.dtype)
arr2=np.array([1.2,2.3,3.4])
print(arr2)
print(arr2.dtype)
print(arr1+arr2)
[2 3 4]
int32
[1.2 2.3 3.4]
float64
[3.2 5.3 7.4]
2)数组和标量的计算
标量是有大小没有方向的
data=[[1,2,3],[4,5,6]]
arr=np.array(data)#转化为numpy的二维矩阵
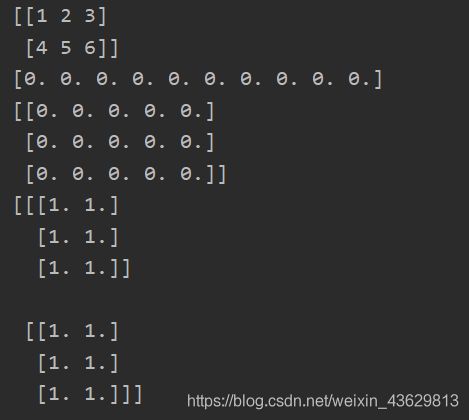
print(arr)
#对矩阵的操作
print(np.zeros(10))#全0,一维
print(np.zeros((3,5)))#全零,2维
print(np.ones((2,3,2)))#全1,3维
3)数组的索引和切片
import numpy as np
arr = np.arange(10)
print(arr)
arr[5:8]=10#不包括8
print(arr)
arr_slice=arr[5:8].copy()
arr_slice[:]=15
print(arr)
print(arr_slice)
[0 1 2 3 4 5 6 7 8 9]
[ 0 1 2 3 4 10 10 10 8 9]
[ 0 1 2 3 4 10 10 10 8 9]
[15 15 15]
更多关于切片的操作在另一篇博客中详细地写了:
Python中numpy数组切片:print(a[0::2])、a[::2]、[:,2]、[1:,-1:]、a[::-1]、[ : n]、[m : ]、[-1]、[:-1]、[1:]等的含义(详细)
18、Pandas
是用于数据预处理和清洗的非常重要的库。
最重要的数据结构是Series,DataFrame
基础实例:
from pandas import Series,DataFrame
import pandas as pd
obj=Series([4,5,6,-7])
print(obj)
print(obj.index)
print(obj.values)
0 4
1 5
2 6
3 -7
dtype: int64
RangeIndex(start=0, stop=4, step=1)
[ 4 5 6 -7]
1)Series基本操作
Series是一维数组
obj2 = Series([4,7,-5,3],index=['d','b','c','a'])
print(obj2)
obj2['c']=6
print(obj2)
print('a'in obj2)#当作列表来用
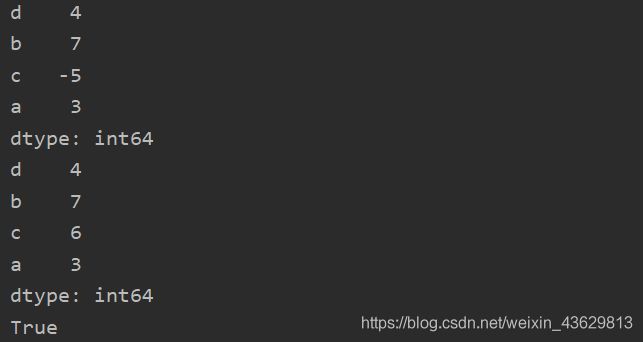
存储在字典中的数据怎么转化为Series呢?
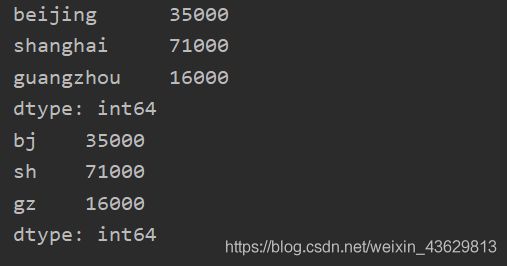
data={
'beijing':35000,'shanghai':71000,'guangzhou':16000}
obj3=Series(data)#转化
print(obj3)
obj3.index=['bj','sh','gz']#可以直接修改索引
print(obj3)
2)DataFrame基本操作
DataFrame更像是电子表格,DateFrame可以操作二维,三维,或更高维的数组。一般用等长的列表创建。例如使用字典,其中是等长列表:
1 创建
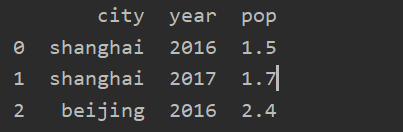
data = {
'city': ['shanghai', 'shanghai', 'beijing'],
'year': [2016, 2017, 2016],
'pop': [1.5, 1.7, 2.4]}
frame = DataFrame(data)
print(frame)
2 排序(交换列的顺序)
frame1=DataFrame(data,columns=['year','city','pop'])
print(frame1)

3 提取有两种方式
print(frame1['city'])
print(frame1.year)
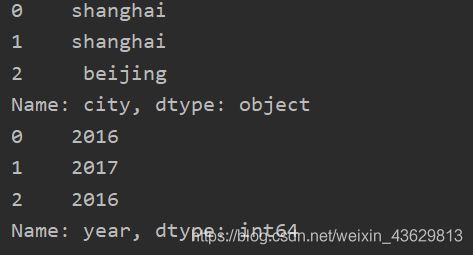
4 生成新列
判断是否是beijing
frame1['cap'] = frame1.city=='beijing'
print(frame1)

5 转置
行的索引变成列的索引,列的索引变成行的索引。
print(frame1.T)
6 重新索引及空值填充
增加了索引e
obj = Series([4,7,-5,3],index=['d','b','c','a'])
obj1 = obj.reindex(['a','b','c','d','e'])
print(obj1)
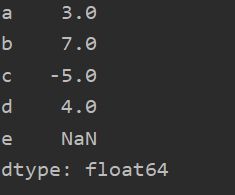
增加了索引e,e是空的(NaN)。如果要填充,可以使用:obj1 = obj.reindex([‘a’,‘b’,‘c’,‘d’,‘e’].fill_value=0)
但这样有时候是不严谨的,我们使用上面或者下面的值来补充空值。
method=‘ffill’----使用上面的值填充,method=‘bfill’----使用下面的值填充。
obj = Series(['a','b','c'],index=[0,2,4])
print(obj.reindex(range(6),method='ffill'))
print(obj.reindex(range(6),method='bfill'))
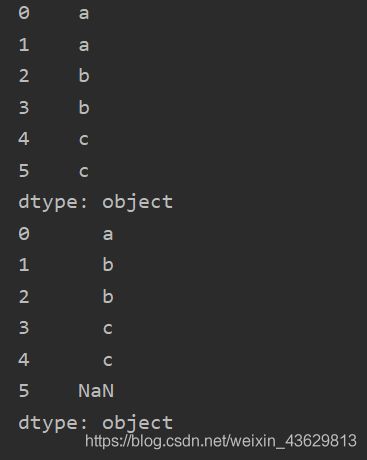
7 删除缺失值
from numpy import nan as NA
data=Series([1,NA,2])
print(data.dropna())
dropna()删除所有有NaN的值,我们也可以进行控制,比如只删除整行全是NaN的:
print(data.dropna(how='all))
删除整列全是NaN的:
print(data.dropna(axis=1,how='all))
8 填充NaN
fillna(0)修改的是副本,使用inplace=True才是确定修改了!
print(data.fillna(0),inplace=True)
19、Matplotlib
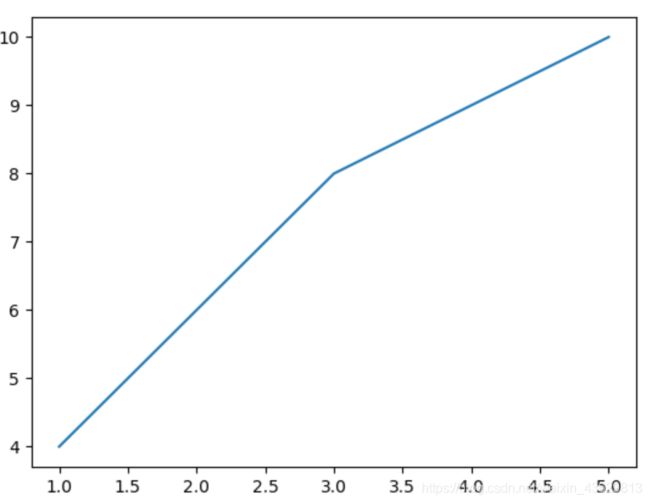
1)简单曲线
import matplotlib.pyplot as plt
plt.plot([1,3,5],[4,8,10])
plt.show()
2)绘制numpy进行计算的值
import numpy as np
#linspace产生一条直线,x轴定义域为-3.14~3.14,中间间隔100个元素
x=np.linspace(-np.pi,np.pi,100)
plt.plot(x,np.sin(x))
plt.show()
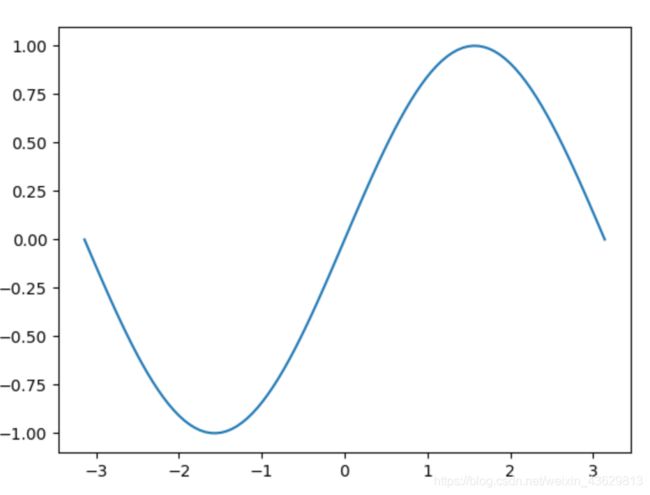
3)绘制多条线
plt.figure()—创建图表
dpi—图像的精细度,越大文件就越大,杂志就要300以上
x=np.linspace(-np.pi*2,np.pi*2,100)
plt.figure(1,dpi=50)#dpi是精度
for i in range(1,5):#四条线
plt.plot(x,np.sin(x/i))
plt.show()
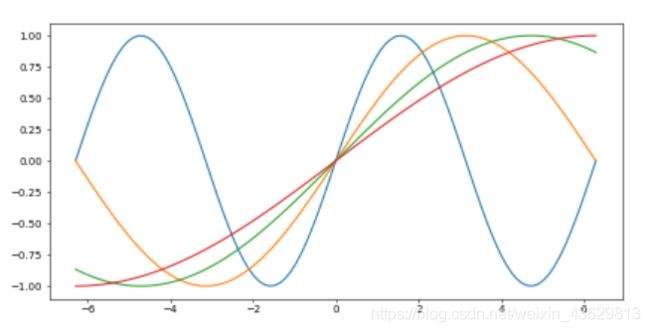
4)绘制直方图
plt.figure(1,dpi=50)#dpi是精度
data=[1,1,1,2,3,4]
plt.hist(data)#只要传入数据,直方图就会统计传入的数据
plt.show()
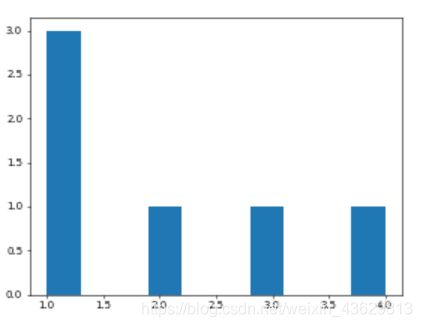
5)散点图
x=np.arange(1,10)
y=x
fig=plt.figure()
plt.scatter(x,y,c='r',marker='o')#c='r'指颜色红色,marker指定点形状
plt.show()
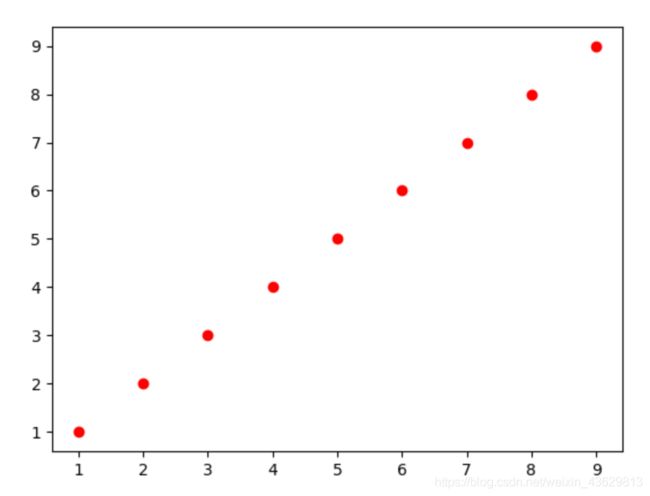
6)使用csv数据画有分类(不同颜色)的散点图
思路是使用pandas读取csv,但是绘出的图是单一色调,如果想要依据某一列的数对点进行分类也就是颜色上的区分,我们引入seaborn库
可以在官网找实例学习,都有详细的代码的。(还有matplotlib库官网实例可学习一下)
数据使用的是常见的iris数据集,可以在UCI机器学习库中找到,数据中的virginica列是鸢尾花(iris)的分类,我们就以这一列来区分不同点,赋予不同的颜色,便于后期分析。
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")#处理warning,忽略
iris=pd.read_csv("./iris_training.csv")
sns.set(style="white",color_codes=True)
#FacetGrid一般绘图函数
#hue使用彩色显示分类,virginica有0/1/2三种取值,所以会显示三种颜色
#add_legend显示分类的描述信息
#setosa,versicolor是x,y轴,使用map改变使用的不同的列
sns.FacetGrid(iris,hue="virginica",size=5).map(plt.scatter,"setosa","versicolor").add_legend()
plt.show()