爬取了 31502 条北京自如租房数据,看看是否居者有其屋?


作者 | 小狮子是LEO
责编 | 郭芮
自如友家作为北京租房的主要途径之一,租房数据都展示在官方网站之上,价格等房屋信息与网站数据一致,数据可信度较高、格式规整。因而选取自如友家官方网站作为租房数据的获取来源,分析自如友家的租房数据,可以一定程度上反映出北京的租房现状。
本文的具体思路如下:
首先使用爬虫获取租房数据,定时爬取自如官网8月9日到9月8日之间展示的合租信息,爬取间隔为每天一次。
然后使用Pandas对获取的数据进行数据清洗,去除数据中的无效及重复部分,最终获取租房数据的总数为31502条。
最后依据获取的租房数据对北京自如友家的房租价格、房屋数量、房屋分布、房屋属性等信息做定量分析,同时定性分析影响房屋价格的因素。

房租价格
1、总体价格
8月9日到9月8日30天内北京自如友家单个房间的平均房租为2781元,最低价格1030元,最高价格6830元,具体的价格分布如下。
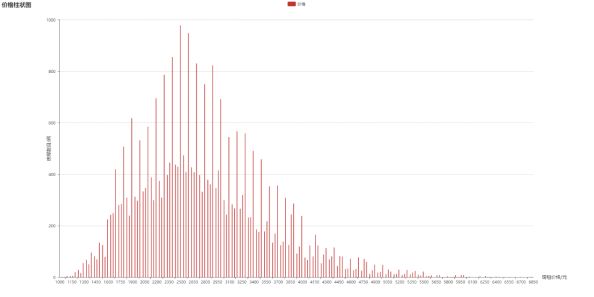
由图可知自如合租的单个房间价格大多分布在2000元与3000元价格档位,其中2500元附近分布最为密集。
自如友家房的租金价格分为XX30、XX60、XX90三种,同一价格区间内三者数目依次递增,大多数房间定位的价格为XX90,图中分布较高的柱形均为XX90。
2、各区价格
为了能够客观地比较北京各个行政区域的租金价格差异,将北京各个行政区域的租金分布绘制成箱型图,X轴各行政区按照平均价格由高到低排列。由图可见北京平均房租价格最高的为西城区,平均价格为3504元,平均房租最低的为门头沟区,平均价格为1574元。
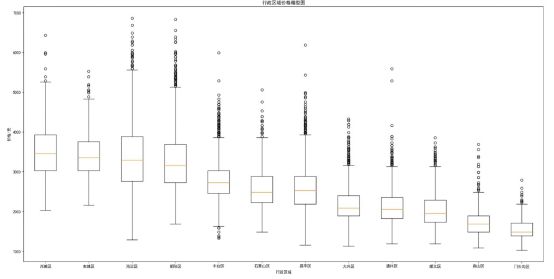
由箱型图大致可以看到各个行政区的房租分布情况,其中房租差距最大的为海淀区,房租差距最小的为门头沟区。
3、价格趋势
计算30天内每日的平均房租价格,绘制自如友家房租的价格趋势图如下。
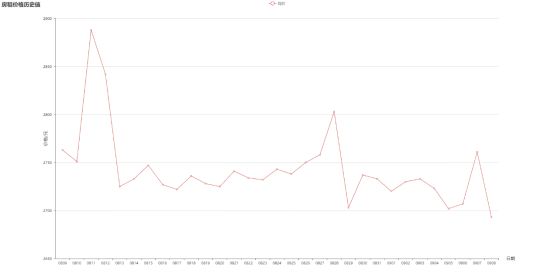
8月9日自如网站所有合租房源均价为2763元,9月8日房租均价为2693元,30天之内大部分日期的房租平均价格位于2700元到2750元之间,最高价格为8月11日的2888元,最低价格为9月8日的2693元,总体而言房租价格稳定且呈略微下降的趋势。房租均价的下降可能与毕业季租房高峰结束有关。

房屋数量
本次总计获取的房租数据总数为31502条,而自如网站上展示的房源有部分处于已出租状态,因而一个月以内可以出租的房源应该小于这一数目。计算每日自如网站的租房信息条数并绘制每日在线房屋数量变化图如下。
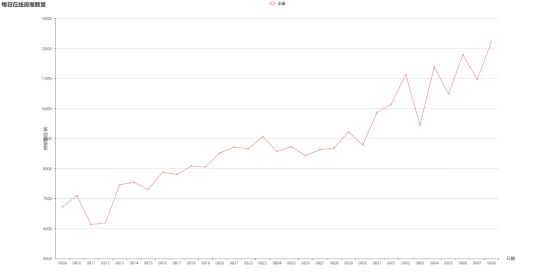
30天内房屋数量最多的为9月8日的12223间,房屋数量最少的为8月11日的6113间,从8月12日开始自如网站的每日在线房屋数量一直处于上升状态,并且较之前的房屋数目有了非常大的提升,推测这可能与前一段时间北京市约谈有关。

房屋分布
1、分布热力图
七月份曾通过爬虫抓取自如的每一个租房页面获取房屋的详细信息,三次共获取租房信息14850条,其中包含了房屋的经纬度信息,以此为基础使用百度地图API绘制北京自如友家的房屋分布热力图如下。
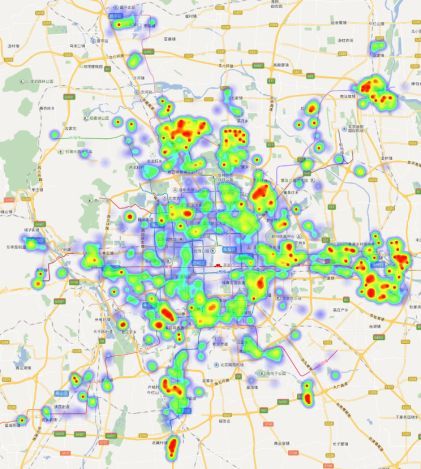
由图中分布可以看出自如房屋分布最密集的部分有:回龙观、天通苑、望京、顺义(15号线末端)、通州(八通线与6号线末端)、丰台科技园(地铁首经贸与科怡路站周边)、罗庄东里、劲松、枣园、天宫院等。
2、各区比例
统计自如友家在各个行政区的房屋分布如下图所示。
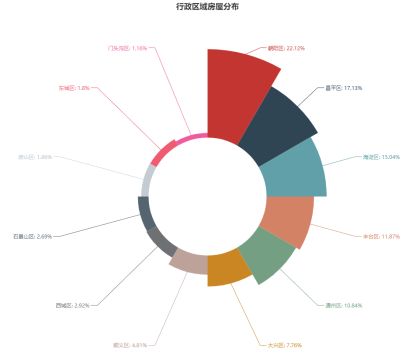
分布数量最多的是朝阳区,占房屋总量的22.12%,分布数量最少的是门头沟区仅占房屋分布总量的1.16%。
3、小区分布
相对于行政区,小区的划分更加精细,能够反映除房屋自身属性以外的其它属性,如位置、交通、生活的便利程度等,因此根据统计数据分析自如各个小区的房屋分布情况,取前50名如下图所示,字体越大表示房屋数量越多。

可见龙冠冠华苑是八月北京自如友家房屋分布数量最多的小区。图中小区大多分布在热力图中的红色位置,能更确切地说明自如友家的房屋分布状况。

房屋属性
1、房屋面积
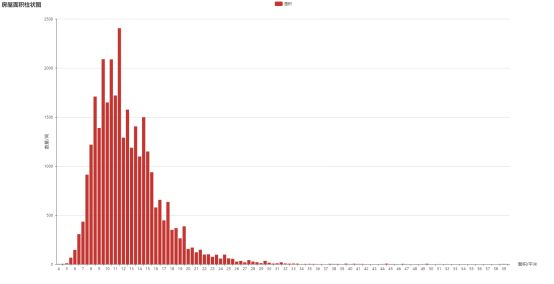
统计获取的所有房屋的面积如下,最小房屋面积为4.5平米,最大房屋面积为59.6平米,平均面积为12.86平方米,大部分的房屋分布在8平米到15平米之间,其中11.5平米左右与14.5平米左右房屋分布最为密集,推测两个峰值的出现可能次卧,主卧有关。
2、房屋类型
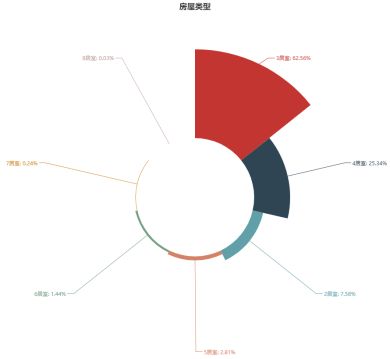
由房屋类型的分布图可知,自如友家绝大部分的出租房源为三居室,占据所有房源的62.56%,房间数目最多的为8居室占据所有房源的0.03%。
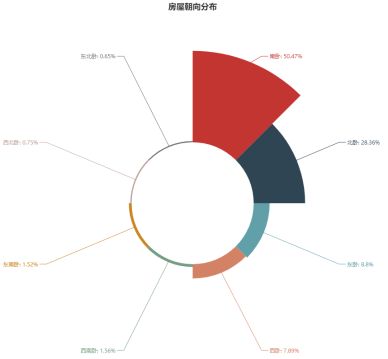
3、房屋朝向
统计所有房屋的朝向,可见自如房间的朝向总计有8种,其中南向卧室的比例最多,房屋朝向主要为南、北、东、西等比较正常朝向,但比较奇怪的朝向也占据了所有房屋的4.48%。
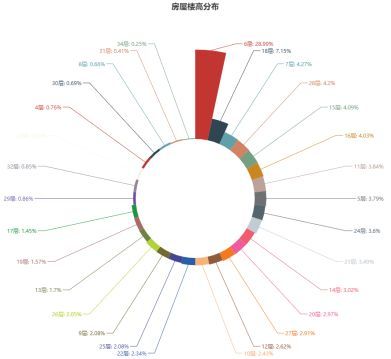
4、楼高分布
由自如房源的楼高分布图可知,自如友家所在的小区楼高最多的为6层,占据总数的28.99%,一般来讲6层楼高的多为比较老的小区。

房租价格定性分析
房租价格影响因素较多,并非简单的线性关系,很难定量得出房价与各影响因素的关系,因而下面定性地分析影响房租价格的各项因素。
首先由北京各地区房租分布的差异可知房屋位置是影响房租价格的主要因素,为分析除此之外影响房屋价格的其它因素,本文采用房屋数量最多的小区内所有的房源作对比分析。将房间的朝向、房间的面积,房间的价格绘制在同一张散点图中,红色的表示南向卧室,深蓝色的表示北向卧室。
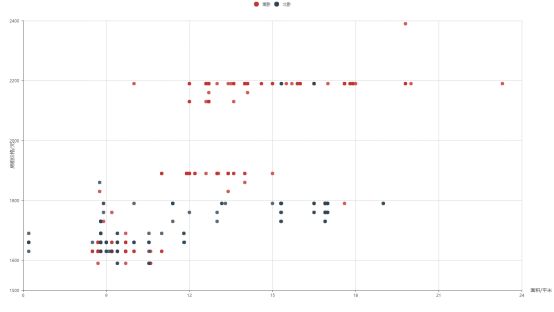
如图所示南向房间价格总体高于北向卧室价格,可见房间朝向对于房租有一定的影响,南向卧室价格较高。
随着房屋面积的增加,房租成上升趋势,但二者并不成正比,一定范围内房间面积对房租价格影响不大,例如该小区15到20平米内南向房租价格基本无变化。
在散点图中南向房间12到15平米内价格聚集在两个1890与2190两个价格区间,产生此种差异的原因是因为房屋户型不同,2190的房屋基本都有阳台,1890的房屋基本没有阳台,因而是否带有阳台也是是影响房租价格的因素之一。
综上影响房租的因素除房屋位置外还包含,房屋朝向、房屋面积、房屋户型等。

代码实现
本文篇幅有限,无法展示所有代码,因而选取部分主要代码,重在表述实现思路。
1、数据获取
数据获取的思路是使用Python爬虫爬取自如友家网站的租房数据,具体方案如下:
使用selenium及PhantomJS模拟浏览器网站,不选取Chrome-headless的原因是PhantomJS可以更加方便的实现整个网页的截图。按行政区域爬取租房数据,主要代码如下:
1.def getinfo(Area,FileName):
2. print(Area)
3. print('开始网页get请求')
4. # 使用selenium通过PhantomJS来进行网络请求
5. driver = webdriver.PhantomJS()
6. driver.implicitly_wait(10)
7. driver.maximize_window()
8. driver.get(web_url)
9. search(driver, Area) # 切换租房地点
10. url = ''
11. oldurl = ''
12. # 获取房屋信息的总页数
13. page = driver.find_element_by_css_selector('span.pagenum')
14. pagenum = page.text
15. pagenum = pagenum.replace('1/', '')
16. print(pagenum)
17. #页数小于五十不需做特殊处理
18. if pagenum != "50":
19. while True:
20. getonepageinfo(driver,Area,FileName)#获取一页的租房信息
21. try:#尝试翻页
22. nextbutton = driver.find_element_by_css_selector('a.next')
23. url = nextbutton.get_attribute('href')
24. if url == oldurl:
25. break
26. oldurl = url
27. nowTime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
28. print(nowTime)
29. driver.get(url)
30. except:
31. print("ERROR!")
32. break
33. #页数大于五十为避免数据缺失按街道爬取数据
34. else:
35. BS = BeautifulSoup(driver.page_source, 'lxml')
36. Arealist = BS.find('ul', class_='clearfix filterList')
37. for area in Arealist.contents[3:-1:2]:
38. nameList = area.stripped_strings
39. areaName = list(nameList)[0]
40. littleAreaList = area.div.contents[3:-1:2]
41. #按街道爬取数据
42. for littleArea in littleAreaList:
43. if areaName == Area:
44. print(littleArea.a.string)
45. driver.get('http:' + littleArea.a.get('href'))
46. while True:
47. getonepageinfo(driver,Area,FileName)
48. try:
49. nextbutton = driver.find_element_by_css_selector('a.next')
50. url = nextbutton.get_attribute('href')
51. if url == oldurl:
52. break
53. oldurl = url
54. nowTime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
55. print(nowTime)
56. driver.get(url)
57. except:
58. print("ERROR!")
59. break
driver.quit()
使用BeautifulSoup解析HTML,获取名称、面积、楼层等房屋属性信息。自如网站的房屋租金为了防止爬取做了特殊处理,因而使用pytesseract识别截图中的价格信息,代码如下:
1.def getonepageinfo(driver,Area,FileName):
2. print(Area)
3. try:
4. #获取整个网页的截图
5. driver.save_screenshot('D:\\aaa\\shot'+Area+'.png')
6. BS = BeautifulSoup(driver.page_source, 'lxml')
7. houseList = BS.find_all('li', class_='clearfix')
8. rangles = []
9. RoomDetails = driver.find_elements_by_css_selector('li.clearfix')
10. #获取所有价格信息的位置
11. for RoomDetail in RoomDetails:
12. priceelement = RoomDetail.find_element_by_css_selector('p.price')
13. location = priceelement.location
14. size = priceelement.size
15. rangle = (int(location['x'] + 90), int(location['y']), int(location['x'] + 180),
16. int(location['y'] + size['height']))
17. rangles.append(rangle)
18. HouseNo = 0
19. #获取房屋的详细属性
20. for house in houseList:
21. title = house.find('a', class_='t1').string#房屋名称
22. url = house.find('a', class_='t1')['href']#房屋url
23. i = Image.open('D:\\aaa\\shot'+Area+'.png') # 打开截图
24. frame4 = i.crop(rangles[HouseNo]) # 使用Image的crop函数,从截图中再次截取我们需要的函数
25. frame4.save('D:\\aaa\\price'+Area+'.png')
26. price = pytesseract.image_to_string(Image.open('D:\\aaa\\price'+Area+'.png'))#房屋价格
27. detail = list(house.find('div', class_='detail').stripped_strings)
28. roomarea = detail[0]#房屋面积
29. floor = detail[2]#房屋楼层
30. type = detail[4]#房屋类型
31. roomlocation = Area
32. pagestr = roomlocation + ',' + title + ',' + url + ',' + price + ',' + roomarea + ',' + floor + ',' + type + '\n'
33. HouseNo = HouseNo + 1
34. try:
35. with open(FileName, 'a+') as f:
36. f.write(pagestr)
37. except:
38. print('GET PRICE ERROR !')
39. except:
print('GET Room INFORMATION ERROR !') 2、数据清洗
由于爬取的数据存在重复数据及错误数据,因而本文使用Pandas做数据清洗,去除重复及错误部分。
1.column_names= ['district', 'name', 'url', 'price','area','floor','type']
2.roomdataframehis = pd.DataFrame(columns=column_names)
3.
4.print("try to convert file code..............\n")
5.#首先读取原始文件去除不符合GBK编码的字符及价格不合理数据
6.for file in os.listdir('D:\\ZIROOM\\ziroomdataprocess\\dirty'):
7. roomdata = pd.read_csv('D:\\ZIROOM\\ziroomdataprocess\\dirty\\' + file,names=column_names,encoding="ISO-8859-1",dtype = {'price' : str})
8. roomdataframe = pd.DataFrame(roomdata)
9. roomdataframe = roomdataframe.dropna() # rmove na data
10. # 去掉价格不合理的所有房屋
11. allist = ['(§']
12. roomdataframe = roomdataframe[~roomdataframe['price'].isin(allist)] # rmove incorrect data
13. roomdataframe.to_csv('D:\\ZIROOM\\ziroomdataprocess\\clean\\' + file, encoding="ISO-8859-1",index=False, header=False)
14.print("try to clean data..............\n")
15.for file in os.listdir('D:\\ZIROOM\\ziroomdataprocess\\clean'):
16. print(file)
17. roomdata = pd.read_csv('D:\\ZIROOM\\ziroomdataprocess\\clean\\'+file,names = column_names,encoding="gbk",dtype = {'price' : str})
18. roomdataframe = pd.DataFrame(roomdata)
19. #去掉所有包含空值的数据
20. roomdataframe=roomdataframe.dropna()#rmove na data
21. #去掉所有不是合租的房源
22. roomdataframe=roomdataframe[roomdataframe['name'].str.contains('友家')]
23. #去掉所有不合理价格
24. roomdataframe = roomdataframe[(roomdataframe['price'].str.len()<5)&(roomdataframe['price'].str.isdigit())]
25. #处理住房面积
26. roomdataframe['area']= roomdataframe['area'].str.replace('约','')
27. roomdataframe['area']= roomdataframe['area'].str.replace('㎡', '')
28. roomdataframe['area']= roomdataframe['area'].astype(float)
29. roomdataframe= roomdataframe[(roomdataframe['area']<60)&(roomdataframe['area']>4)]
30. #去掉重复数据
31. roomdataframe.drop_duplicates(subset=['url'],keep='first',inplace=True)
32. #对房间类型进行前期处理
33. roomdataframe['type']=roomdataframe['type'].str[0]
34. #对数据进行排序
35. roomdataframe=roomdataframe.sort_values(by=['district','price'],axis = 0,ascending = True)
36. roomdataframe.to_csv('D:\\ZIROOM\\ziroomdataprocess\\clean\\'+file,encoding="gbk",index=False,header=False) 3、数据分析
数据分析部分使用百度地图API及pyecharts对数据进行可视化分析,由于绘制的图表较多,百度地图API以热力图作为例子,pyecharts以玫瑰饼图作为例子。
热力图:
1.import pandas as pd
2.column_names= ['code','name','area','direction','price','lon','lat','district','url']
3.roomdataframehis = pd.DataFrame(columns=column_names)
4.#读取HTML文件头
5.fo = open("htmlheader", "r",encoding="utf-8")
6.filehead = fo.read()
7.#读取HTML文件位
8.fo = open("htmlend", "r",encoding="utf-8")
9.fileend = fo.read()
10.#生成HTML中经纬度部分
11.roomdata = pd.read_csv('D:\\ZIROOM\\ziroomdataprocess\\all\\All.csv',index_col=False,names = column_names,encoding="gbk")
12.roomdataframe = pd.DataFrame(roomdata)
13.points =''
14.for indexs in roomdataframe.index:
15. linedata = roomdataframe.loc[indexs]
16. points+='{'+'"lng":'+str(linedata['lon'])[0:9]+','+'"lat":'+str(linedata['lat'])+','+'"count":'+'5},\n'
17.
18.fo = open('hot.html','w',encoding='utf-8')
19.#生成热力图HTML文件
20.fo.write(filehead)
21.fo.write(points)
22.fo.write(fileend)
23.fo.close() 玫瑰饼图:
1.#绘制房屋类型玫瑰饼图
2.type = []
3.typenumber = []
4.TypeMax = roomdataframe['type'].max()
5.Type = 2
6.while True:
7. roomdataframetmp = roomdataframe[roomdataframe['type']==Type]
8. type.append(str(Type)+'居室')
9. typenumber.append(len(roomdataframetmp['type']))
10. Type = Type +1
11. if Type>TypeMax:
12. break
13.data = list(zip(type,typenumber))
14.data.sort(key= lambda x:(x[1]),reverse=True)
15.type = [x[0] for x in data]
16.typenumber = [x[1] for x in data]
17.typepie = Pie("房屋类型", title_pos='center', width=1800,height=900)
18.typepie.add(
19. "房屋类型",
20. type,
21. typenumber,
22. is_random=False,
23. radius=[30, 75],
24. rosetype="area",
25. is_legend_show=False,
26. is_label_show=True,)
27.typepie.render('typepie.html') 4、参考资料
Selenium文档:
https://selenium-python-zh.readthedocs.io/en/latest/
BeautifulSoup文档:
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
百度地图API文档:
http://lbsyun.baidu.com/index.php?title=jspopular
Pyecharts文档:
http://pyecharts.org/#/zh-cn/charts_configure

写在最后
自如友家的房租定价与北京市房租基本呈正相关,因而本次对自如友家八月份租房数据的分析,一定程度上可以作为北京租房市场的参考。
从七月份房租暴涨到八月份房租趋于稳定,相关部门的约谈与监管起到了非常重要的作用。希望在相关部门监管及民众的关注下,房屋租赁市场能够健康发展,使居者有其屋,在高房价的社会中给年轻人一丝喘息的机会。
作者:小狮子是LEO,苦逼软件工程师,业余Python爱好者。
声明:本文为作者独家原创投稿,未经允许请勿转载。
“ 征稿啦”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱([email protected])。
————— 推荐阅读 —————




