python数据表合并、stack函数、数据分块读取
- 数据表的合并
- stack函数
- 数据分块读取
1.concat
2.join
3.merge
merge类似sql里面的join,连接方式有inner(默认),left,right,outer几种模式。对应为内连接、左连接、右连接、全连接。
InnerMerge(内连接)
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
dframe1=DataFrame({'key':['X','Z','Y','Z','X','X'],'vaule_df1':np.arange(6)})
dframe2=DataFrame({'key':['Q','Y','Z'],'vaule_df2':[1,2,3]})
df=pd.merge(dframe1,dframe2)
print(df)
key vaule_df1 vaule_df2
0 Z 1 3
1 Z 3 3
2 Y 2 2X仅存在于dframe1的key,在dframe2中不存在,为了更清晰的了解merge的连接方式,我们换一种写法:
pd.merge(dframe1,dframe2,on='key',how='inner')这种写法得到与上文写法相同的结果,据此我们可以知道:如果我们不通过on和how来指定merge的公有列或者方式,那么pd.merge就会自动寻找到两个DataFrame的相同列并自动默认为inner join。下文我们将在实践中运用merge:
这里有四个文件,分别为text_left_up、 text_left_down、text_right_up 、text_right_down。我们需要将上部分的左右数据按列连接,下部分数据同理;然后再将上下部分数据连接形成一张完整的表。这里需要注意的是,我们不需要对数据进行筛选去重等处理,仅仅执行连接操作,那么如何运用merge呢?操作如下~~
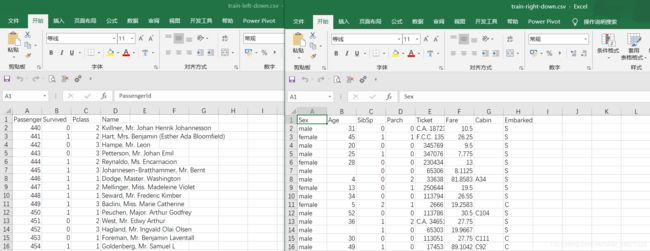
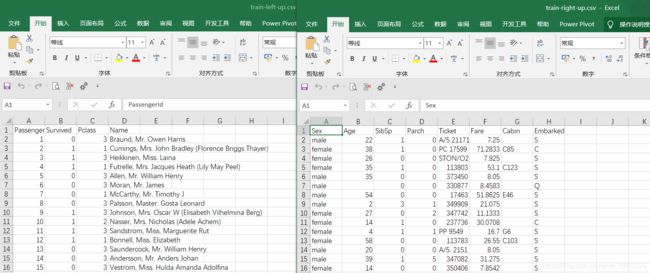
text_left_up = pd.read_csv("C:/Users/HP/Desktop/doc/data/u2/data/train-left-up.csv")
text_left_down = pd.read_csv("C:/Users/HP/Desktop/doc/data/u2/data/train-left-down.csv")
text_right_up = pd.read_csv("C:/Users/HP/Desktop/doc/data/u2/data/train-right-up.csv")
text_right_down = pd.read_csv("C:/Users/HP/Desktop/doc/data/u2/data/train-right-down.csv")
result_up=pd.merge(text_left_up,text_right_up,left_index=True,right_index=True)
result_down=pd.merge(text_left_down,text_right_down,left_index=True,right_index=True)
result1=result_up.append(result_down)
result2=pd.merge(result_up,result_down)
print(result1.head())
print('this is result2',result2.head())
[5 rows x 12 columns]
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]
this is result2 Empty DataFrame
Columns: [PassengerId, Survived, Pclass, Name, Sex, Age, SibSp, Parch, Ticket, Fare, Cabin, Embarked]
Index: []观察输出可知,result2使用merge连接上下部分没有公共index的数据 将返回空的DataFrame
df=pd.merge(dframe1,dframe2,left_index=True,right_index=True) 使用merge实现左右连接
df=pd.merge(dframe1,dframe2) 使用merge实现内连接
LeftMerge(左连接)
df=pd.merge(dframe1,dframe2,on='key',how='left')
key vaule_df1 vaule_df2
0 X 0 NaN
1 Z 1 3.0
2 Y 2 2.0
3 Z 3 3.0
4 X 4 NaN
5 X 5 NaN输出结果返回的是dframe1的所有key值对应的结果,如果在dframe2中不存在,显示为Nan空值
RightMerge(右连接)
df=pd.merge(dframe1,dframe2,on='key',how='right')
key vaule_df1 vaule_df2
0 Z 1.0 3
1 Z 3.0 3
2 Y 2.0 2
3 Q NaN 1Q只存在于dframe2中
OuterMerge(全连接)
df=pd.merge(dframe1,dframe2,on='key',how='outer')
key vaule_df1 vaule_df2
0 X 0.0 NaN
1 X 4.0 NaN
2 X 5.0 NaN
3 Z 1.0 3.0
4 Z 3.0 3.0
5 Y 2.0 2.0
6 Q NaN 1.0全连接结果为两个集合的并集,是一个union的结果,merge会把key这一列在两个Dataframe出现的所有值全部显示出来,如果有空值显示为Nan
4.stack函数作用
使用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”。
常见的数据层次化结构如下:花括号和表格
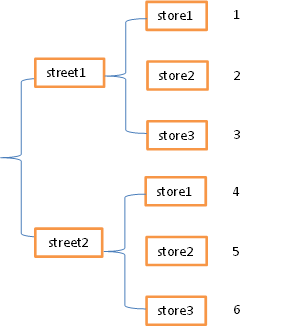
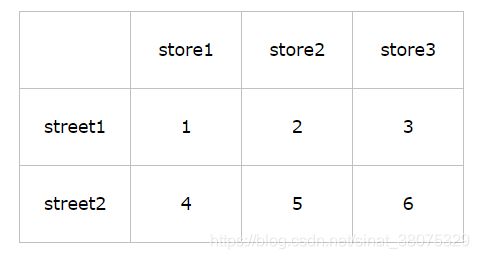
表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。
