CLOCs:3D目标检测多模态融合之Late-Fusion
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

本文转载自「计算机视觉工坊」,该公众号重点在于介绍深度学习、智能驾驶等领域,一个小众的公众号。
文章:CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection
论文地址:在公众号「3D视觉工坊」,后台回复「Late-Fusion」,即可直接下载。
0 前言
目前很多3D目标检测的工作都朝着多模态融合的方向发展,即是不仅仅使用单张图像或者仅仅使用点云做3D目标检测任务,而是在融合这两种传感器信息上作出一定的探索,今天笔者想要分享的一篇研究工作即是在这方面比较新的文章。论文
笔者给出该文章目前在KITTI object 3d的实验效果如下.(本文介绍的这篇文章于20.9.1放置在arxiv上,并不是下图对应的IROS的文章,但是是同一个作者)![]()
KITTI检测结果可视化如下。
1 背景知识
1.1 三种多模态融合的方法
不仅仅是指点云和图像的两种模态的信息融合方法,一般的来讲针对多模态信息的融合一般有如下的几种方式。
Early-Fusion
Early-Fusion 即是在对原始传感器数据做特征提取之前做特征融合。在3D目标检测中有文章pointpainting(CVPR 20),PIRCNN(AAAI20)等文章采用这种方式,就pointpainting而言,首先是对image图像做语义分割,然后将分割后的特征通过点到图像像素的矩阵映射到点云上。再经过深度学习网络对Bbox回归。就理论上讲,该种融合方法是多模态融合的可能最好的方法,因为此时对应的特征在现实中存在一定的索引关系和更少的特征抽象。
Deep Fusion
如下图所示的融合方法,该融合需要在特征层中做一定的交互。目前就3D目标检测多模态的研究中,存在的文章有今年ECCV的EPNet,3的CVF等文章,就EPnet而言,主要的融合方式是对lidar 和image分支都各自采用特征提取器,对图像分支和lidar分支的网络在前馈的层次中逐语义级别融合,做到multi-scale信息的语义融合。这是这里提到的三种融合方法中比较难,也是最可能创造出新的融合方法的融合方式。
Late fusion
如下图所示,最简单的融合方法就是两种模态的特征不在特征层或者最开始就融合,因为不同传感器的数据本身存在比较大的差异,就LiDAR和Image而言,最大的差异就在view的不同,导致在图像上存在物体scale随距离的不同而改变,但是在点云上不存在这个问题;此外,笔者认为图像和点云做特征层的融合最大的难点也在像素和点云点之间索引精准性和领域差异的问题。就本文介绍的这篇文章而言,采用了late fusion的融合方法,因此作者自己给出的本文的优势在于该融合方式是low-complexity的。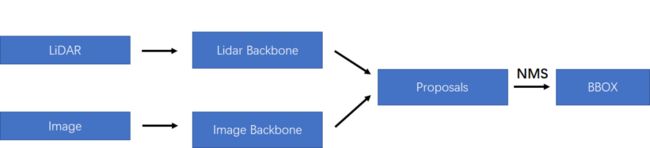
总结一下上诉提到的三种融合方式,其中第一种的early-fusion实际上是在最初的输入上的融合,而deep-fusion则是在特征层面上的融合,最后的late-fusion则是对应在决策层上的融合。
1.2 主要的几种多模态融合方法
目前3D目标检测的多模态融合的方法可以从最早的F-pointnet说起(CVPR17),PointFusion(CVPR18),Frustum ConvNet(ICRA18)都是通过2D目标检测器首先生成Bbox,然后再采用投影到三维点云上做进一步对Bbox做优化工作,该类方法对2D的检测的效果比较依赖。后续是AVOD(CVPR18)和MV3D(CVPR17),从BEV视图上对点云做特征提取,但是该类方法存在点云到BEV视图的压缩时丢失几何结构信息。MMF(CVPR19)将点云BEV视图信息和图像信息在point-wise级别上做特征融合。
2. 本文的工作
2.1 主要创新点
1. Versatility & Modularity
本文的方法使用任何一对预先训练好的2D和3D检测器,而不需要再训练,因此,可以很容易地被任何相关的已经优化的检测方法所使用。
2. Probabilistic-driven Learning-based Fusion
CLOCs的设计目的是利用二维和三维检测的几何和语义一致性,自动学习训练数据的概率依赖进行融合。
4. Detection Performance
CLOCs改进了单模态检测器的检测性能,以达到新的水平。
2.2 主要工作
1. 怎么做点云和图像的融合工作
笔者前面介绍了目前流型的三种常用的多模态特征融合工作,而本文采用的则是在决策层面的特征融合,即是late-fusion,这样融合的好处在于两种模态的网络结构之间互不干扰,可以独自训练和组合;但是也存在一定的缺点就是在决策层做融合实际上是对原始数据信息融合的最少的。同样就前文中描述的late-fusion存在的问题而言,两种模各自产生对应的proposals,每个proposals在对应的模态中的置信分数是不存在联系的,因此需要解决的问题之一就是让多模态之间产生的proposals置信分数存在联系。
2. 如何让不同模态的proposals存在联系
也就是上面提到的问题,这里的话,作者采用的方式是Geometric-consistency和Semantic-consistency这两种。
1)Geometric-consistency:基于如下图所示的这种观察:如果说在二维检测和三维检测上都同时检测到这个物体,并且都是ture-positive的,那么这中情况下二维和三维对应的角点是大概率一致,或者存在比较小的偏差。但是如果该检测结果是flase-positive的,那么两种检测器之间的检测结果就大概率是在角点上对不上的。因此作者认为这种几何结构一致性是可以作为检测结果的一种联系。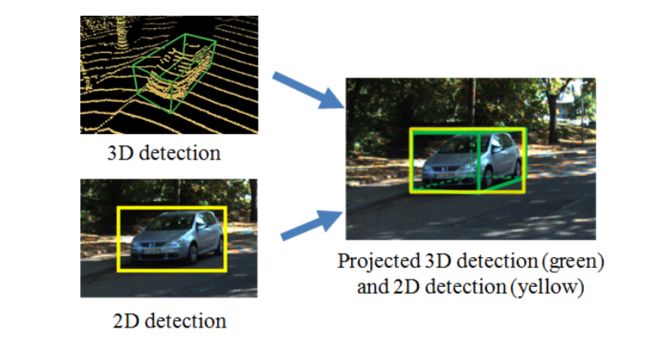
2)Semantic consistency: 因为对于每一个模态的检测器而言,可能都存在多种类别的输出,作者在融合阶段仅仅只是对同类别的object做融合。
3. 网络结构的设计
主要的网络结构图如下所示,这里可以看出经历了三个主要的阶段(1)2D和3D的目标检测器分别提出proposals(2)将两种模态的proposals编码成稀疏张量(3)对于非空的元素采用二维卷积做对应的特征融合。
1)稀疏张量编码
对于二维图像检测出来的二维检测结果,如下图所示,作者采用混合表示的方式表示两种模态的的检测结果,其中第一项表示在图像中的第i个检测结果和点云中的第j个的几何一致性(也就是前面提到的Geometric-consistency,这里用IOU表示),第二项内容是二维检测的第i个检测到的物体的置信度分数,第三个为在点云场景下的置信度分数。最后一项表示在点云场景下检测到的第j个物体到地面的归一化距离。这样就可以把该结果表示为一个系数的四维张量,后续可直接输入卷积网络做融合。
2) 网络细节设计
尽管采用的二维卷积对上述的稀疏张量做特征融合,其对应的需求仅仅是融合而不是感知,所以在卷积核的设计上作者采用的1×1的核大小。如网络结果图所示的详细的网络参数,最后采用maxpooling的方式选择最终的融合结果。
3. 实验
在KITTI的test数据集的BEV视图上的实验结果如下,因为本文实际上提出的是一种融合方法,并不是某种确定的网络结构,因此对于二维检测器和三维检测器的选择上纯在多种可能,就作者的实验可以看出,PV-RCNN+Cascad RCNNd的实验效果是最好的。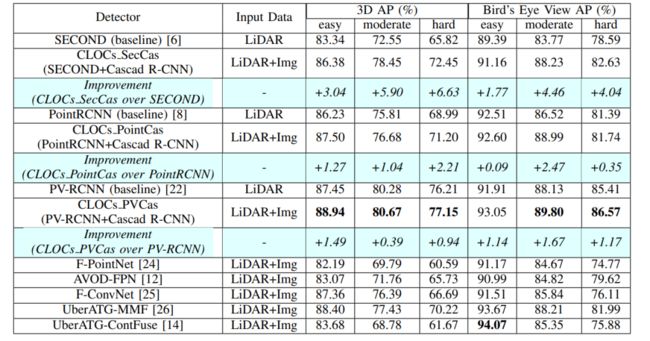
此外,在val数据集上,作者采用当前流型的几种二维目标检测和三维目标检测的网络结合的实验如下。但是这里笔者需要提到的是,这里采用的是最新的Recall40的结果而不是前几年的reall11的结果,因此显得比较高也是正常的,但是笔者也认为这里应该给出对应的使用点云的单模态的精度结果。
4. 笔者的思考
就本文的内容而言,笔者认为相对以往的融合工作来说还是容易的,但是作者选择了最容易操作的late-fusion模式,利用了late-fusion中单模态检测器之间互不干扰的特性做了多种检测器的组合,因此这是值得借鉴和推广的。
不过笔者还是想提出的就是目前的融合工作更多地都是采用第二种deep-fusion的方式,原因主要是这种融合方式的自由度更大,在特征层的融合可以实现不同传感器信息之间的互补,而不采用early-fusion的方式则是因为这种融合方式则是该阶段会存在更多的视角,特征表示上的差距导致了融合困难。
最后笔者也想推荐一下最近笔者整理的一个项目,该项目主要针对自动驾驶场景的3D目标检测的论文和项目的汇总。方便大家查阅最新的文章。该项目地址为:https://github.com/LittleYuanzi/awesome-Automanous-3D-detection-methods
参考文献
[1] CLOCs: Camera-LiDAR Object Candidates Fusion for 3D Object Detection :https://arxiv.org/pdf/2009.00784.pdf
[2] PI-RCNN: An Efficient Multi-sensor 3D Object Detector with Point-based Attentive Cont-conv Fusion Module :https://arxiv.org/pdf/1911.06084
[3]PointPainting: Sequential Fusion for 3D Object Detection. https://arxiv.org/pdf/1911.10150
[4]EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection. https://arxiv.org/pdf/2007.08856
[5]Deep Continuous Fusion for Multi-Sensor 3D Object Detection. http://openaccess.thecvf.com/content_ECCV_2018/papers/Ming_Liang_Deep_Continuous_Fusion_ECCV_2018_paper.pdf
[6]End-to-end Learning of Multi-sensor 3D Tracking by Detection. https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8462884
[7] IPOD: Intensive Point-based Object Detector for Point Cloud. https://arxiv.org/abs/1812.05276
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「3D视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「3D视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计汇总等。
下载3
在「3D视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 