Python网络爬虫与信息提取笔记08-实例2:淘宝商品比价定向爬虫
Python网络爬虫与信息提取笔记01-Requests库入门
Python网络爬虫与信息提取笔记02-网络爬虫之“盗亦有道”
Python网络爬虫与信息提取笔记03-Requests库网络爬虫实战(5个实例)
Python网络爬虫与信息提取笔记04-Beautiful Soup库入门
Python网络爬虫与信息提取笔记05-信息组织与提取方法
Python网络爬虫与信息提取笔记06-实例1:中国大学排名爬虫
Python网络爬虫与信息提取笔记07-Re(正则表达式)库入门
本文索引:
- “淘宝商品信息定向爬虫”实例介绍
- “淘宝商品信息定向爬虫”实例编写
1、“淘宝商品信息定向爬虫”实例介绍
淘宝大家都不陌生,官网在这:https://www.taobao.com/,我们今天要说的不是人直接去搜素商品,而是让一段代码自动搜索:
功能描述:
目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格。
理解:处理淘宝的搜索接口
翻页的处理
技术路线:requests库和re库
我们先来看一下淘宝的robots协议,https://www.taobao.com/robots.txt,我们可以看到,淘宝是不允许爬虫来爬取它的搜索页面的
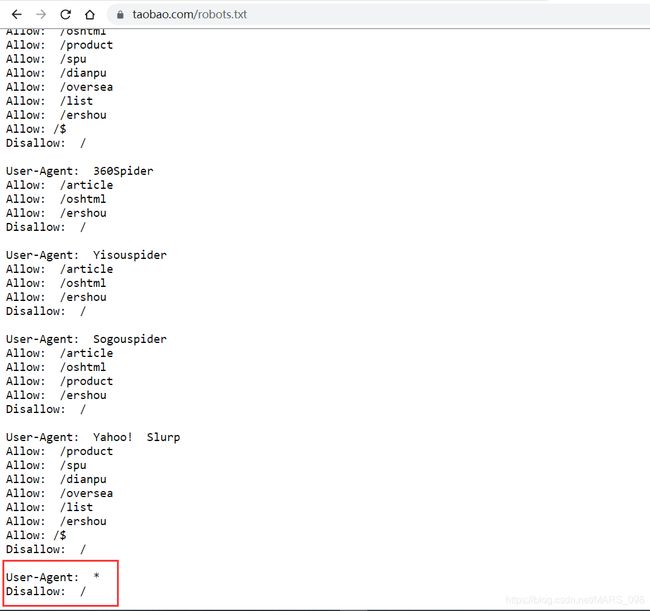
那怎么办?难道我们就放弃这个实例嘛?其实我们之前说过,大部分爬虫被限制的主要原因是因为它不加限制的高频率爬取网站界面,如果完全放任,会对服务器造成很大的负担,但如果我们访问请求的频率与人类似,不会对网站造成太大压力,是可以用于研究和教学探索的,所以我们会接着完成这个实例。
注意:网络爬取有风险,请再次阅读Python网络爬虫与信息提取笔记02-网络爬虫之“盗亦有道”,也个大家一个建议,在写网络爬虫的时候,养成一个好习惯,先查看网站对网络爬虫的限制再决定,本篇只用于讲解原理,请各位不要用学到的东西肆无忌惮的在网络上爬取,造成后果与本人无关。
那么我们接着讲解这个实例的原理:
程序的结构设计:
步骤1:提交商品搜索请求,循环获取页面
步骤2:对于每个页面,提取商品名称和价格信息
步骤3:将信息输出到屏幕上
2、“淘宝商品信息定向爬虫”实例编写
我们分布讨论这个实例代码的编写步骤:
1、导入相关库requests和re
import requests
improt re2、定义三个主要功能函数和主函数:
# 获得页面的函数
def getHTMLText(url):
print("")
# 对获得页面进行解析,参数为结果的列表类型和相关html页面信息
def parsePage(ilt,html):
print("")
# 输出商品信息到屏幕
def printGoodsList(ilt):
print("")
def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = [] # 输出结果保存
for i in range(depth):
try:
url = start_url + '&s=' + str(48*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()3、接下里具体实现三个主要函数的功能编写
第一个getHTMLText(url)函数:
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
第二个parsePage(ilt,html)函数
首先,我们来查看下淘宝搜索书包页面的源代码:
可以看出来,商品的每一个名称和价格分别是用view_title和raw_price两个标签来组织的,
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"{\d.}*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(plt):
price = eval(plt[i].split(':')[1])
title = eval(tlt[1].split(':')[1])
ilt.append([price,title])
except:
print("")
print("")第三个printGoodsList()函数,设置输出排列格式,
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}" # 制表格式
print(tplt.format("序号","价格","商品名称")) # 输出表头
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
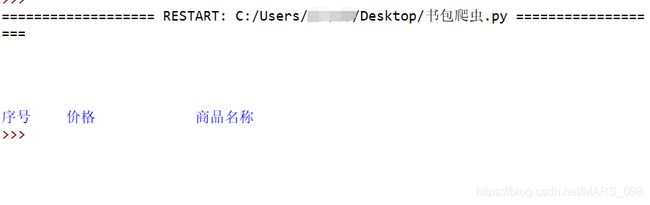
到这里,所有的完整代码已经写完了,但是其实,到目前为止,淘宝已经不允许爬取用户商品界面了,所以,这个例子算是失败了,但这只是对于不循序网络爬虫的网站,我们还可以用别的允许的网站测试,但也把这个完整代码贴出来,附运行结果:
import re
import requests
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def parsePage(ilt,html):
try:
plt = re.findall(r'\"view_price\"\:\"{\d.}*\"',html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"',html)
for i in range(plt):
price = eval(plt[i].split(':')[1])
title = eval(tlt[1].split(':')[1])
ilt.append([price,title])
except:
print("")
print("")
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"
print(tplt.format("序号","价格","商品名称"))
count = 0
for g in ilt:
count = count + 1
print(tplt.format(count,g[0],g[1]))
def main():
goods = '书包'
depth = 2
start_url = 'https://s.taobao.com/search?q=' + goods
infoList = [] # 输出结果保存
for i in range(depth):
try:
url = start_url + '&s=' + str(48*i)
html = getHTMLText(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
main()
运行结果:
这段代码仍旧有学习价值,这篇文章那个就看看就OK了,不要想着研究绕过淘宝的反爬虫机制,这样可能会造成非法后果,请小伙伴注意,一起加油吧。