推荐算法及其一个算法案例
三、推荐算法
1)推荐模型构建流程
Data(数据)—>Features(特征)—>ML Algorithm(选择算法训练模型)—>Prediction Output(预测输出)
- 数据清洗/数据处理
- 数据来源
- 显性数据
- 比如用户的评分、评价等
- 隐性数据
- 历史订单、点击记录、搜索记录
- 显性数据
- 数据量/数据能否满足要求
- 数据来源
- 特征工程
- 从数据中筛选特征
- 用数据表述特征
- 选择合适的算法
- 协同过滤
- 基于内容
- 产生推荐结果
- 对推荐结果进行评估
2)最经典的推荐算法:协同过滤
算法的思想:物以类聚,人以群分
基本的协同过滤推荐算法基于以下的假设:
- 跟你喜好相似的人喜欢的东西你也很有可能喜欢:基于用户的协同过滤推荐
- 跟你喜欢的东西相似的东西你也很有可能喜欢:基于物品的协同过滤推荐
实现协同过滤推荐的步骤:
-
1.找出最相似的人或物品:TOP-N相似的人或物品
通过计算两两的相似度来进行排序,找出TOP-N相似人或者物品
-
2.根据相似的人或物品产生推荐结果
利用TOP-N结果生成初始推荐结果,然后过滤掉用户已经有过记录的物品或明确表示过不喜欢的物品
3)相似度计算
相似度的计算方法
- 欧式距离:衡量两个点的直线距离,不适合做布尔向量计算,它的值是一个非负数,最大值正无穷,通常计算相似度的结果是[-1,1]或[0,1]之间。
- 余弦相似度
- 度量两个向量之间的夹角,用夹角的余弦值来度量相似的情况
- 两个向量的夹角为0,余弦值为1,夹角为90度,余弦值为0,夹角为180,余弦值为-1
- 余弦相似度在度量文本相似度、用户相似度和物品相似度的时候较为常用
- 预先相速度的特点:与向量长度无关,需要对向量长度归一化,两个向量只要方向一致,无论程度强弱,都可以视为相似
- 余弦相似度
- 皮尔逊相关系数Pearson
- 实际上也是余弦相似度,不过就是对向量做了中心化处理,向量a和b各自减去向量的均值后,再计算余弦相似度
- 皮尔逊相似度计算结果在[-1,1]之间,-1表示负相关,1表示正相关
- 度量两个遍历是不是同增同减,变化趋势是否一致,不适合计算布尔向量
- 杰卡德相似度Jaccard
- 两个集合的交集元素个数在并集中所占的比例,适合用于布尔向量
- 就是交集比上并集
- 如何选择余弦相似度
- 余弦和皮尔逊适合处理用户的一些评分数据,不适合处理boolearn
- 杰卡德适合做boolearn类型的数据
以下有一个简单的小案例,数据集相当于一个用户对物品的购买记录
User-Based CF
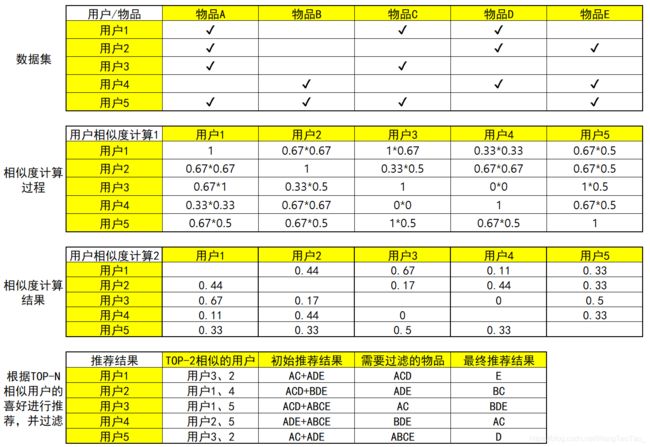
Item-Based CF

代码实现:User_Based CF
# 根据表格构建数据集
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 用户购买记录数据集
datasets = [
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1],
]
import pandas as pd
df = pd.DataFrame(data=datasets,index=users,columns=items)
# 这里我们使用杰卡德相似系数来计算相似度
from sklearn.metrics.pairwise import pairswise_distances
# 计算用户之间的相似度 1 - 杰卡德距离 = 杰卡德相似度
user_similar = 1 - pairwise_distances(df,metric = 'jaccard')
user_similar = pd.DataFrame(data=user_similar,index=users,columns=users)
# 接下来计算TOP-N相似结果 (相似度最接近的前两名用户)
topN_users = {
}
for i in user_similar.index:
_df = user_similar.loc[i].drop(i)
_df_sorted = _df.sort_values(ascending=False)
top2 = list(_df_sorted.index[:2])
topN_users[i] = top2
import numpy as np
results = {
}
for user,sim_users in topN_users.items():
res = set()
for sim_user in sim_users:
res = res.union(set(df.loc[sim_user].replace(0,np.NaN).dropna().index))
# 过滤掉用户已经购买过的物品
res -= set(df.loc[user].replace(0,np.NaN).dropna().index)
results[user] = res
print("最终推荐结果:",results)
Item_Based CF
# 根据表格构建数据集
users = ["User1", "User2", "User3", "User4", "User5"]
items = ["Item A", "Item B", "Item C", "Item D", "Item E"]
# 用户购买记录数据集
datasets = [
[1,0,1,1,0],
[1,0,0,1,1],
[1,0,1,0,0],
[0,1,0,1,1],
[1,1,1,0,1],
]
import pandas as pd
df = pd.DataFrame(data=datasets,index=users,columns=items)
# 计算用户之间的相似度 1 - 杰卡德距离 = 杰卡德相似度
item_similar = df.pairwise_distances(df,matric = 'jaccard')
item_similar = pd.DataFrame(data=item_similar,index=items,columns=items)
# # 接下来计算TOP-N相似结果 (相似度最接近的前两名用户)
topN_items = {
}
for i in item_similar.index:
# 取出每一列数据,并删除自身,然后排序数据
_df = item_similar.loc[i].drop(i)
_df_sorted = _df.sort_values(ascending=False)
top2 = list(_df_sorted.index[:2])
topN_items[i] = top2
results = {
}
for user in df.index:
res = set()
# 取出每一个用户当前已购买的物品列表
for item in df.loc[user].replace(0,np.NaN).dropna().index:
# 根据每个物品找出最相似的TOP-N物品,构建初始推荐结果
res = res.union(topN_items[item])
# 过滤用户已买过的物品
res -= set(df.loc[user].replace(0,np.NaN).dropna().index)
results[user] = res
print("最终推荐结果",results)
4)案例:基于协同过滤的电影推荐
1.User-Based CF 预测电影评分
import numpy as np
import pandas as pd
# 获取数据
dtype = {
'userId':np.int32,'movieId':np.int32,'rating':np.float32}
# 只取前三列数据 用户id 电影id 和 电影对应评分
ratings = pd.read_csv('ratings.csv',dtype=dtype,usecols=range(3))
# 使用透视表,将电影ID转换为列名称,转换成一个User_Movie的评分矩阵
ratings_matrix = ratings.pivot_table(index=['userId'],columns=['movieId'],values='rating')
# 计算用户之间的相似度 corr就是可以直接计算皮尔逊相关系数
user_similar = ratings.matrix.T.corr()
# 预测某一用户对某一个电影的评分
def predict(uid,iid,ratings_matrix,user_similar):
# 1.找出与用户相似的相似用户
# 1.1 先删除自己与自己的相似度
similar_users = user_similar.loc[uid].drop(uid).dropna()
# 1.2 找出正相关的相似用户
similar_users = similar_users.where(similar_users > 0 ).dropna()
# 2.从近邻用户中选出对iid电影有评分的用户
ids = set(ratings_matrix[iid].dropna().index)&set(similar_users.index)
# 2.1 将这些用户从相似用户中提取出来
finally_similar_users = similar_users.loc[list(ids)]
# 3.结合用户与近邻用户的相似度 预测用户对iid电影的评分
num = 0 # 评分预测公式的分子部分
deno = 0 # 评分预测公式的分母部分
for sim_uid,similarity in finally_similar_user.iteritems():
# 计算这个近邻用户对所有电影的评分
sim_user_rated_movies = ratings_matrix.loc[sim_uid].dropna()
# 求出这个用户对iid当前的电影的评分
sim_user_for_item = sim_user_rated_movies[iid]
# 计算分子
num += similarity * sim_user_for_item
deno += similarity
# 计算预测的评分
predict_rating = num / deno
print("预测出用户<%d>对电影<%d>的评分:%0.2f" % (uid,iid,predict_rating))
return round(predct_rating,2)
# 预测某一个用户对所有电影评分
def predict_all(uid,ratings_matrix,user_similar):
# 准备要预测的电影列表
item_ids = ratings_matrix.columns
for iid in item_ids:
try:
rating = predict(uid,iid,ratings_matrix,user_similar)
except Exception as e:
print(e)
else:
yield uid,iid,rating
# 根据评分为指定用户推荐topN个电影
def top_k_result(k):
results = predict_all(1,ratings_matrix,user_similar)
return sorted(results,key=lambda x:x[2],reverse = True)[:k]
result = top_k_result(5)
print(result)