存储系统的实现-探析存储的机制和原理
这一篇主要想写写一些自己对于存储的思考和领悟,因为有些东西自己实践过,所以感触过更加深一些,技术上我还是认为自己实现和看别人的代码在感触上是不同的。
这里假设一个图书馆,假如说书就是要我们要放的数据,会怎么放。最土的办法就是随便往里面丢,然后毫无章法,这样每次找书我们就累死了,因为必须每一本书都要一本书一本书翻过去(有点像DB的全表扫描),如果运气好可能会在比较前面找到,最差情况下就是翻遍整个图书馆最后找到了这本书。所以现实中图书馆的书也不是随便丢了,都是各个书架对应各种类型的书籍,这样才方便查找。具体到我们的数据存储也是这样的,不可能有一条数据就往文件里面放,这样当数据量一大整个查找就非常困难了。
我对于整个存储的实现是非常简单的一种,没有DB中按照各种字段进行查找,只有按照ID进行查找,按照ID进行删除。我实现的初衷也并非要重复制造轮子,而是在实现的过程中更好的理解这些存储的基本原理。
系统架构图
先看一下整个系统的架构图,了解一下整个分层思想。
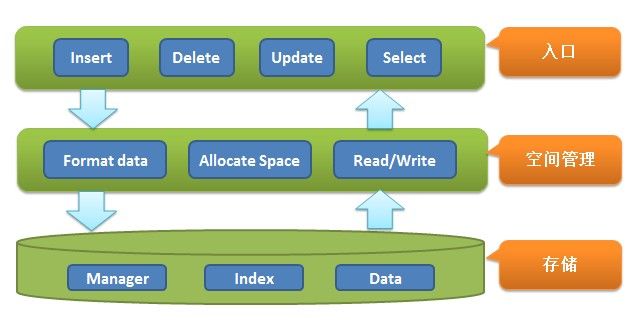
第一层为整个入口,包括插入、更新、查询、删除等入口。核心是对于文件的管理,包括文件的分配、读写文件等等。这里所有对文件的操作都是用
RandomAccessFile这个类去操作。用这个类的好处是可以知道文件具体的偏移。另外具体的存储文件分为
索引文件和
数据文件。也就是对应存储那一层的Index和Data。这里和数据库的文件分配有些类似。索引单列成一个文件主要是为了加快查询速度。一个好处是可以利用索引的有序性然后利用各种查找算法,我这里利用的是“
跳跃表”算法。另外由于索引文件通常比真实的数据文件小很多,查找过程中可以减少多次IO,可以得到性能上的提升。
数据格式
在上面的系统架构图中可以看出第三层的存储分为三个文件,一个是
管理文件(Manager),
索引文件(Index),
数据文件(Data)。
名词解释
管理文件(Manager):理解为一个文件的统一管理者,下面讲文件格式的时候会详细讲。
索引文件(Index):索引文件就比较好理解,用过数据库的大概都知道索引文件这个概念。
数据文件(Data):数据文件就是真实数据的存储块。
管理文件(Manager)
上面在名词解释中大概讲到了Manager这一个文件的职责。如果要讲清楚这个文件职责之前必须要对整个存储空间配置的机制有一些了解。这里先用文字描述一下:假设我要存储一段数据,最简单的方式就是用RandomAccessFile直接往文件里面按行写,每一行就是一条记录,并且每行都需要一个标识,来标识这一行的唯一性,有点像DB里面主键的概念,这样删除的时候就不需要移动整个文件的位移(物理删除就需要移动整个位移),只需要把这一行置为可用。那么回到一个问题:怎么知道当前行是可用还是已经被占用,这里就需要对空间有一个管理。就像买票,如果我买了A座位的票,那么A座位的票就是被使用状态,如果退票(对应我们的删除)那么这个座位还可以出售给其他人。总结一下,Manager其实就是对整个空间的一个管理文件,存储着空间的使用状态。
说了这么多,上一张图来看看这个Manager具体格式:
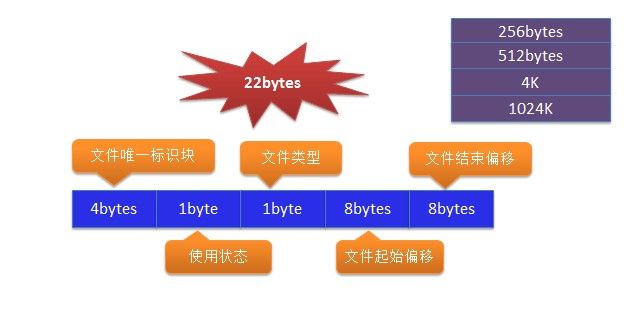
整个文件由5部分组成:
文件唯一标识块、
使用状态、
文件类型、
文件超始偏移、
文件结束偏移。总共是22个字节。这几个字段还是比较好理解,文件类型下面会讲,文件起始偏移和结束偏移其实说白了是一个坐标,告诉你这个位置在哪里,你直接去那儿找就好了。
这里先说一下整个文件的配置机制,是采用定长分配。简单的说就是一个房间开始就会分配成多种大小的小格,就是上图右上角所看到的
256bytes、
512bytes、
4K、
1024K,这样分配的好处是便于管理,避免碎片的产生(为了解决碎片问题会有定期的文件合并)。定额分配就会规避碎片的问题,那么带来的弊端可能导致数据的不连续性。
索引文件(Index,严格来讲是一个主键文件)
索引文件如果用过DB的就应该比较好理解,不理解的可以参考字典的目录,重点可以看一下整个索引文件文件格式:
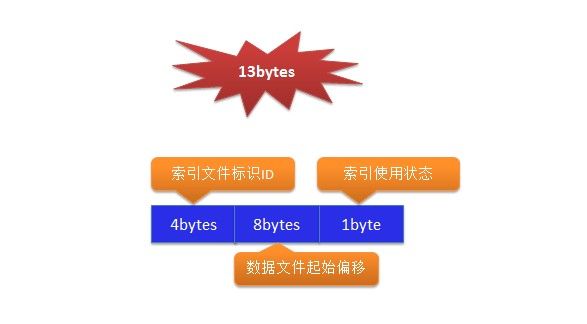
从上图可以看出索引文件的大小是固定的,由
索引文件标识、
数据文件起始偏移、
索引使用状态三部分组成,总共是13bytes。这里稍微解释一下数据文件起始偏移,其实就是一个定位数据具体位置的标志位,一般查找如果走索引的话会先找到具体的索引项,然后根据数据文件起始偏移找到具体的数据位置。这里为什么会有一个索引使用状态,因为索引的分配是不走Manager管理的(理论上也是要走Manager管理),但是这里为了简单。另外我这里的索引严格意义来讲是主键,因为索引文件标识ID只能表示一个int类型。和真实的索引格式有一定的区别。
数据文件
接下来就是最复杂的数据文件存储格式了,先上一张图再进行解释
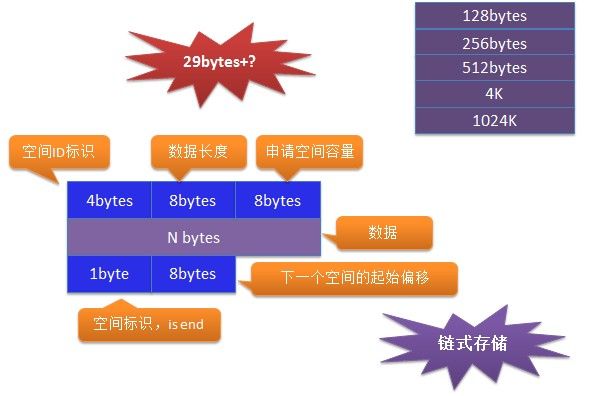
一个数据空间由固定的29bytes+数据长度组成,也就是说申请256bytes容量的空间有29bytes是得不到利用的。就如我上图中所出的,由于每个空间都是定长的,但是不一定每个数据都只申请一个空间,这里举一个简单的例子:300bytes字节的数据会申请一个256bytes空间和一个128bytes的空间,我在这里定为A和B,而在物理上这两个空间极有可能是不连续的。那么我在A找到了一部分数据,然后再去B找到余下的数据,再做一个拼接,一个完整的数据就出来了。那么这里就可以用
链式存储的方式进行,也可以用另外的方式进行,比如说在某个地方存储一个完整数据的所有空间地址。
具体操作数据
上面讲到了一些数据的存储协议,那么接下来就会讲如何
存储数据、
删除数据、
更新数据。
Insert数据
这里先以一张图来看看整个Insert的过程:
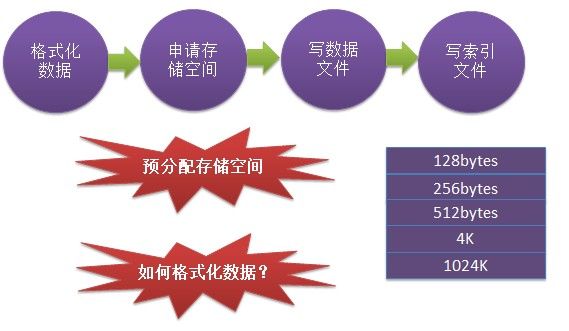
从上面的的流程中可以看出insert大概有四步:
格式化数据:因为一般数据都会有一定的格式,这里就需要定义具体的格式,比如说数据中Table的概念。这样才可以按照约定进行格式化。不过就最后转化的结果而言是一个byte[],但是具体格式化的过程会有一些讲究,比如说一个String,你必须知道这个String的长度,就是对应到byte[]数组的具体哪一段。其他定长类型好一些,比如说int,就是存储4个字节,long就存储8个字节。
申请存储空间:这一步在上面讲到了一些,经过格式化数据后可以知道当前存储数据的大小,那么可以按照这个大小进行分配一些合适的空间。
写数据文件:拿到存储空间,就把byte[]往里面填就好了。
写索引文件:严格意义来讲我这里并非索引而是主键,而且我这里的索引都是固定的int类型,相对来说狭隘了一些。
Delete数据
我这里只能根据ID(索引文件里面的ID)进行删除,采用其他列进行删除的方式目前还是不支持的。
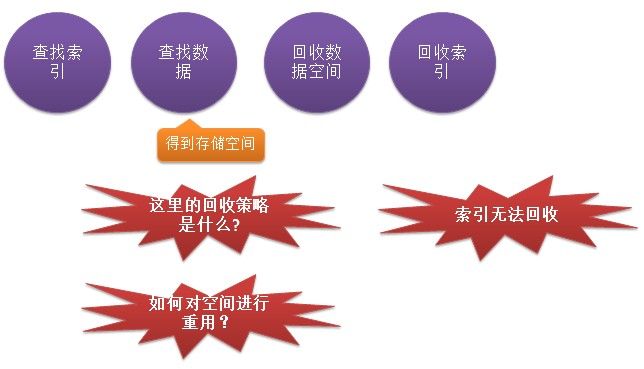
查找索引:其实我这里的查找都简化成了简单的根据ID进行查找,如果根据其他字段进行查找就不是这样了。具体的查找算法会在后面Select数据给出。
查找数据:找到了索引(主键)后就可以根据这个索引找到具体的数据地址,然后把这些空间地址置为可用(具体看一下Manger文件格式)
回收索引:这个时候索引文件的
使用状态就派上用场了。
Update数据
这里我的update策略是会先删除一条记录,然后再插入一条记录进行处理,这样的好处是简单方便,因为本身的更新也涉及到空间的回收一重用。且我在这里格式化数据没有细化到数据库字段的概念,所有无法按字段进行管理。
Select数据
在删除数据里面就会用到根据ID进行查找数据。从索引文件的特性可以知道索引文件是有序的,那么就可以根据这个特性进行一些查找算法,我这里采用的查找算法就是"
跳跃表"算法,这个算法的原理其实就是改变步长 。具体可以参考《跳跃表实现索引检索》,这里就不再做详述。
总结
上面我写的存储应该是最简单的,对于学习存储的原理还是很有帮助的。比如说索引,空间的预分配,为什么要这么做会有一个非常好的认识。因为很多存储,比如说memcached都是采用这种方式进行分配空间。尝试着自己实现也是一种帮助自己理解的手段。