项目pytorch-deeplab-xception为例,测试时怎么保存target、image:target.cpu().numpy()
一般性流程
'''
IPL转换为tensor
_img = Image.open(os.path.join(self.img_dir, path)).convert('RGB')
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
img = torch.from_numpy(img).float()
img = img.cuda()
tensor转换为IPL
image1 = image.data.cpu().numpy()
IPLimage = numpyimg.transpose((1, 2, 0))
save_img = Image.fromarray(IPLimage.astype('uint8'))
'''例子:
for i, sample in enumerate(self.test_loader):
image, target = sample['image'], sample['label']
torch.cuda.synchronize()
start = time.time()
with torch.no_grad():
output = self.model(image)
end = time.time()
times = (end - start) * 1000
print(times, "ms")
torch.cuda.synchronize()
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
pred = np.argmax(pred, axis=1)
self.evaluator.add_batch(target, pred)我想看一下target是否对,通过opencv保存,首先看下opencv的格式:
cv2.resize(src, dsize[, dst[, fx[, fy[, interpolation]]]]) -> dst
fx - 水平轴上的比例因子。fy - 垂直轴上的比例因子。
numpy实现图像部分ROI截取:
for index in inds:
xmin_depth = int((xmin1[index] * expected + crop_start) * scale)
ymin_depth = int((ymin1[index] * expected) * scale)
xmax_depth = int((xmax1[index] * expected + crop_start) * scale)
ymax_depth = int((ymax1[index] * expected) * scale)
depth_temp = depth[ymin_depth:ymax_depth, xmin_depth:xmax_depth].astype(float)首先numpy是[高度h:宽度w]
如果是x1,y1,x2,y2(左上,右下)的任务,应该是img=ori_img[y1:y2, x1:x2]
import cv2
cvimg = cv2.imread("./dog.jpg")
graycvimg = cv2.cvtColor(cvimg, cv2.COLOR_BGR2GRAY)
cv2.imwrite("./dog_gray.jpg", graycvimg)
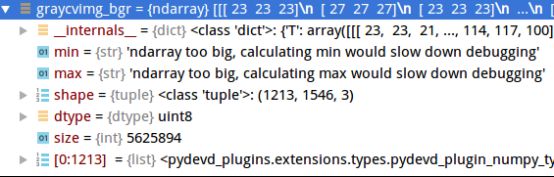
graycvimg_bgr = cv2.cvtColor(graycvimg, cv2.COLOR_GRAY2BGR)
cv2.imwrite("./dog_gray_bgr.jpg", graycvimg_bgr)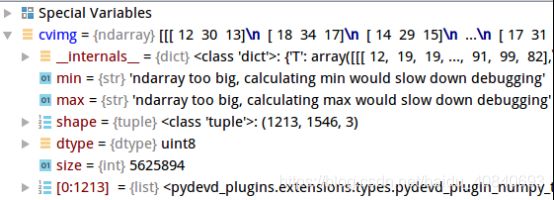

from PIL import Image
import numpy as np
img = Image.open(imgsname).convert('RGB')
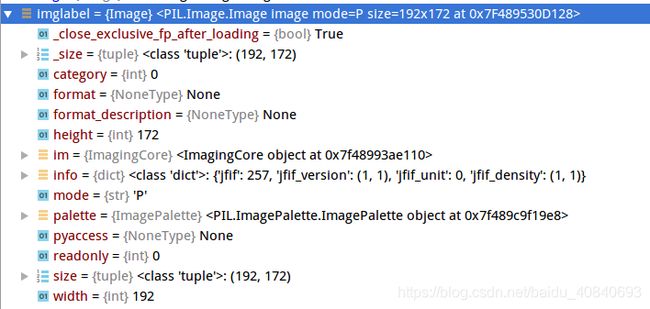
imglabel = Image.open(imgsname).convert('P')
arrayimg = np.array(img).astype(np.float32)
transposeimg = arrayimg.transpose((2, 0, 1))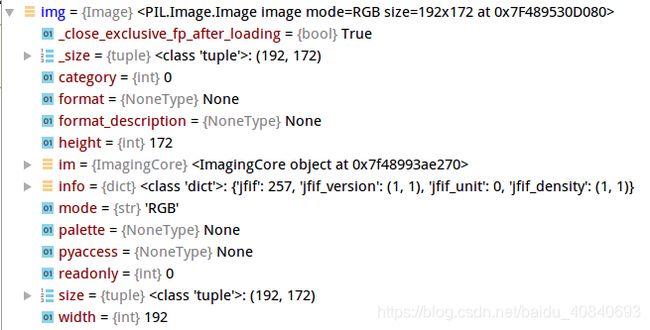


关于PIL和opencv还有一个区别:size的先后,PIL是W,H opencv是H,W,C
imgsname = newpath + namename + '_ccvt_' + str(j) + '.jpg'
img = Image.open(imgsname).convert('RGB')
W, H = img.size
img = np.array(img)
dst, scale_factor = mmcv.imrescale(img, (1333, 800), return_scale=True)
newH, newW, newC = dst.shape # tensor 转换为 numpy
numpyimg = imgarray.numpy()
# numpy 转换为 IPL格式
IPLimage = numpyimg.transpose((1, 2, 0))
'''
IPL转换为tensor
_img = Image.open(os.path.join(self.img_dir, path)).convert('RGB')
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
img = torch.from_numpy(img).float()
img = img.cuda()
tensor转换为IPL
image1 = image.data.cpu().numpy()
IPLimage = numpyimg.transpose((1, 2, 0))
save_img = Image.fromarray(IPLimage.astype('uint8'))
'''参考:
https://blog.csdn.net/m0_37382341/article/details/83548601
numpy.reshape
Numpy将不管是什么形状的数组,先扁平化处理成一个一维的列表,然后按照你重新定义的形状,再把这个列表截断拼成新的形状。 在这个过程中,如果你要处理的是图片矩阵的话,就会完全改变图片信息。
numpy.transpose
numpy.transpose采取轴作为输入,所以你可以改变轴,这对于张量来说很有用,也很方便。比如data.transpose(1,0,2),就表示把1位置的数换到0位置,0位置的换到1位置,2没有变。
由于测试时候使用:
def transform_val(self, sample):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()
])
return composed_transforms(sample)应该把注释改掉:
def transform_val(self, sample):
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.crop_size),
#tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()
])
return composed_transforms(sample)这样方便我们保存Image对比
import cv2
target = target.cpu().numpy()
image = image.data.cpu().numpy()
image1 = image[0, :]
target1 = target[0, :]
#image1.reshape([image1.size[1],image1.size[2],image1.size[3]])
#target1.reshape([image1.size[1],image1.size[2],image1.size[3]])
image1 = image1.transpose(2,1,0)
#target1 = target1.transpose(2,1,0)
image1 = cv2.cvtColor(image1, cv2.COLOR_RGB2BGR)
cv2.imwrite("./image1.jpg",image1)
cv2.imwrite("./target1.jpg", target1)我这里出现一些问题,target方向错误了,debug一下,看看载入时候有没有问题:
def _make_img_gt_point_pair(self, index):
coco = self.coco
img_id = self.ids[index]
img_metadata = coco.loadImgs(img_id)[0]
path = img_metadata['file_name']
_img = Image.open(os.path.join(self.img_dir, path)).convert('RGB')
cocotarget = coco.loadAnns(coco.getAnnIds(imgIds=img_id))
_target = Image.fromarray(self._gen_seg_mask(
cocotarget, img_metadata['height'], img_metadata['width']))
image1 = cv2.cvtColor(np.asarray(_img), cv2.COLOR_RGB2BGR)
target1 = cv2.cvtColor(np.asarray(_target), cv2.COLOR_GRAY2BGR)
cv2.imwrite("./image1.jpg", image1)
cv2.imwrite("./target1.jpg", target1)
return _img, _target
def __getitem__(self, index):
_img, _target = self._make_img_gt_point_pair(index)
sample = {'image': _img, 'label': _target}
if self.split == "train":
return self.transform_tr(sample)
elif self.split == 'val':
return self.transform_val(sample)
elif self.split == 'test':
X = self.transform_val(sample)
aa = X['image']
bb = X['label']
aa = aa.cpu().numpy()
bb = bb.cpu().numpy()
aa = aa.transpose(2, 1, 0)
image1 = cv2.cvtColor(aa, cv2.COLOR_RGB2BGR)
target1 = cv2.cvtColor(bb, cv2.COLOR_GRAY2BGR)
cv2.imwrite("./image2.jpg", image1)
cv2.imwrite("./target2.jpg", target1)
return X
原图resize后方向变了,果然。。。。。。。
原图:


因为项目中使用了一个torch函数进行预处理:
pytorch的transforms.py
class Compose(object):
"""Composes several transforms together.
Args:
transforms (list of ``Transform`` objects): list of transforms to compose.
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])
"""
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
for t in self.transforms:
img = t(img)
return img首先
class FixScaleCrop(object):
def __init__(self, crop_size):
self.crop_size = crop_size
def __call__(self, sample):
img = sample['image']
mask = sample['label']
w, h = img.size
if w > h:
oh = self.crop_size
ow = int(1.0 * w * oh / h)
else:
ow = self.crop_size
oh = int(1.0 * h * ow / w)
img = img.resize((ow, oh), Image.BILINEAR)
mask = mask.resize((ow, oh), Image.NEAREST)
# center crop
w, h = img.size
x1 = int(round((w - self.crop_size) / 2.))
y1 = int(round((h - self.crop_size) / 2.))
img = img.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
mask = mask.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
return {'image': img,
'label': mask}class FixScaleCrop(object):
def __init__(self, crop_size):
self.crop_size = crop_size
def __call__(self, sample):
img = sample['image']
mask = sample['label']
w, h = img.size
if w > h:
oh = self.crop_size
ow = int(1.0 * w * oh / h)
else:
ow = self.crop_size
oh = int(1.0 * h * ow / w)
img = img.resize((ow, oh), Image.BILINEAR)
mask = mask.resize((ow, oh), Image.NEAREST)
# center crop
w, h = img.size
x1 = int(round((w - self.crop_size) / 2.))
y1 = int(round((h - self.crop_size) / 2.))
img = img.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
mask = mask.crop((x1, y1, x1 + self.crop_size, y1 + self.crop_size))
import cv2
image1 = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
target1 = cv2.cvtColor(np.asarray(mask), cv2.COLOR_GRAY2BGR)
cv2.imwrite("./image3.jpg", image1)
cv2.imwrite("./target3.jpg", target1)
return {'image': img,
'label': mask}
程序在这里还是没问题的,结果接下来会进入:
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
img = sample['image']
mask = sample['label']
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
mask = np.array(mask).astype(np.float32)
img = torch.from_numpy(img).float()
mask = torch.from_numpy(mask).float()
return {'image': img,
'label': mask}class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
img = sample['image']
mask = sample['label']
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
mask = np.array(mask).astype(np.float32)
img = torch.from_numpy(img).float()
mask = torch.from_numpy(mask).float()
import cv2
image1=img.cpu().numpy()
target1=mask.cpu().numpy()
image1 = image1.transpose(2, 1, 0)
image1 = cv2.cvtColor(image1, cv2.COLOR_RGB2BGR)
target1 = cv2.cvtColor(target1, cv2.COLOR_GRAY2BGR)
cv2.imwrite("./image4.jpg", image1)
cv2.imwrite("./target4.jpg", target1)
return {'image': img,
'label': mask}
这里出错了,方向不对了
如果将代码改为;
img = np.array(img).astype(np.float32).transpose((2, 1, 0))方向就都对了,那么作者原本为什么那样写??????
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
到底有什么用,
class ToTensor(object):
"""Convert ndarrays in sample to Tensors."""
def __call__(self, sample):
# swap color axis because
# numpy image: H x W x C
# torch image: C X H X W
img = sample['image']
mask = sample['label']
import cv2
image1 = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
target1 = cv2.cvtColor(np.asarray(mask), cv2.COLOR_GRAY2BGR)
cv2.imwrite("./image5.jpg", image1)
cv2.imwrite("./target5.jpg", target1)
xxx = np.array(img).astype(np.float32)
import copy
xxx1 = copy.deepcopy(xxx)
xxx2 = copy.deepcopy(xxx)
img1 = np.array(xxx1).astype(np.float32).transpose((2, 1, 0))
img2 = np.array(xxx2).astype(np.float32).transpose((2, 0, 1))
img = np.array(img).astype(np.float32).transpose((2, 1, 0))
mask = np.array(mask).astype(np.float32)
img = torch.from_numpy(img).float()
mask = torch.from_numpy(mask).float()

513*513*3---3* 513*513
.transpose((2, 1, 0)) 
513*513*3---3* 513*513
.transpose((2, 0, 1))
其实实验做到这里我已经明白是我错了,
原本是
513*513*3
我们通过.transpose((2, 0, 1)),正常变换,我错在test显示的时候:
import cv2
target = target.cpu().numpy()
image = image.data.cpu().numpy()
image1 = image[0, :]
target1 = target[0, :]
#image1.reshape([image1.size[1],image1.size[2],image1.size[3]])
#target1.reshape([image1.size[1],image1.size[2],image1.size[3]])
image1 = image1.transpose(1,2,0)
image1 = cv2.cvtColor(image1, cv2.COLOR_RGB2BGR)
cv2.imwrite("./image1.jpg",image1)
cv2.imwrite("./target1.jpg", target1)这里应该是
image1 = image1.transpose(1,2,0)
因为原本
for i, sample in enumerate(self.test_loader):
image, target = sample['image'], sample['label']image为:torch.Size([1, 3, 513, 513])
target为:
所以应该使用image1 = image1.transpose(1,2,0)
这下就对了
现在还有一个问题摆在面前,
我做测试时候,COCO数据集格式,自己的数据集,
图片有153张,但是最后输出只有25张pred,
找原因:
pytorch-deeplab-xception/dataloaders/datasets/coco.py
在处理coco数据之前,会生成一个test_ids_2017.pth
id对应文件,新ID与旧ID相对应,
用于知道哪些ID被保留下来,用于接下来的测试
if os.path.exists(ids_file):
self.ids = torch.load(ids_file)
else:
ids = list(self.coco.imgs.keys())
self.ids = self._preprocess(ids, ids_file, self.split)
self.args = args判断条件在函数self._preprocess(ids, ids_file, self.split)
def _preprocess(self, ids, ids_file, split):
print("Preprocessing mask, this will take a while. " + \
"But don't worry, it only run once for each split.")
tbar = trange(len(ids))
new_ids = []
for i in tbar:
img_id = ids[i]
cocotarget = self.coco.loadAnns(self.coco.getAnnIds(imgIds=img_id))
img_metadata = self.coco.loadImgs(img_id)[0]
savemaskname=img_metadata['file_name']
image = ids_file.split("annotations")[0]+'images/'+split+str(self.year) + '/' +savemaskname
oriimg = cv2.imread(image)
h,w,c = oriimg.shape
mask = self._gen_seg_mask(cocotarget, h,
w)
cv2.imwrite('/home/spple/paddle/DeepGlint/deepglint-adv/pytorch-deeplab-xception/mask/'+split+'/'+savemaskname, mask)
# more than 1k pixels
if (mask > 0).sum() > 1000:
new_ids.append(img_id)
tbar.set_description('Doing: {}/{}, got {} qualified images'. \
format(i, len(ids), len(new_ids)))
print('Found number of qualified images: ', len(new_ids))
torch.save(new_ids, ids_file)
return new_ids通过函数def _gen_seg_mask(self, target, h, w): 获取mask
def _gen_seg_mask(self, target, h, w):
mask = np.zeros((h, w), dtype=np.uint8)
coco_mask = self.coco_mask
for instance in target:
rle = coco_mask.frPyObjects(instance['segmentation'], h, w)
m = coco_mask.decode(rle)
cat = instance['category_id']
if cat in self.CAT_LIST:
c = self.CAT_LIST.index(cat)
else:
continue
if len(m.shape) < 3:
mask[:, :] += (mask == 0) * (m * c)
else:
mask[:, :] += (mask == 0) * (((np.sum(m, axis=2)) > 0) * c).astype(np.uint8)
return mask但是这里有个问题,判断依据是mask分割像素点必须是1000以上,但是对于小图像,可能达不到,这里,我们要修改
if (mask > 0).sum() > 1000:
new_ids.append(img_id)修改为:
if (mask > 0).sum() > 50:
new_ids.append(img_id)还有之前的函数只是简单的保存是参考:
https://github.com/jfzhang95/pytorch-deeplab-xception/issues/122
import argparse
import os
import numpy as np
import tqdm
import torch
from PIL import Image
from dataloaders import make_data_loader
from modeling.deeplab import *
from dataloaders.utils import get_pascal_labels
from utils.metrics import Evaluator
class Tester(object):
def __init__(self, args):
if not os.path.isfile(args.model):
raise RuntimeError("no checkpoint found at '{}'".fromat(args.model))
self.args = args
self.color_map = get_pascal_labels()
self.test_loader, self.ids, self.nclass = make_data_loader(args)
#Define model
model = DeepLab(num_classes=self.nclass,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=False,
freeze_bn=False)
self.model = model
device = torch.device('cpu')
checkpoint = torch.load(args.model, map_location=device)
self.model.load_state_dict(checkpoint['state_dict'])
self.evaluator = Evaluator(self.nclass)
def save_image(self, array, id, op):
text = 'gt'
if op == 0:
text = 'pred'
file_name = str(id)+'_'+text+'.png'
r = array.copy()
g = array.copy()
b = array.copy()
for i in range(self.nclass):
r[array == i] = self.color_map[i][0]
g[array == i] = self.color_map[i][1]
b[array == i] = self.color_map[i][2]
rgb = np.dstack((r, g, b))
save_img = Image.fromarray(rgb.astype('uint8'))
save_img.save(self.args.save_path+os.sep+file_name)
def test(self):
self.model.eval()
self.evaluator.reset()
# tbar = tqdm(self.test_loader, desc='\r')
for i, sample in enumerate(self.test_loader):
image, target = sample['image'], sample['label']
with torch.no_grad():
output = self.model(image)
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
pred = np.argmax(pred, axis=1)
self.save_image(pred[0], self.ids[i], 0)
self.save_image(target[0], self.ids[i], 1)
self.evaluator.add_batch(target, pred)
Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
print('Acc:{}, Acc_class:{}'.format(Acc, Acc_class))
def main():
parser = argparse.ArgumentParser(description='Pytorch DeeplabV3Plus Test your data')
parser.add_argument('--test', action='store_true', default=True,
help='test your data')
parser.add_argument('--dataset', default='pascal',
help='datset format')
parser.add_argument('--backbone', default='xception',
help='what is your network backbone')
parser.add_argument('--out_stride', type=int, default=16,
help='output stride')
parser.add_argument('--crop_size', type=int, default=513,
help='image size')
parser.add_argument('--model', type=str, default='',
help='load your model')
parser.add_argument('--save_path', type=str, default='',
help='save your prediction data')
args = parser.parse_args()
if args.test:
tester = Tester(args)
tester.test()
if __name__ == "__main__":
main()这里保存完后是:
def save_image(self, array, id, op, oriimg=None, image111=None):
import cv2
text = 'gt'
if op == 0:
text = 'pred'
file_name = str(id)+'_'+text+'.png'
drow_ori_name = str(id)+'_'+'vis'+'.png'
#513*513
r = array.copy()
g = array.copy()
b = array.copy()
if oriimg is True:
image111 = image111.data.cpu().numpy()
image111 = image111[0, :]
image111 = image111.transpose(1,2,0)
oneimg = image111
for i in range(self.nclass):
r[array == i] = self.color_map[i][2]
g[array == i] = self.color_map[i][1]
b[array == i] = self.color_map[i][0]
rgb = np.dstack((r, g, b))
hh,ww,_ = rgb.shape
if oriimg is True:
for i in range(self.nclass):
if i != 0:
index = np.argwhere(array == i)
for key in index:
oneimg[key[0]][key[1]][0] = self.color_map[i][0]
oneimg[key[0]][key[1]][1] = self.color_map[i][1]
oneimg[key[0]][key[1]][2] = self.color_map[i][2]
oneimg = cv2.cvtColor(oneimg, cv2.COLOR_RGB2BGR)
cv2.imwrite(self.args.save_path + os.sep + drow_ori_name, oneimg)
这样完全覆盖了,我们并不能看到真实样貌,应该参考mask_rcnn,透明效果:

其实就是将原始图像和预测类的颜色,不同比例结合,生成可视化图像:
oneimg[key[0]][key[1]][0] = oneimg[key[0]][key[1]][0] * 0.5 + self.color_map[i][0] * 0.5
oneimg[key[0]][key[1]][1] = oneimg[key[0]][key[1]][1] * 0.5 + self.color_map[i][1] * 0.5
oneimg[key[0]][key[1]][2] = oneimg[key[0]][key[1]][2] * 0.5 + self.color_map[i][2] * 0.5这里还有一个问题
我们进行测试时候显示:
Acc:0.9829744103317358, Acc_class:0.7640047637800897, mIoU:0.7015250613321066
/home/spple/pytorch-deeplab-xception/utils/metrics.py:14: RuntimeWarning: invalid value encountered in true_divide
Acc = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
/home/spple/pytorch-deeplab-xception/utils/metrics.py:24: RuntimeWarning: invalid value encountered in true_divide
np.diag(self.confusion_matrix))原来是因为数组分母有为0的
比如:
def Pixel_Accuracy_Class(self):
a = np.diag(self.confusion_matrix)
b = self.confusion_matrix.sum(axis=1)
#Acc = np.diag(self.confusion_matrix) / self.confusion_matrix.sum(axis=1)
Acc = a/b
Acc = np.nanmean(Acc)
return Acca:
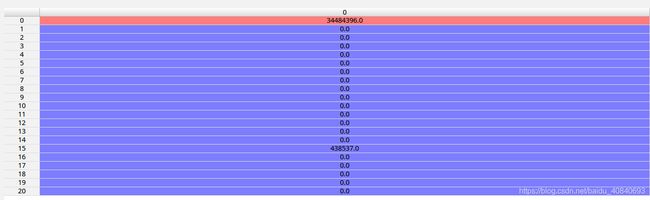
b:

Acc:
![]()
Acc = np.nanmean(Acc):0.7640047637800897=(0.993579+0.534430)/2
顺便做了一个实验:
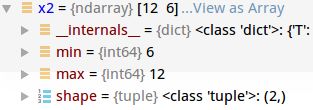
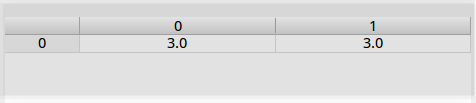
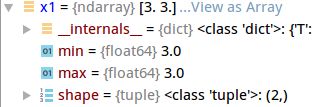
import numpy as np
a = np.array([[12],[6]])
b = np.array([3,3])
Acc_1= a/b
c = np.array([[12,1],[1,6]])
x2 = np.diag(c)
Acc_2= x2/b
x1 = np.zeros((2,)*1)
x1[0]=3
x1[1]=3向量相除,如果最后只想得到向量,分子分母shape应该 是: (2,)
a


b
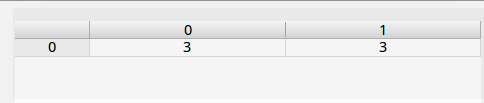

Acc_1

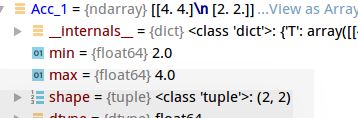
c

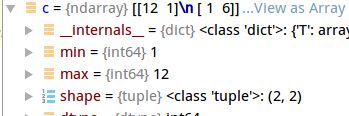
x2

Acc_2


x1
test.py
import argparse
import os
import numpy as np
import tqdm
import torch
import time
#https://github.com/jfzhang95/pytorch-deeplab-xception/issues/122
from PIL import Image
from dataloaders import make_data_loader
from modeling.deeplab import *
from dataloaders.utils import get_pascal_labels
from utils.metrics import Evaluator
import cv2
class Tester(object):
def __init__(self, args):
if not os.path.isfile(args.model):
raise RuntimeError("no checkpoint found at '{}'".fromat(args.model))
self.args = args
self.color_map = get_pascal_labels()
self.test_loader, self.nclass= make_data_loader(args)
#Define model
model = DeepLab(num_classes=self.nclass,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=False,
freeze_bn=False)
self.model = model
device = torch.device('cpu')
checkpoint = torch.load(args.model, map_location=device)
self.model.load_state_dict(checkpoint['state_dict'])
self.evaluator = Evaluator(self.nclass)
#--dataset pascal --backbone resnet --out_stride 16 --crop_size 513 --model /home/spple/paddle/DeepGlint/deepglint-adv/pytorch-deeplab-xception/checkpoint-gray/model_best.pth.tar --save_path /home/spple/paddle/DeepGlint/deepglint-adv/pytorch-deeplab-xception/prediction_gray
# --dataset pascal --backbone resnet --out_stride 16 --crop_size 513 --model /home/spple/paddle/DeepGlint/deepglint-adv/pytorch-deeplab-xception/checkpoint/checkpoint.pth.tar --save_path /home/spple/paddle/DeepGlint/deepglint-adv/pytorch-deeplab-xception/prediction
def save_image(self, array, id, op, oriimg=None, image111=None):
import cv2
text = 'gt'
if op == 0:
text = 'pred'
file_name = str(id)+'_'+text+'.png'
drow_ori_name = str(id)+'_'+'vis'+'.png'
#513*513
r = array.copy()
g = array.copy()
b = array.copy()
if oriimg is True:
oneimgpath = str(id) + '.jpg'
from mypath import Path
#JPEGImages_gray
image111 = image111.data.cpu().numpy()
image111 = image111[0, :]
image111 = image111.transpose(1,2,0)
oneimg = image111
for i in range(self.nclass):
r[array == i] = self.color_map[i][2]
g[array == i] = self.color_map[i][1]
b[array == i] = self.color_map[i][0]
#513*513*3
rgb = np.dstack((r, g, b))
hh,ww,_ = rgb.shape
#if oriimg is True:
#oneimg = oneimg.resize((hh, ww), Image.ANTIALIAS)
# 原图
#image1 = cv2.cvtColor(oneimg, cv2.COLOR_RGB2BGR)
#oneimg.save(self.args.save_path + os.sep + ori_name, quality=100)
#cv2.imwrite(self.args.save_path + os.sep + ori_name, image1)
#----gt ---- pred
cv2.imwrite(self.args.save_path+os.sep+file_name, rgb)
#save_img = Image.fromarray(rgb.astype('uint8'))
# pred
#save_img.save(self.args.save_path+os.sep+file_name, quality=100)
#oneimg = oneimg.transpose(2, 0, 1)
if oriimg is True:
#oneimg = np.array(oneimg)
for i in range(self.nclass):
if i != 0:
index = np.argwhere(array == i)
for key in index:
oneimg[key[0]][key[1]][0] = oneimg[key[0]][key[1]][0] * 0.5 + self.color_map[i][0] * 0.5
oneimg[key[0]][key[1]][1] = oneimg[key[0]][key[1]][1] * 0.5 + self.color_map[i][1] * 0.5
oneimg[key[0]][key[1]][2] = oneimg[key[0]][key[1]][2] * 0.5 + self.color_map[i][2] * 0.5
#img_show[mask] = img_show[mask] * 0.5 + color_mask * 0.5
#oneimg = Image.fromarray(oneimg.astype('uint8'))
#可视化
oneimg = cv2.cvtColor(oneimg, cv2.COLOR_RGB2BGR)
#oneimg.save(self.args.save_path + os.sep + ori_name, quality=100)
cv2.imwrite(self.args.save_path + os.sep + drow_ori_name, oneimg)
#oneimg.save(self.args.save_path+os.sep+drow_ori_name, quality=100)
def test(self):
self.model.eval()
self.evaluator.reset()
# tbar = tqdm(self.test_loader, desc='\r')
num = len(self.test_loader)
for i, sample in enumerate(self.test_loader):
image, target = sample['image'], sample['label']
print(i,"/",num)
torch.cuda.synchronize()
start = time.time()
with torch.no_grad():
output = self.model(image)
end = time.time()
times = (end - start) * 1000
print(times, "ms")
torch.cuda.synchronize()
pred = output.data.cpu().numpy()
target = target.cpu().numpy()
image1 = image.data.cpu().numpy()
# #target1 = target.cpu().numpy()
image1 = image1[0, :]
target1 = target[0, :]
# #image1.reshape([image1.size[1],image1.size[2],image1.size[3]])
# #target1.reshape([image1.size[1],image1.size[2],image1.size[3]])
image1 = image1.transpose(1,2,0)
# #target1 = target1.transpose(2,1,0)
# import cv2
# image1 = cv2.cvtColor(image1, cv2.COLOR_RGB2BGR)
# import cv2
# cv2.imwrite("./image1.jpg",image1)
cv2.imwrite("./target111.jpg", target1)
pred = np.argmax(pred, axis=1)
self.save_image(pred[0], i, 0, True, sample['ori_image'])
self.save_image(target[0], i, 1, None, sample['ori_image'])
self.evaluator.add_batch(target, pred)
Acc = self.evaluator.Pixel_Accuracy()
Acc_class = self.evaluator.Pixel_Accuracy_Class()
mIoU = self.evaluator.Mean_Intersection_over_Union()
print('Acc:{}, Acc_class:{}, mIoU:{}'.format(Acc, Acc_class, mIoU))
def main():
# import cv2
# cvimg = cv2.imread("./dog.jpg")
# graycvimg = cv2.cvtColor(cvimg, cv2.COLOR_BGR2GRAY)
# cv2.imwrite("./dog_gray.jpg", graycvimg)
# graycvimg_bgr = cv2.cvtColor(graycvimg, cv2.COLOR_GRAY2BGR)
# cv2.imwrite("./dog_gray_bgr.jpg", graycvimg_bgr)
parser = argparse.ArgumentParser(description='Pytorch DeeplabV3Plus Test your data')
parser.add_argument('--test', action='store_true', default=True,
help='test your data')
parser.add_argument('--dataset', default='pascal',
help='datset format')
parser.add_argument('--backbone', default='xception',
help='what is your network backbone')
parser.add_argument('--out_stride', type=int, default=16,
help='output stride')
parser.add_argument('--crop_size', type=int, default=513,
help='image size')
parser.add_argument('--model', type=str, default='/Users/jaeminjung/develop/aidentify/MoE_ws/result/cheonan_24/model_best.pth.tar',
help='load your model')
parser.add_argument('--save_path', type=str, default='/Users/jaeminjung/develop/aidentify/MoE_ws/result/20191001_img',
help='save your prediction data')
args = parser.parse_args()
if args.test:
tester = Tester(args)
tester.test()
if __name__ == "__main__":
main()我们不测试val,直接生成test的预测图:
import argparse
import os
import numpy as np
import tqdm
import torch
from PIL import Image
from dataloaders import make_data_loader
from modeling.deeplab import *
from dataloaders.utils import get_pascal_labels
from utils.metrics import Evaluator
class Tester(object):
def __init__(self, args):
if not os.path.isfile(args.model):
raise RuntimeError("no checkpoint found at '{}'".fromat(args.model))
self.args = args
self.color_map = get_pascal_labels()
self.nclass = 2
# Define model
model = DeepLab(num_classes=self.nclass,
backbone=args.backbone,
output_stride=args.out_stride,
sync_bn=False,
freeze_bn=False)
self.model = model
device = torch.device('cpu')
checkpoint = torch.load(args.model, map_location=device)
self.model.load_state_dict(checkpoint['state_dict'])
def save_image(self, imgarray, array, id, op):
text = 'gt'
if op == 0:
text = 'pred'
file_name = str(id) + '_' + text + '.png'
# r = array.copy()
# g = array.copy()
# b = array.copy()
# for i in range(self.nclass):
# r[array == i] = self.color_map[i][0]
# g[array == i] = self.color_map[i][1]
# b[array == i] = self.color_map[i][2]
# rgb = np.dstack((r, g, b))
#tensor 转换为 numpy
numpyimg = imgarray.numpy()
#numpy 转换为 IPL格式
IPLimage = numpyimg.transpose((1, 2, 0))
'''
IPL转换为tensor
_img = Image.open(os.path.join(self.img_dir, path)).convert('RGB')
img = np.array(img).astype(np.float32).transpose((2, 0, 1))
img = torch.from_numpy(img).float()
img = img.cuda()
tensor转换为IPL
image1 = image.data.cpu().numpy()
IPLimage = numpyimg.transpose((1, 2, 0))
save_img = Image.fromarray(IPLimage.astype('uint8'))
'''
for i in range(self.nclass):
if i != 0:
index = np.argwhere(array == i)
for key in index:
IPLimage[key[0]][key[1]][0] = IPLimage[key[0]][key[1]][0] * 0.5 + self.color_map[i][0] * 0.5
IPLimage[key[0]][key[1]][1] = IPLimage[key[0]][key[1]][1] * 0.5 + self.color_map[i][1] * 0.5
IPLimage[key[0]][key[1]][2] = IPLimage[key[0]][key[1]][2] * 0.5 + self.color_map[i][2] * 0.5
save_img = Image.fromarray(IPLimage.astype('uint8'))
save_img.save(self.args.save_path + os.sep + file_name)
def transform_val(self, sample):
from torchvision import transforms
from dataloaders import custom_transforms as tr
composed_transforms = transforms.Compose([
tr.FixScaleCrop(crop_size=self.args.crop_size),
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()
])
return composed_transforms(sample)
def test(self):
self.model.eval()
from PIL import Image
file = open('./test_marker.txt', 'r')
newpath = "/media/spple/新加卷/Dataset/data/marker_data/marker20191021/all/"
text_lines = file.readlines()
for i in range(len(text_lines)):
namename = text_lines[i].replace("\n", "")
namename = namename.replace("\t", "")
imgsname = newpath + namename
img = Image.open(imgsname).convert('RGB')
imglabel = Image.open(imgsname).convert('P')
#arrayimg = np.array(img).astype(np.float32)
#transposeimg = arrayimg.transpose((2, 0, 1))
sample = {'image': img, 'label': imglabel, 'ori_image': img, 'path': None}
imgdist = self.transform_val(sample)
image = imgdist['image']
ori_image = imgdist['ori_image']
image = image.unsqueeze(0)
with torch.no_grad():
output = self.model(image)
pred = output.data.cpu().numpy()
pred = np.argmax(pred, axis=1)
self.save_image(ori_image, pred[0], namename.split(".jpg")[0], 0)
def main():
parser = argparse.ArgumentParser(description='Pytorch DeeplabV3Plus Test your data')
parser.add_argument('--test', action='store_true', default=True,
help='test your data')
parser.add_argument('--dataset', default='pascal',
help='datset format')
parser.add_argument('--backbone', default='xception',
help='what is your network backbone')
parser.add_argument('--out_stride', type=int, default=16,
help='output stride')
parser.add_argument('--crop_size', type=int, default=513,
help='image size')
parser.add_argument('--model', type=str, default='',
help='load your model')
parser.add_argument('--save_path', type=str, default='',
help='save your prediction data')
args = parser.parse_args()
if args.test:
tester = Tester(args)
tester.test()
if __name__ == "__main__":
main()