最没灵魂的爬虫——Selenium 游戏信息的爬取与分析
最没有灵魂的爬虫——Selenium 游戏信息爬取与分析
- 准备工作
- IDE选取
- selenium安装
- ChromeDriver安装与配置
- 还需要用到的其他python库
- 数据爬取
- 杉果游戏的数据获取
- 中国游戏产业网——游戏版号信息爬取
- 部分数据分析
- Excel图表
- Python数据图表
- 杂谈与感想
准备工作
IDE选取
python本身自带的IDLE,也可以用一些编辑器,我个人使用的是pycharm,也可以使用一些其他的IDE。IDE的安装与配置很多,就不在这儿细说了。
selenium安装
Python装selenium很简单,直接在控制台执行pip就可以
pip install selenium
pycharm上的安装selenium
1.找到file,settings

2.找到对应的位置,点击绿色的“+”添加

3.在搜索栏输入selenium,就能找到对应的包

4.左下角安装,等待完成就好

ChromeDriver安装与配置
我在使用selenium的时候安装的Chromedriver,所以暂时只讲解Chromedriver的安装和配置
关于chromedriver与chrome版本映射表
转载:selenium之 chromedriver与chrome版本映射表
该文章下还有Chromedriver下载地址,我就不在这个页面贴上了(并不是因为懒 )
chromedriver的安装配置
下载好的chromedriver放到
C:\Program Files (x86)\Google\Chrome\Application
这个根据具体情况,放到你谷歌浏览器的Application文件夹中即可
还需要用到的其他python库
-
xlrd、xlwt
xlrd是读取Excel文件的库,xlwt是写入Excel文件的库,用Excel文件读取是为了数据分析对比(Excel的功能还是很强的)。当然也可以使用数据库来储存想要的信息 -
re
正则表达式 -
matplotlib
用python来画图(高逼格) -
collections
当前只会用到Counter,数据统计
数据爬取
接下来就是正式环节了,怎样用selenium从相应的网页中获取数据?
杉果游戏的数据获取
目标网址:https://www.sonkwo.com/store/search
先讲最开始的设置,url_base是请求的第一页,sortList和orderList是对网页的解析,当你点击该网页的这些栏时:
![]()
网页的链接会发生改变:
![]()
我们在请求数据的时候,就是通过改变网页地址栏中“?”后面所请求的数据,来获得不同的结果。
opt是对webdriver的设置,这里是设置webdriver无窗口,你可以注释opt.set_headless(),看看不同的效果。
allGameInfo就是我们python爬取数据后,数据暂时储存的位置,之后再写入excel表格中。
from selenium import webdriver
import xlwt
import re
#这是目标网址的第一页
url_base = "https://www.sonkwo.com/store/search?" \
"sort=wishes_count&order=desc&page=1"
url = 'https://www.sonkwo.com/store/search?'
sortList = ['released_at','score','wishes_count','price']
orderList = ['desc','asc']
page = ""
opt = webdriver.ChromeOptions()
opt.set_headless()
allGameInfo = []
#设置excel的表
f = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = f.add_sheet('gameInfo', cell_overwrite_ok=True)
这两个函数是写入excel表格中的
#写Excel的表头
def writeExcelTitle():
row0 = ['游戏中文名字','游戏英文名','游戏类型','开发商','发行商','发售日期','游戏语言','售价']
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
#重allGame中获取数据并写入Excel表格中
def writeExcel():
for i in range(1, len(allGameInfo)):
for j in range(0, len(allGameInfo[i])):
sheet.write(i, j, allGameInfo[i][j])
f.save(r'gameInfoofSonkwo_demo02.xls')
这是一个网页元素判断,如果当前元素不存在,则返回false,虽然每一页大同小异,但还是有一些细微的差距,有些class或者id属性名的标签栏在某个页面是不存在的。
def isElementExisted(element, css):
flag = False
try:
element.find_element_by_css_selector(css)
flag = True
except:
flag = False
return flag
将数据保存到allGame中,driver有很多元素定位的方法
转载:[python爬虫] Selenium常见元素定位方法和操作的学习介绍
有些找不到的方法可以百度一下(又开始懒了 )
def fillGameInfo(driver):
singleInfo = []
#中文名
if(isElementExisted(driver, '.typical-name-1')):
singleInfo.append(driver.find_element_by_class_name('typical-name-1').text)
else:
singleInfo.append('')
#英文名
if(isElementExisted(driver, '.typical-name-2')):
singleInfo.append(driver.find_element_by_class_name('typical-name-2').text)
else:
singleInfo.append('')
#游戏类型
if(isElementExisted(driver, '.tag-list')):
singleInfo.append(driver.find_element_by_class_name('tag-list').text)
else:
singleInfo.append('')
#开发商信息
if(isElementExisted(driver, '.item-info.publish-name')):
singleInfo.append(driver.find_element_by_css_selector('.item-info.publish-name')
.find_element_by_class_name('item-content').text)
else:
singleInfo.append("")
#发行商信息
if(isElementExisted(driver,'.item-info.distributor-name')):
singleInfo.append(driver.find_element_by_css_selector('.item-info.distributor-name')
.find_element_by_class_name('item-content').text)
else:
singleInfo.append("")
#发行时间
if(isElementExisted(driver, '.item-info.publish-date')):
singleInfo.append(driver.find_element_by_css_selector('.item-info.publish-date')
.find_element_by_class_name('item-content').text)
else:
singleInfo.append('')
#语言
if(isElementExisted(driver,'.item-info.game-language')):
singleInfo.append(driver.find_element_by_css_selector('.item-info.game-language')
.find_element_by_class_name('item-content').text)
else:
singleInfo.append('')
#当前售价
if(isElementExisted(driver,'.sale-info')):
element = driver.find_elements_by_class_name('sale-info')[0]
singleInfo.append(element.find_element_by_css_selector('.sale-price').text)
else:
singleInfo.append('')
# print(singleInfo)
allGameInfo.append(singleInfo)
最后的主函数!一个重点是webdriver的启动,就是driver = webdriver.Chrome(),有几点细节我用注释的方式写在下面代码块中
def main():
count = 0
#opt为设置无窗口
driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(30)
driver.get(url_base)
#获取所有页面
totalPage = int(re.findall('\d+',driver.find_element_by_class_name('total-page').text)[0])
print("总页数:" + str(totalPage))
#每页循环
for j in range(totalPage):
#关于这个count,可能是因为我自己浏览器爬取的时候出的一些小问题
#在用selenium爬取杉果的时候,当爬取到第9页的似乎就会卡住
#所以便简单设置一下,每爬取8页,就将当前driver退出,重新加载一个新的driver继续爬取
if count >= 8:
driver.quit()
driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(30)
count = 0
#页面请求
url_each = url+'sort='+sortList[2]+'&order='+orderList[0]+'&page='+str(j+1)
driver.get(url_each)
es = driver.find_elements_by_class_name("listed-game-img")
#进入当前页面中每一个可以点击的游戏链接,获取信息就是上面的fillGameInfo方法
for i in range(len(es)):
es[i].click()
fillGameInfo(driver)
driver.back()
es = driver.find_elements_by_class_name("listed-game-img")
count = count + 1
#一个基本啥作用的print,只是为了方便你看一下爬取到第几页了而已
print("第"+str(j+1)+"页" + ':' + str(count))
writeExcelTitle()
writeExcel()
driver.quit()
main()
以上就是我爬取杉果的代码了(懒得啰里啰嗦,直接贴全部,不能保证你能运行,反正我能运行就行,嘿嘿 )
中国游戏产业网——游戏版号信息爬取
目标网址:http://www.cgigc.com.cn/isbn/index.html
游戏版号爬取本来是一时兴起,刚开始只是单纯想爬取一些游戏,自己查找价格什么的(坐等打折 )。后来突然想起今年3月份中国就开始限制游戏版号,于是有了点兴趣,就找到这个网站,爬取一些信息来进行分析。
直接贴上代码,也是用selenium做的网页爬取,分析基本与上面相同。就不再一一赘述了。
from selenium import webdriver
import re
import xlwt
import time
#网址
url_base = "http://www.cgigc.com.cn/isbn/index.html"
request = '?curPage='
opt = webdriver.ChromeOptions()
opt.set_headless()
singlePage = []
allGame = []
f = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = f.add_sheet('gameInfo', cell_overwrite_ok=True)
def writeExcelTitle():
row0 = ['游戏名称','出版单位名称','著作权人名称','游戏内容类别','批文号','游戏版号','审批时间']
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
def writeExcel():
for i in range(1, len(allGame)):
for j in range(0, len(allGame[i])):
sheet.write(i, j, allGame[i][j])
f.save(r'gameInfoofcgigc_demo01.xls')
def addInfo(list, info):
try:
list.append(info)
except:
print("error")
return
def addAllInfo(i, li):
single = []
addInfo(single,li[i].find_element_by_class_name('name').text)
addInfo(single,li[i].find_element_by_class_name('company').text)
addInfo(single,li[i].find_element_by_class_name('copyrightname').text)
addInfo(single,li[i].find_element_by_class_name('gametype').text)
text5 = li[i].find_element_by_class_name('official').text
addInfo(single,text5)
addInfo(single,li[i].find_element_by_class_name('isbn').text)
addInfo(single,re.findall('\d+',text5)[0])
addInfo(allGame, single)
def fillAllGame(driver):
li = driver.find_elements_by_xpath("//ul[@class='datas']/li")
for i in range(len(li)):
addAllInfo(i, li)
def main():
driver = webdriver.Chrome(options=opt)
driver.implicitly_wait(30)
driver.get(url_base)
time.sleep(1)
totalPages = driver.find_element_by_xpath("//span[@id='btn-pages-con']/a[6]").text
for i in range(int(totalPages)):
url = url_base + request + str(i+1)
driver.get(url)
time.sleep(1.5)
fillAllGame(driver)
print('第'+str(i+1)+'页')
driver.quit()
writeExcelTitle()
writeExcel()
main()
至此,信息爬取部分基本完成,excel是直接保存到你python文件所在文件夹下的。
部分数据分析
这里用第二个网址爬取的信息——游戏版号信息来分析(因为这个爬取到的数据解析简单得多 )
Excel图表
再使用python之前,我们先用excel的表图来看看数据关系。
审批时间与游戏数量之间的关系:

游戏类型:

其实关系已经很明显了,2017年获得版号审批的游戏最多。中国游戏版号申请中,移动游戏(手游)占比最多。看着这个数据总感觉怪怪的(该网站能获取的数据基本已经全部爬取下来了,16000多条数据,最后分析得到这个结果…)。
Python数据图表
接下来,是python(感觉上的高逼格 )来画图,这个时候就要用到matplotlib了
import xlrd
import collections
import matplotlib.pylab as plt
#导入excel文件
data = xlrd.open_workbook('gameInfoofcgigc_demo01.xls')
table = data.sheet_by_name('gameInfo')
#这个是按列读取,读取数据的一列,colx指定第几列,从0开始。
#start_rowx=1指定从第二行开始读取,0为第一行。
#start_end=None表示读取到末尾,也可以指定读到哪一行
listApproval = table.col_values(colx=6, start_rowx=1, end_rowx=None)
listGameType = table.col_values(colx=3, start_rowx=1, end_rowx=None)
这个方法只是为了添加一下换行符,不然x轴上的标签会挤在一起,每4个字符换一行
def addNewline(str):
str_list = list(str)
indexs = []
for i in range(len(str_list)):
if (i+1)%4 == 0:
indexs.append(i+1)
for j in reversed(indexs):
str_list.insert(j, '\n')
return "".join(str_list)
说是饼状图,同时还画了一个条形图,方便查看
#游戏类型饼状图
def drawPieChartGameType():
c = collections.Counter(listGameType)
x1,y1 = [],[]
for i in c.most_common(5):
x1.append(i[0])
y1.append(i[1])
x,y = [],[]
for i in c.keys():
x.append(addNewline(i))
y.append(c.get(i))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(1)
plt.title('游戏类型')
#第一个图
ax1 = plt.subplot(2,1,1)
#第二个图
ax2 = plt.subplot(2,1,2)
#指定第一个图
plt.sca(ax1)
cols2 = ['r','b','g','yellow',
'k','w','tan','honeydew',
'c','m','skyblue','violet']
#lables=x1和autopct='%1.1%%'解封后会发现字符挤在一团...
#移动游戏占比太大了,第二个原因是因为我没想着再做一个颜色标签了...
plt.pie(
y1,
# labels=x1,
colors=cols2,
startangle=90,
shadow=True
# autopct='%1.1f%%'
)
#指定第二个图
plt.sca(ax2)
plt.bar(x, y,color='g')
for x, y in zip(x, y):
plt.text(x, y, y, ha='center')
plt.show()
这个是折线图
def drawPlotChartApprovalTime():
c = collections.Counter(listApproval)
x,y = [],[]
x1 = sorted(c.keys(),key=lambda x:x[0])
for str1 in x1:
x.append(int(str1))
x.sort()
for i in x:
y.append(c.get(str(i)))
plt.plot(x, y, color='r')
for x,y in zip(x, y):
plt.text(x, y, y, ha="center")
plt.title("审批时间与审批数量关系", fontproperties="SimHei")
plt.show()
plt.close()
drawPlotChartApprovalTime()
drawPieChartGameType()
最后,就是python画出的图了
审批时间与审批数量:

各种游戏类型占比:
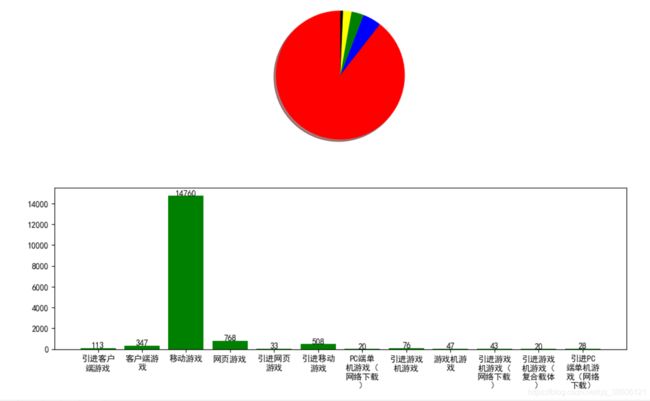
得到的数据和Excel画出的图表是差不多的…
转载:Python 数据科学入门教程:Matplotlib
对matplotlib有兴趣可以看看这个文章,里面有很多的画图方法。
到这儿基本就结束了,谢谢观看(谢谢你能忍受到这儿,看了各种啰里啰嗦的废话、不规整的命名、谜一样的代码格式等等 )
杂谈与感想
最后一点都是啰里啰嗦的废话和一点写爬虫的感想,跳过也无所谓的。
本来一开始爬取数据的时候,想用requests库(因为看起来很强 ),可是在爬取杉果和游戏版号查询这类动态网页的时候出现了各种各样的问题。请求获取不到数据,写了请求头,写post,获取json,各种方法都试过了,果然,还是因为我太菜了。最后只能选择这种最没有灵魂的爬取方式。
而且刚开始的时候还出现各种问题,用selenium爬取还是报错了,因为被锁ip…
嘛,最终算是成功获取到了数据吧。本来是想爬取游戏的信息,看一看有没有价格低的好游戏来着,后来跑偏了(因为一直获取不到数据挺难受的),爬取了游戏版号一类的。可以说最终成果和预想出入挺大。这些数据大概也能对目前中国游戏行业情况了解一二吧,只能知道一部分。喜欢游戏的人应该也知道2018年3月份的事情了,爬取数据完全是出于兴趣吧。
网上资源很多,愿你能学得更多,共勉。