imagenet classification with deep convolutional neural networks
3.1
这里用了ReLU, 而不是sigmoid或者是tanh, 在文章中称sigmoid或tanh为saturating nonlinearities. 为啥呢, 具体可见https://www.quora.com/Why-would-a-saturated-neuron-be-a-problem
这里我挑重点
The logistic has outputs between 0 and 1, the hyperbolic tangent between -1 and 1. These functions have to compress an infinite range into a finite range, and hence they display limiting behavior at the boundaries. In order to reach these boundaries, the inputs or the weights have to have extremely large positive or negative magnitude. We say that a neuron is saturated for these activation functions when it takes on values that are close to the boundaries of this range.
ReLU在靠近boundary的地方收敛比logistic or hyperbolic 收敛更快.
3.2 归一化处理
其实归一化处理就是为了防止saturating
具体原因可见: https://stats.stackexchange.com/questions/185853/why-do-we-need-to-normalize-the-images-before-we-put-them-into-cnn
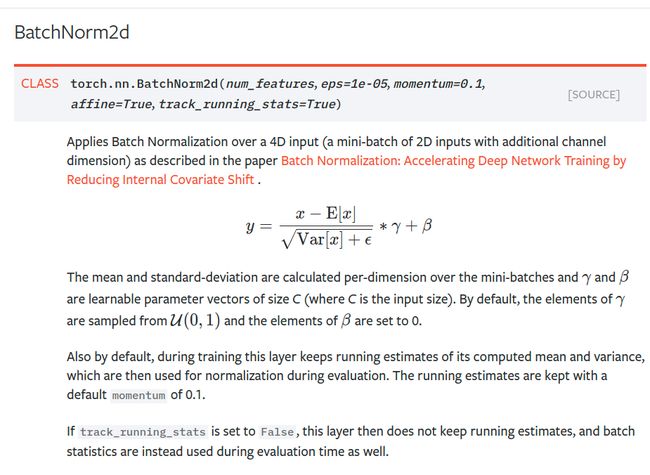
这里的归一化有点过时了, 现在更多的采用的是batch normalization
在pytorch里面我们输出看一下
import torch
import torchvision
if __name__ == '__main__':
alexnet = torchvision.models.alexnet(pretrained=True)
print(alexnet)

解释一下3 * 224 *224 到 48 * 55 * 55
H o u t = ⌊ H i n + 2 × padding [ 0 ] − dilation [ 0 ] × ( kernel_size [ 0 ] − 1 ) − 1 stride [ 0 ] + 1 ⌋ H_{out} = \left\lfloor\frac{H_{in} + 2 \times \text{padding}[0] - \text{dilation}[0] \times (\text{kernel\_size}[0] - 1) - 1}{\text{stride}[0]} + 1\right\rfloor Hout=⌊stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1⌋
W o u t = ⌊ W i n + 2 × padding [ 1 ] − dilation [ 1 ] × ( kernel_size [ 1 ] − 1 ) − 1 stride [ 1 ] + 1 ⌋ W_{out} = \left\lfloor\frac{W_{in} + 2 \times \text{padding}[1] - \text{dilation}[1] \times (\text{kernel\_size}[1] - 1) - 1}{\text{stride}[1]} + 1\right\rfloor Wout=⌊stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1⌋
224 + 4 − ( 11 − 1 ) − 1 4 + 1 = 55.25 \frac{224 + 4 - (11 - 1) -1}{4} + 1 = 55.25 4224+4−(11−1)−1+1=55.25
/home/seamanj/Software/anaconda3/bin/python3.7 /home/seamanj/Workspace/AlexNet/main.py
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) # tj : 注意这里用的是64
(1): ReLU(inplace)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Dropout(p=0.5)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace)
(3): Dropout(p=0.5)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Process finished with exit code 0