Binder源码分析之驱动层(原)
前言
在《 Binder源码分析之ServiceManager》一文中我们介绍了利用Binder进行通讯的流程,即ServiceManager把自己注册为“管理员”之后,负责其他Service的add操作,或者其他Client的get操作。在这个过程中,有一些接口我们并没有深入分析,比如:1、打开Binder
open("/dev/binder", O_RDWR)
mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0)
3、设置ServiceManager为管理员
ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0)
ioctl(bs->fd, BINDER_WRITE_READ, &bwr)
一、Binder驱动概述
1.1、Binder驱动所处的地位
在整个Binder框架中,涉及到四个参与方:ServiceManager、Binder驱动、Service、Client。 其中ServiceManager是管理者,Binder是驱动提供者,Service和Client可以看作是Binder的使用方。在上面提到的四个参与方中,只有Binder驱动运行于内核控件,其他部分全部运行于用户空间。
1.2、Binder驱动核心
Binder驱动的核心是维护一个binder_proc类型的链表。里面记录了包括ServiceManager在内的所有Client信息,当Client去请求得到某个Service时,Binder驱动就去binder_proc中查找相应的Service返回给Client,同时增加当前Service的引用个数。Binder驱动源码主要在google-code\kernel\drivers\staging\android\binder.c中,下面我们分别介绍Binder驱动中重要的接口。
二、Binder初始化过程
Binder驱动的初始化是在binder_init()函数中完成的: static int __init binder_init(void) {
int ret;
binder_deferred_workqueue = create_singlethread_workqueue("binder");
//创建binder设备文件夹
binder_debugfs_dir_entry_root = debugfs_create_dir("binder", NULL);
if (binder_debugfs_dir_entry_root)
binder_debugfs_dir_entry_proc = debugfs_create_dir("proc", binder_debugfs_dir_entry_root);
//注册成为misc设备
ret = misc_register(&binder_miscdev);
if (binder_debugfs_dir_entry_root) {
//创建各个文件
debugfs_create_file("state", S_IRUGO, binder_debugfs_dir_entry_root, NULL, &binder_state_fops);
debugfs_create_file("stats", S_IRUGO, binder_debugfs_dir_entry_root, NULL, &binder_stats_fops);
debugfs_create_file("transactions", S_IRUGO, binder_debugfs_dir_entry_root, NULL, &binder_transactions_fops);
debugfs_create_file("transaction_log", S_IRUGO, binder_debugfs_dir_entry_root, &binder_transaction_log, &binder_transaction_log_fops);
debugfs_create_file("failed_transaction_log", S_IRUGO, binder_debugfs_dir_entry_root, &binder_transaction_log_failed, &binder_transaction_log_fops);
}
return ret;
}
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "binder",
.fops = &binder_fops
};
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
从这个成员变量的定义中我们可以看到这个设备所具备的接口,其中最重要的就是binder_ioctl、open和mmap。当我们对这个设备进行各种操作时,就会调用其中的函数。
三、打开Binder的方法
我们在《 Binder源码分析之ServiceManager》中介绍过,ServiceManager初始化的第一步就是打开Binder设备: bs->fd = open("/dev/binder", O_RDWR);
static int binder_open(struct inode *nodp, struct file *filp) {
struct binder_proc *proc;
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
//得到当前进程
get_task_struct(current);
proc->tsk = current;
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
//记录进程优先级
proc->default_priority = task_nice(current);
mutex_lock(&binder_lock);
binder_stats_created(BINDER_STAT_PROC);
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
//把proc保存在Binder描述符的private_data中
filp->private_data = proc;
mutex_unlock(&binder_lock);
return 0;
}
我们看到,在binder_open的过程中,构建了binder_procs类型的proc数据,并把他保存在file的private_data中。
四、映射虚拟空间的过程
我们在ServiceManager的分析中讲到,打开Binder设备之后紧接着就进行了地址映射: bs->mapped = mmap(NULL, mapsize, PROT_READ, MAP_PRIVATE, bs->fd, 0);
static int binder_mmap(struct file *filp, struct vm_area_struct *vma) {
int ret;
//需要映射的内核空间地址信息
struct vm_struct *area;
//取出binder_open时保存的binder_proc数据
struct binder_proc *proc = filp->private_data;
struct binder_buffer *buffer;
//保证这块内存最多只有4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
vma->vm_flags = (vma->vm_flags | VM_DONTCOPY) & ~VM_MAYWRITE;
//申请一段内存空间给内核进程
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
//得到映射的内核空间虚拟地址首地址
proc->buffer = area->addr;
//计算用户空间与映射的内核空间的地址偏移量
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
//得到映射地址的页数
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
//映射空间的大小
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
//为虚拟地址空间proc->buffer ~ proc->buffer + PAGE_SIZE 分配一个空闲的物理页面
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
return 0;
err_alloc_small_buf_failed:
kfree(proc->pages);
proc->pages = NULL;
err_alloc_pages_failed:
vfree(proc->buffer);
proc->buffer = NULL;
err_get_vm_area_failed:
err_already_mapped:
err_bad_arg:
return ret;
}
在binder_mmap()的开始地方,将申请的进程空间地址的大小约束在了4M,然后通过get_vm_area()函数在内核空间映射了一块虚拟地址,同时把进程空间的虚拟地址和内核空间的虚拟地址之间偏移量放入了proc->user_buffer_offset变量中,接着, 调用binder_update_page_range()函数为进程空间和内核空间的虚拟地址映射同一个物理页面,从而达到进程空间和内核空间共享一块物理页面的目的。
我们具体来看一下如何把同一块物理页面同时插入内核空间和用户空间中:
static int binder_update_page_range(struct binder_proc *proc, int allocate, void *start, void *end, struct vm_area_struct *vma) {
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
//以页为单位分配物理页面,由于此时的end=start+PAGE_SIZE,因此只会循环一次
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
//分配物理页面
*page = alloc_page(GFP_KERNEL | __GFP_ZERO);
if (*page == NULL) {
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
page_array_ptr = page;
//把这个物理页面插入到内核空间去
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr);
if (ret) {
goto err_map_kernel_failed;
}
user_page_addr = (uintptr_t)page_addr + proc->user_buffer_offset;
//将这个物理页面插入到进程地址空间去
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret) {
goto err_vm_insert_page_failed;
}
}
return 0;
}
这恰恰是Binder通讯的精华所在:当把同一块物理页面同时映射到进程空间和内核空间时,当需要在两者之间传递数据时,只需要其中任意一方把数据拷贝到物理页面,另一方直接读取即可,也就是说,数据的跨进程传递,只需要一次拷贝就可以完成。
我们用图来对比一下这种设计思路的优势。
首先看一下正常情况下数据跨进程传递的过程:
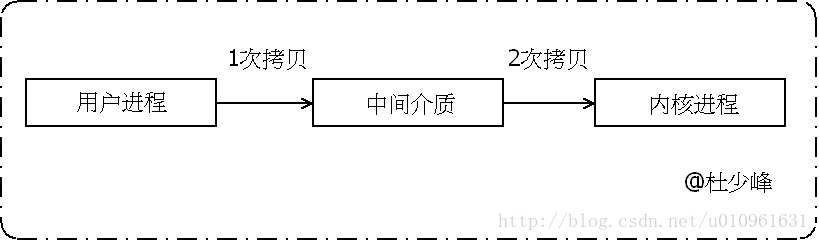
这个过程中,至少需要两次拷贝的动作,然后再来看Binder的拷贝机制:
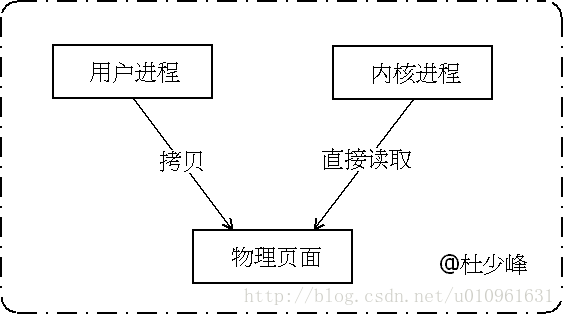
我们发现Binder通讯中只需要执行一次拷贝的动作就可以完成数据的传递,这样的设计大大提高了数据传递的效率。
五、与客户端交换数据的过程
对Binder驱动来说,无论是ServiceManager还是Service和Client,都是客户端。我们在ServiceManager流程的介绍中看到,他与Binder驱动的数据交换是通过ioctl()实现的: static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
int ret;
//得到当前客户端的数据
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
//得到当前线程的binder_thread信息
thread = binder_get_thread(proc);
switch (cmd) {
case BINDER_WRITE_READ:{}
case BINDER_SET_MAX_THREADS:{}
case BINDER_SET_CONTEXT_MGR:{}
case BINDER_THREAD_EXIT:{}
case BINDER_VERSION:{}
default:{}
}
ret = 0;
return ret;
}
从这个函数的case中我们看到,他可以实现读写、设置“管理员”、设置最大线程数、退出线程、查询版本等操作,其中最有用的就是BINDER_WRITE_READ和BINDER_SET_CONTEXT_MGR这两个分支。
5.1、ioctl之BINDER_WRITE_READ
我们先来看BINDER_WRITE_READ这个处理: static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
int ret;
thread = binder_get_thread(proc);
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
//把用户传递进来的参数转换成到bwr中
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto err;
}
if (bwr.write_size > 0) {
//写操作
ret = binder_thread_write(proc, thread, (void __user *)bwr.write_buffer, bwr.write_size, &bwr.write_consumed);
}
if (bwr.read_size > 0) {
//读操作
ret = binder_thread_read(proc, thread, (void __user *)bwr.read_buffer, bwr.read_size, &bwr.read_consumed, filp->f_flags & O_NONBLOCK);
if (!list_empty(&proc->todo))
wake_up_interruptible(&proc->wait);
}
//读写成功,把返回值写回给客户端
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
}
break;
}
case BINDER_SET_MAX_THREADS:{}
case BINDER_SET_CONTEXT_MGR:{}
case BINDER_THREAD_EXIT:{}
case BINDER_VERSION:{}
default:{}
}
ret = 0;
return ret;
}
我们看到,在ioctl()内部区分了读写的操作,其中写操作是通过binder_thread_write()实现的,读操作是通过binder_thread_read()实现的,我们分开来分析。
5.1.1、ioctl之写操作
所谓写的操作,主要完成的任务有两种: 1、写入数据;2、设置状态。我们直接来看负责写操作的函数。 int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) {
uint32_t cmd;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
//用while检测是否已经读取所有的命令
while (ptr < end && thread->return_error == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_INCREFS:
case BC_ACQUIRE:
case BC_RELEASE:
case BC_DECREFS:{}
case BC_INCREFS_DONE:
case BC_ACQUIRE_DONE:{}
case BC_ATTEMPT_ACQUIRE:{}
case BC_ACQUIRE_RESULT:{}
case BC_FREE_BUFFER:{}
case BC_TRANSACTION:
case BC_REPLY:{}
case BC_REGISTER_LOOPER:{}
case BC_ENTER_LOOPER:{}
case BC_EXIT_LOOPER:{}
case BC_REQUEST_DEATH_NOTIFICATION:
case BC_CLEAR_DEATH_NOTIFICATION:{}
case BC_DEAD_BINDER_DONE:{}
default:
}
*consumed = ptr - buffer;
}
return 0;
}
BC_INCREFS: 用于得到一个Service,而且得到的是Service的弱引用
BC_ACQUIRE: 与BC_INCREFS类似,得到一个Service,但是得到的是强引用
BC_ENTER_LOOPER: Service将要进入Loop状态时,发送此消息
BC_EXIT_LOOPER: Service退出Loop状态
下面我们来详细分析。
5.1.1.1、BC_INCREFS与BC_ACQUIRE
当一个客户端对ServiceManager请求getService时,ServiceManager将会对Binder驱动发送这两种命令,目的就是把目标Service发送给客户端,同时增加目标Service的引用个数。 int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) {
uint32_t cmd;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
//得到当前的命令号
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_INCREFS:
case BC_ACQUIRE:
case BC_RELEASE:
case BC_DECREFS: {
uint32_t target;
struct binder_ref *ref;
//get_user()的作用是复制内存
if (get_user(target, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
if (target == 0 && binder_context_mgr_node && (cmd == BC_INCREFS || cmd == BC_ACQUIRE)) {
//客户端要取得的Service是ServiceManager
ref = binder_get_ref_for_node(proc, binder_context_mgr_node);
} else{
//客户端要取得其他的Service
ref = binder_get_ref(proc, target);
}
switch (cmd) {
case BC_INCREFS:
//增加当前Service的弱引用
binder_inc_ref(ref, 0, NULL);
break;
case BC_ACQUIRE:
//增加当前Service的强引用
binder_inc_ref(ref, 1, NULL);
break;
case BC_RELEASE:
//释放引用
binder_dec_ref(ref, 1);
break;
case BC_DECREFS:
default:
binder_dec_ref(ref, 0);
break;
}
break;
}
default:
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}
但是在得到目标Service的过程中出现了两种情况,第一种情况是,Client要得到的Service正好是ServiceManager这个“Service”,第二种情况是,Client要得到的Service是普通的Service。
对于要得到ServiceManager这种情况,需要通过binder_get_ref_for_node()的方式从Binder的binder_proc红黑树中查找binder_context_mgr_node的节点,并把表示ServiceManager的节点传递给Client。
而对于普通的Service这种情况,与ServiceManager类似,需要通过binder_get_ref()的函数从Binder的binder_proc红黑树中查找相应的节点:
static struct binder_ref *binder_get_ref(struct binder_proc *proc, uint32_t desc) {
struct rb_node *n = proc->refs_by_desc.rb_node;
struct binder_ref *ref;
//从红黑树中查找目标Service的节点
while (n) {
ref = rb_entry(n, struct binder_ref, rb_node_desc);
if (desc < ref->desc)
n = n->rb_left;
else if (desc > ref->desc)
n = n->rb_right;
else
return ref;
}
return NULL;
}
static int binder_inc_ref(struct binder_ref *ref, int strong, struct list_head *target_list) {
int ret;
//不同的参数决定了是强引用还是弱引用
if (strong) {
//强引用
if (ref->strong == 0) {
ret = binder_inc_node(ref->node, 1, 1, target_list);
if (ret)
return ret;
}
ref->strong++;
} else {
//弱引用
if (ref->weak == 0) {
ret = binder_inc_node(ref->node, 0, 1, target_list);
if (ret)
return ret;
}
ref->weak++;
}
return 0;
}
5.1.1.2、BC_ENTER_LOOPER与BC_EXIT_LOOPER
下面我们来分析关于进退Loop状态的两种binder_thread_write两种case。 int binder_thread_write(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed) {
uint32_t cmd;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_ENTER_LOOPER:
//进入Loop状态
if (thread->looper & BINDER_LOOPER_STATE_REGISTERED) {
thread->looper |= BINDER_LOOPER_STATE_INVALID;
}
//thread->looper值变为BINDER_LOOPER_STATE_ENTERED了
thread->looper |= BINDER_LOOPER_STATE_ENTERED;
break;
case BC_EXIT_LOOPER:
//退出Loop状态
thread->looper |= BINDER_LOOPER_STATE_EXITED;
break;
default:
return -EINVAL;
}
*consumed = ptr - buffer;
}
return 0;
}
至此,我们分析了ioctl的写操作的过程,主要是针对其内部四个主要的消息进行分析,分别是BC_INCREFS、BC_ACQUIRE、BC_ENTER_LOOPER、BC_EXIT_LOOPER。
5.1.2、ioctl之读操作
下面我们来分析ioctl的读操作: static int binder_thread_read(struct binder_proc *proc, struct binder_thread *thread, void __user *buffer, int size, signed long *consumed, int non_block) {
retry:
//判断当前是否有内容需要读取
wait_for_proc_work = thread->transaction_stack == NULL && list_empty(&thread->todo);
mutex_unlock(&binder_lock);
//根据线程阻塞模式和当前的未读信息判断是否阻塞等待
if (wait_for_proc_work) {
//设置当前优先级与线程自己的优先级相同
binder_set_nice(proc->default_priority);
if (non_block) {
if (!binder_has_proc_work(proc, thread))
ret = -EAGAIN;
} else{
ret = wait_event_interruptible_exclusive(proc->wait, binder_has_proc_work(proc, thread));
}
} else {
if (non_block) {
if (!binder_has_thread_work(thread))
ret = -EAGAIN;
} else
ret = wait_event_interruptible(thread->wait, binder_has_thread_work(thread));
}
mutex_lock(&binder_lock);
//进入读取模式
thread->looper &= ~BINDER_LOOPER_STATE_WAITING;
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
//读取todo列表中的节点
if (!list_empty(&thread->todo))
w = list_first_entry(&thread->todo, struct binder_work, entry);
else if (!list_empty(&proc->todo) && wait_for_proc_work)
w = list_first_entry(&proc->todo, struct binder_work, entry);
else {
if (ptr - buffer == 4 && !(thread->looper & BINDER_LOOPER_STATE_NEED_RETURN))
goto retry;
break;
}
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work);
} break;
case BINDER_WORK_TRANSACTION_COMPLETE: {
cmd = BR_TRANSACTION_COMPLETE;
//将读取的数据放入用户空间
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
binder_stat_br(proc, thread, cmd);
//删除当前节点
list_del(&w->entry);
kfree(w);
binder_stats_deleted(BINDER_STAT_TRANSACTION_COMPLETE);
} break;
case BINDER_WORK_NODE: {} break;
case BINDER_WORK_DEAD_BINDER:
case BINDER_WORK_DEAD_BINDER_AND_CLEAR:
case BINDER_WORK_CLEAR_DEATH_NOTIFICATION: {} break;
}
}
done:
return 0;
}
下面用一张图来小结一下ioctl的读写操作流程。
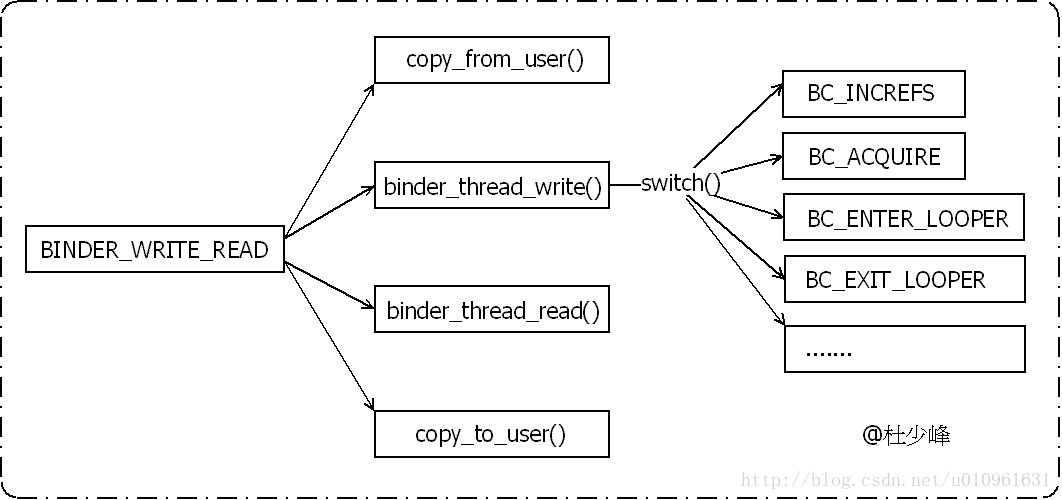
5.2、ioctl之BINDER_SET_CONTEXT_MGR
ioctl中的BINDER_SET_CONTEXT_MGR分支,只有ServiceManager在binder_become_context_manager()中调用: int binder_become_context_manager(struct binder_state *bs) {
return ioctl(bs->fd, BINDER_SET_CONTEXT_MGR, 0);
}
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
//得到当前线程的binder_thread信息
thread = binder_get_thread(proc);
switch (cmd) {
case BINDER_WRITE_READ: { }
case BINDER_SET_MAX_THREADS:
break;
case BINDER_SET_CONTEXT_MGR:
//确认当前没有ServiceManager的实体
if (binder_context_mgr_node != NULL) {
printk(KERN_ERR "binder: BINDER_SET_CONTEXT_MGR already set\n");
ret = -EBUSY;
goto err;
}
//初始化binder_context_mgr_uid为当前进程的uid
if (binder_context_mgr_uid != -1) {
if (binder_context_mgr_uid != current->cred->euid) {
//确保uid为当前进程的uid
ret = -EPERM;
goto err;
}
} else{
binder_context_mgr_uid = current->cred->euid;
}
//为ServiceManager创建Binder实体
binder_context_mgr_node = binder_new_node(proc, NULL, NULL);
if (binder_context_mgr_node == NULL) {
ret = -ENOMEM;
goto err;
}
//初始化强引用和弱引用的个数
binder_context_mgr_node->local_weak_refs++;
binder_context_mgr_node->local_strong_refs++;
binder_context_mgr_node->has_strong_ref = 1;
binder_context_mgr_node->has_weak_ref = 1;
break;
case BINDER_THREAD_EXIT:
break;
case BINDER_VERSION:
break;
default:
goto err;
}
ret = 0;
err:
if (thread) thread->looper &= ~BINDER_LOOPER_STATE_NEED_RETURN;
mutex_unlock(&binder_lock);
wait_event_interruptible(binder_user_error_wait, binder_stop_on_user_error < 2);
return ret;
}
现在我们回顾一下5.1.1.1节中介绍的ioctl函数中请求BC_INCREFS与BC_ACQUIRE的命令,当客户端请求该命令时,即要求得到某个Service,此时就要区分客户端得到的Service是否是ServiceManager,如果要得到的Service就是ServiceManager,那么就需要去红黑树中查找binder_context_mgr_node节点,而这个节点就是ServiceManager在Binder驱动中的节点。否则的话,就用目标Service名字去查找相应的节点即可。
这就是ioctl中BINDER_SET_CONTEXT_MGR分支所做的工作。
至此,Binder驱动部分的主要原理也介绍完毕,经过这一节的分析,我们了解了Binder驱动设备的创建、打开过程,以及其他进程是如何与Binder设备交换数据的。