在过去的一年中的数据库相关的源代码分析。前段时间分析levelDB实施和BeansDB实现,数据库网络分析这两篇文章非常多。他们也比较深比较分析,所以没有必要重复很多劳力。MYSQL,当然主要还是数据库存储引擎,首先我还是从innodb这个最流行的开源关系数据库引擎着手来逐步分析和理解。
我一般分析源代码的时候都是从基础的数据结构和算法逐步往上分析。遇到不明确的地方,自己依照源代码又一次输入一遍并做相应的单元測试,这样便于理解。对于Innodb这种大项目,也应该如此,以后我会逐步将详细的细节和实现写到BLOG上。我分析Innodb是以MySQL-3.23为蓝本作为分析对象,然后再去比較5.6版本号的修改来做分析的。这样做有个优点就是先理解相对基础的代码easy。在有了基本概念后再去理解最新的修改。下面是我对innodb基础的数据结构和算法的理解。
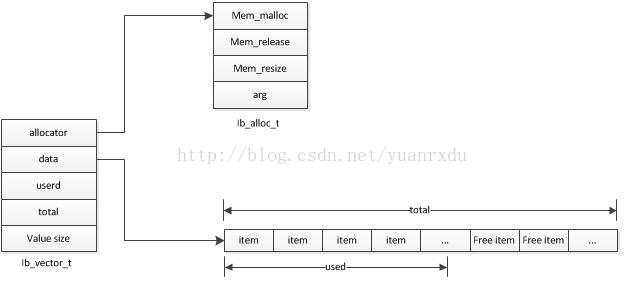
1.vector
struct ib_alloc_t {
ib_mem_alloc_t mem_malloc; //分配器的malloc函数指针
ib_mem_free_t mem_release; //分配器的free函数指针
ib_mem_resize_t mem_resize; //分配器的又一次定义堆大小指针
void* arg; //堆句柄,假设是系统的malloc方式,这个值为NULL
};
2.内存list
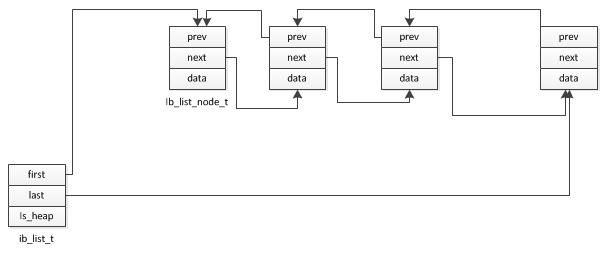
3.FIFO-queue
queue处理提供一直读取到消息为止的方法以外,也提供最长等待读取消息的方法。这样读取线程没有必要一直等待消息。能够在等待一段时间后去处理其它的任务。其C结构定义例如以下:
struct ib_wqueue_t
{
ib_mutex_t mutex; /*相互排斥量*/
ib_list_t* items; /*用list作为queue的载体*/
os_event_t event; /*信号量*/
};4.哈希表
在hash_create_sync_obj_func函数调用过程中,会创建一个n_sync_obj的锁数据单元。n_sync_obj必须是2的N次方。也就是说假设n_sync_obj = 8, 哈希表的n_cells = 19。那就至少两个cell公用一个锁。
这是其它哈希表无法比拟的。
struct hash_table_t
{
enum hash_table_sync_t type; /*hash table的同步类型*/
ulint n_cells; /*hash桶个数*/
hash_cell_t* array; /*hash桶数组*/
#ifndef UNIV_HOTBACKUP
ulint n_sync_obj;
union{ /*同步锁*/
ib_mutex_t* mutexes;
rw_lock_t* rw_locks;
}sync_obj;
/*heaps的单元个数和n_sync_obj一样*/
mem_heap_t** heaps;
#endif
mem_heap_t* heap;
ulint magic_n; /*校验魔法字*/
#endif
};5.小结
这样做的目的是为了统一的管理。
innodb的代码是C的。但支持C++。里面并没有使用STL这样的传统的数据结构和算法,非常大程度上是适合性的问题。
据说MYSQL 5.7開始大量使用boost 和STL。
个人感觉STL还勉强。使用boost有点感觉阔步前进。
版权声明:本文博主原创文章,博客,未经同意不得转载。