Spark学习七 ——总体流程分析
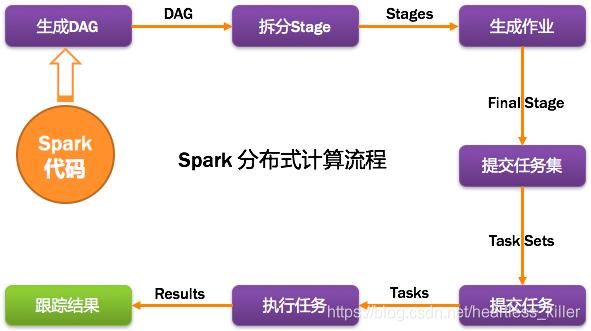
Spark总体流程简述
 1.构建DAG(调用RDD上的方法)在driver段
1.构建DAG(调用RDD上的方法)在driver段
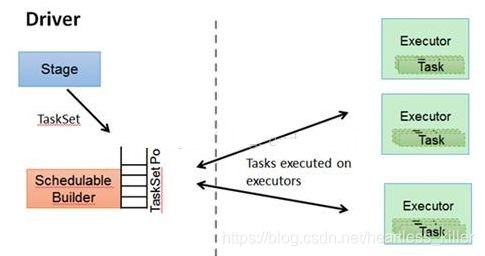
2.DAGScheduler将DAG切分Stage(切分的依据是Shuffle),将Stage中生成的Task以TaskSet的形式给TaskScheduler,在driver段
3.TaskScheduler调度Task(根据资源情况将Task调度到相应的Executor中),在driver段
4.Executor接收Task,然后将Task丢入到线程池中执行,executor中
常见术语
Application:表示你的应用程序
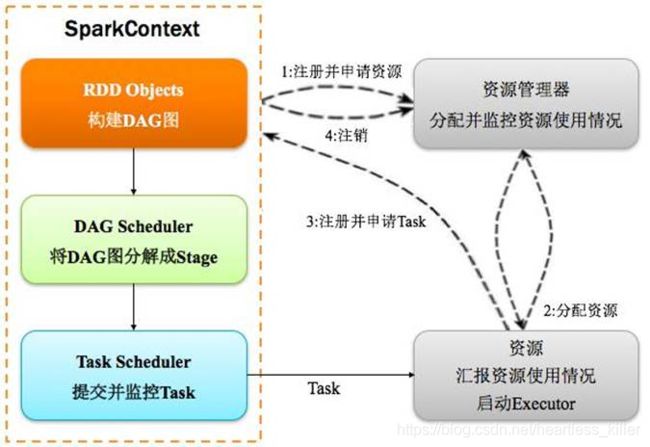
Driver:表示main()函数,创建SparkContext。由SparkContext负责与ClusterManager通信,进行资源的申请,任务的分配和监控等。程序执行完毕后关闭SparkContext
Executor:某个Application运行在Worker节点上的一个进程,该进程负责运行某些task,并且负责将数据存在内存或者磁盘上。在Spark on Yarn模式下,其进程名称为 CoarseGrainedExecutor Backend,一个CoarseGrainedExecutor Backend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task,这样,每个CoarseGrainedExecutorBackend能并行运行Task的数据就取决于分配给它的CPU的个数。
Cluter Manager:指的是在集群上获取资源的外部服务。目前有三种类型
Standalone : spark原生的资源管理,由Master负责资源的分配
Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架
Hadoop Yarn: 主要是指Yarn中的ResourceManager
Worker: 集群中任何可以运行Application代码的节点,在Standalone模式中指的是通过slave文件配置的Worker节点,在Spark on Yarn模式下就是NoteManager节点
Task: 被送到某个Executor上的工作单元,但hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责
Job: 包含多个Task组成的并行计算,往往由Spark Action触发生成, 一个Application中往往会产生多个Job
Stage: 每个Job会被拆分成多组Task, 作为一个TaskSet, 其名称为Stage,Stage的划分和调度是有DAGScheduler来负责的,Stage有非最终的Stage(Shuffle Map Stage)和最终的Stage(Result Stage)两种,Stage的边界就是发生shuffle的地方
DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法,如下图
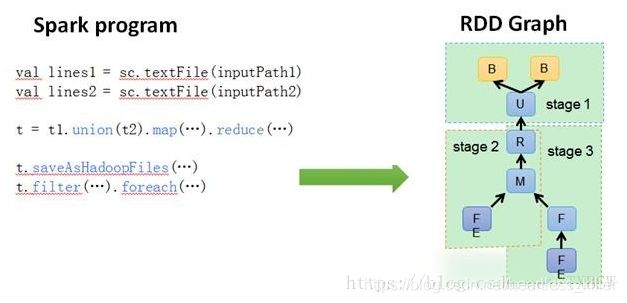 TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用
TASKSedulter: 将TaskSET提交给worker运行,每个Executor运行什么Task就是在此处分配的. TaskScheduler维护所有TaskSet,当Executor向Driver发生心跳时,TaskScheduler会根据资源剩余情况分配相应的Task。另外TaskScheduler还维护着所有Task的运行标签,重试失败的Task。下图展示了TaskScheduler的作用
构建DAG
什么是DAG
-
DAG:有向无环图
-
DAG 是一组顶点和边的组合。顶点代表了 RDD, 边代表了对 RDD 的一系列操作。
-
DAG的数量由触发action次数决定
-
DAG是开始于通过SparkContext创建的RDD,结束于触发Action,调用run Job,就是一个完整的DAG就形成了。一旦触发Action就形成了一个完整的DAG。
-
一个RDD只是描述了数据计算过程中的一个环节,而DGA由一到多个RDD组成,描述了数据计算过程中的所有环节(过程)
DAG 解决了什么问题
DAG描述多个RDD的转换过程,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程),即描述RDD被转化的过程
DAG 的出现主要是为了解决 Hadoop MapReduce 框架的局限性。那么 MapReduce 有什么局限性呢?
主要有两个:
- 每个 MapReduce 操作都是相互独立的,HADOOP不知道接下来会有哪些Map Reduce。
- 每一步的输出结果,都会持久化到硬盘或者 HDFS 上。
当以上两个特点结合之后,我们就可以想象,如果在某些迭代的场景下,MapReduce 框架会对硬盘和 HDFS 的读写造成大量浪费。
而且每一步都是堵塞在上一步中,所以当我们处理复杂计算时,会需要很长时间,但是数据量却不大。
所以 Spark 中引入了 DAG,它可以优化计算计划,比如减少 shuffle 数据。
切分STAGE
DAGScheduler: 根据Job构建基于Stage的DAG(Directed Acyclic Graph有向无环图),将其进行切分,根据shullfe(宽依赖),并提交Stage给TASkScheduler。 其划分Stage的依据是RDD之间的依赖的关系找出开销最小的调度方法
为什么要切分Stage?
一个复杂的业务逻辑(将多台机器上具有相同属性的数据聚合到一台机器上:shuffle)如果有shuffle,那么就意味着前面阶段产生的结果后,才能执行下一个阶段,下一个阶段的计算要依赖上一个阶段的数据。在同一个Stage中,会有多个算子,可以合并在一起,我们称其为pipeline(流水线:严格按照流程、顺序执行)
由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。
shuffle过程可能需要完成以下过程
-
重新进行数据分区
-
数据传输
-
数据压缩
-
磁盘I/O
RDD依赖关系和宽窄依赖
RDD依赖关系,也就是有依赖的RDD之间的关系,比如RDD1------->RDD2(RDD1生成RDD2),RDD2依赖于RDD1。这里的生成也就是RDDtransformation操作
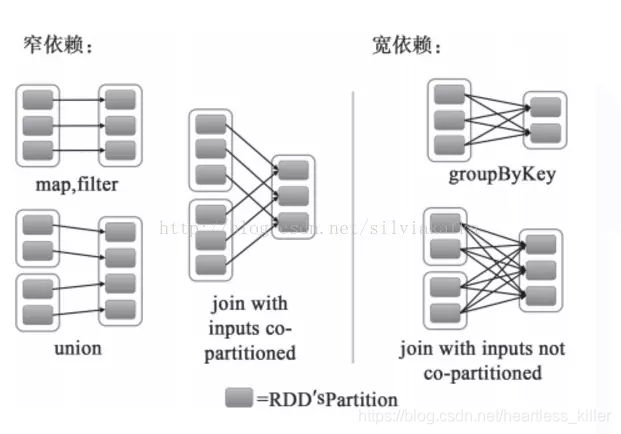
- 窄依赖(也叫narrow依赖)
父分区只有一个箭头,发往一个分区,子分区的数据来自部分分区
从父RDD角度看:一个父RDD只被一个子RDD分区使用。父RDD的每个分区最多只能被一个Child RDD的一个分区使用
从子RDD角度看:依赖上级RDD的部分分区 精确知道依赖的上级RDD分区,会选择和自己在同一节点的上级RDD分区,没有网络IO开销,高效。如map,flatmap,filter
- 宽依赖(也叫shuffle依赖/wide依赖)
父分区只有多个箭头,发往多个分区,子分区的数据来自全部分区
从父RDD角度看:一个父RDD被多个子RDD分区使用。父RDD的每个分区可以被多个Child RDD分区依赖
从子RDD角度看:依赖上级RDD的所有分区 无法精确定位依赖的上级RDD分区,相当于依赖所有分区(例如reduceByKey) 计算就涉及到节点间网络传输
根本区分方式:是根据分区器是否一样(分区数量一样和分区规则一样)
或者说是否发生 shuffle(洗牌)
Spark之所以将依赖分为narrow和 shuffle:
(1) narrow dependencies可以支持在同一个集群Executor上,以pipeline管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败恢复也更有效,因为它只需要重新计算丢失的parent partition即可,
(2)shuffle dependencies 则需要所有的父分区都是可用的,必须等RDD的parent partition数据全部ready之后才能开始计算,可能还需要调用类似MapReduce之类的操作进行跨节点传递。从失败恢复的角度看,shuffle dependencies 牵涉RDD各级的多个parent partition。
步骤详解:
1.从代码构建DAG图
Spark的计算发生在RDD的Action操作,而对Action之前的所有Transformation,Spark只是记录下RDD生成的轨迹,而不会触发真正的计算。
Spark内核会在需要计算发生的时刻绘制一张关于计算路径的有向无环图,也就是DAG。
2.将DAG划分为Stage核心算法,通过DAGSchedule
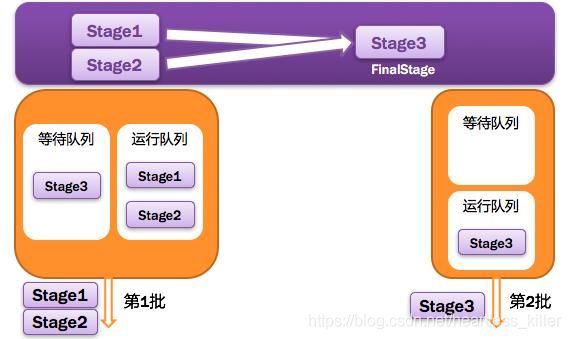
Application多个job多个Stage:
Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:
Stage划分的依据就是宽依赖,何时产生宽依赖(shuffle),reduceByKey, groupByKey等算子,会导致宽依赖的产生。
核心算法:
-
从后往前回溯/反向解析,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。
-
Spark内核会从触发Action操作的那个RDD开始从后往前推,
-
首先会为最后一个RDD创建一个stage,
-
然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。
-
然后依次类推,继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
3.提交Stages
调度阶段的提交,最终会被转换成一个任务集的提交,DAGScheduler通过TaskScheduler接口提交任务集。
这个任务集最终会触发TaskScheduler构建一个TaskSetManager的实例来管理这个任务集的生命周期,
对于DAGScheduler来说,提交调度阶段的工作到此就完成了。
而TaskScheduler的具体实现则会在得到计算资源的时候,进一步通过TaskSetManager调度具体的任务到对应的Executor节点上进行运算。
spark总体流程
总体流程详解
- 构建Spark Application的运行环境
val conf = new SparkConf();
conf.setAppName("test01")
conf.setMaster("local")
val sc = new SparkContext(conf)
-
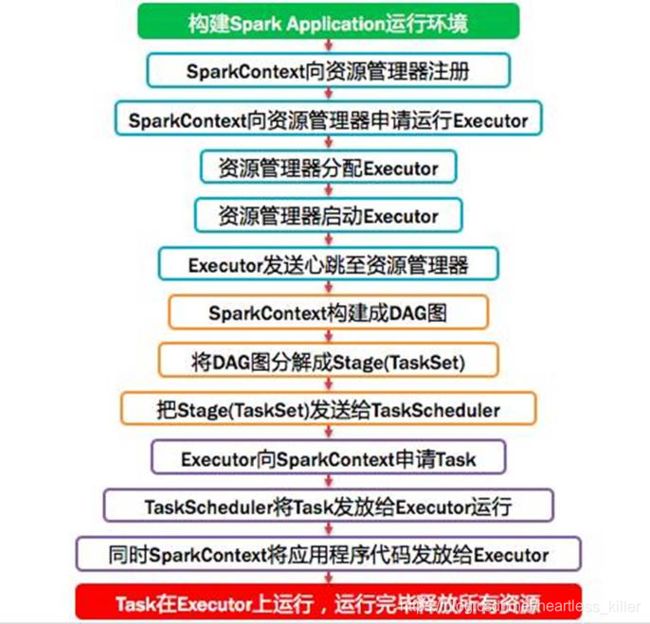
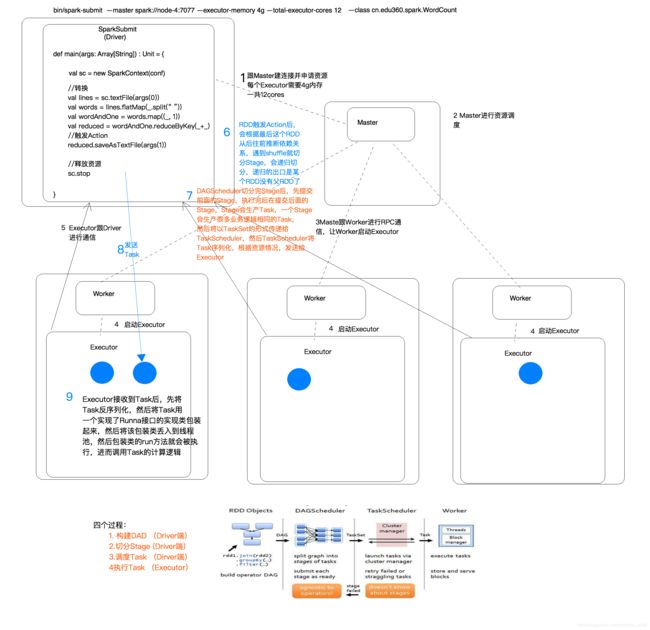
启动SparkContext,SparkContext(Driver)向资源管理器(可以是Standalone,Mesos,Yarn)申请运行Executor资源,并启动与master建立连接
-
master和worker进行RPC通信,让worker启动executor
-
各个worker启动executor,然后和executor进行通信,汇报自己的状态(具体流程参考之前的博客)
-
RDD触发 Action后,会根据最后这个RDD从后往前推断依赖关系,遇到 shuffler就切分 Stage,会递归切分,递归的出口是某个RDD没有父RDD了(上文有算法详情)
/指定以后从哪里读取数据创建RDD(弹性分布式数据集)
val lines: RDD[String] = sc.textFile("hdfs://node-4:9000/wc1", 1)
//分区数量
partitionsNum=lines.partitions.length
//切分压平
val words: RDD[String] = lines.flatMap(_.split(" "))
//将单词和一组合
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
//按key进行聚合
val reduced:RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2, false)
//将结果保存到HDFS中,触发action
reduced.saveAsTextFile(args(1))
//释放资源
sc.stop()
- DAGSchedulert切分完 Stage后,先提交前西的Stage,执行完后在提交后面的Stage.Spge会生产Task,一个 Stage会生产很多业务逻辑相同的Task,后将以TaskSet形式传给Taskscheduler,然后 TaskSheduler将Task序列化,根据资源情况,发送给各个Executor
- Executor接收到Task后,先将Task反序列化,然后将Task用一个实现了 Runnable接口的实现类装起来,然后将该包装类丢入到线程池,然后包装类的run方法就会被执行,进而调用Task的计算逻辑