Weka使用
下载地址https://sourceforge.net/projects/weka/
Weka是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)的英文字首缩写,在该网站可以免费下载可运行软件和源代码,还可以获得说明文档、常见问题解答、数据集和其他文献等资源。Weka是新西兰怀卡托大学用Java开发的数据挖掘著名开源软件,该系统自1993年开始由新西兰政府资助,至今已经历了20年的发展,其功能已经十分强大和成熟。
Weka作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及在新的交互式界面上的可视化。如果想自己实现数据挖掘算法的话,可以看一看WEKA的接口文档。在WEKA中集成自己的算法甚至借鉴它的方法自己实现可视化工具并不是件很困难的事情。
安装过程很简单,这里不做介绍
一般常用的有四个应用,分别是
Explorer:用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。
Experimentor:用来进行实验,对不同学习方案进行数据测试的环境。
KnowledgeFlow:功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。
SimpleCLI:简单的命令行界面。
下面介绍Explorer功能:
数据集选择UCI数据集,也可以用weka中data目录下自带的数据集!!!!
http://archive.ics.uci.edu/ml/machine-learning-databases/00222/
可以选择blank或者blank-additional解压
以bank-additional-full作为训练数据
bank-additional作为测试数据
点击进入Explorer
这里我们需要把数据集做个调整才能导入成功
1、去掉”
2用”替换掉;
在csv调整成以下格式

加载后:
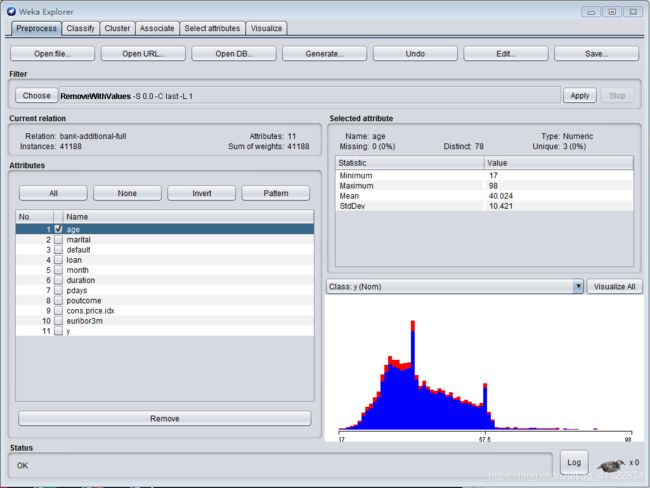
可以在Filters点击choose对数据进行过滤
FIlter功能还是比较强大的,但是Filter分为非监督学习和监督学习两种过滤器,分别属于weka.filters.unsupervised.attribute和weka.filters.unsupervised.attribute,至于监督学习和非监督学习,简单理解就是看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习。这两种方式下的过滤器是不一样的,使用时一定要注意。
非监督学习包下的方法比较多,先讲解一下weka.filters.unsupervised.attribute主要方法的含义:
1.Add
为数据库添加一个新的属性,新的属性将会包含所有缺失值。
2.AddExpression
新增一个属性,该属性由现有属性通过设定的表达式计算得出。支持+, -, *, /, ^, log, abs, cos, exp, sqrt, floor, ceil, rint, tan, sin。现有属性由a+索引值构成。
3.AddNoise
只对名义属性有效,依照一定比例修改值。
4.Center
将数值化属性的平均化为0。
5.ChangeDateFormat
修改数据格式
6.Discretize
简单划分的离散化处理。参数:
7.MathExpression
功能和AddExpression类似,不过支持的运算更多,特别是MAX和MIN的支持特别有用。所有支持运算符如下:+, -, *, /, pow, log,abs, cos, exp, sqrt, tan, sin, ceil, floor, rint, (, ),A,MEAN, MAX, MIN, SD, COUNT, SUM, SUMSQUARED, ifelse
8.Reorder
重新排列属性,输入2-last,1可以让第一项排到最后,如果输入1,3,5的话…其他项就没有了
9.Standardize
这个和Center功能大致相同,多了一个标准化单位变异数
10.StringToNominal
将String型转化为Nominal型
然后再讲一下weka.filters.unsupervised.instance包下的主要方法和含义:
1.NonSparseToSparse
将所有输入转为稀疏格式
2.Normalize
规范化整个实例集
3.RemoveFolds
交叉验证,不支持分层,如果需要的话使用监督学习中的方法
4.RemoveRange
移除制定范围的实例,化为NaN
5.Resample
随机抽样,从现有样本产生新的小样本
6.SubsetByExpression
根据规则进行过滤,支持逻辑运算,向上取值,取绝对值等等
在Attributes选择属性,
决策树算法
WEKA中的“Classify”选项卡中包含了分类(Classification)和回归(Regression),在这两个任务中,都有一个共同的目标属性(输出变量)。可以根据一个样本(WEKA中称作实例)的一组特征(输入变量),对目标进行预测。为了实现这一目的,我们需要有一个训练数据集,这个数据集中每个实例的输入和输出都是已知的。观察训练集中的实例,可以建立起预测的模型。有了这个模型,我们就可以新的输出未知的实例进行预测了
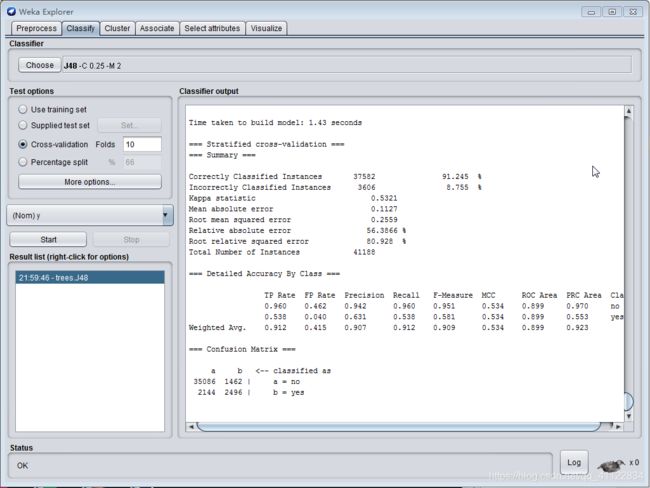
切换到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里“trees”下的“J48”,这就是我们需要的C4.5算法,Cross-validation交叉验证选择10,属性选择y,点击start,右侧有训练参数。
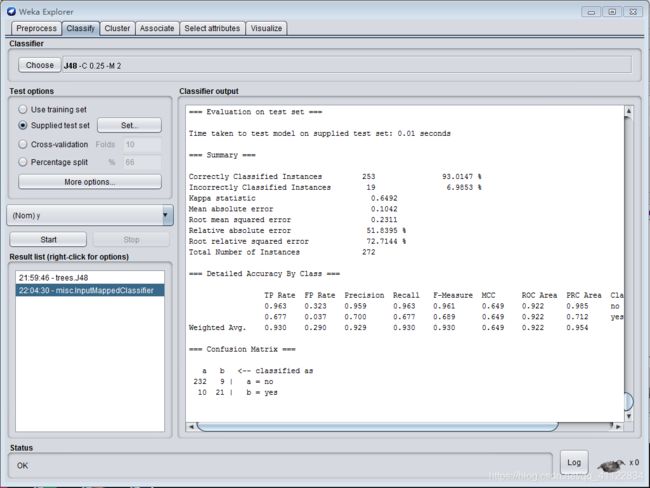
接下来用训练好的模型进行测试。
选择supplied test set选择blank-additional数据集,openfile>close>start
朴素贝叶斯分类器
到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。选择“bayes”下的“NaiveBayes”,这就是我们需要的朴素贝叶斯算法。
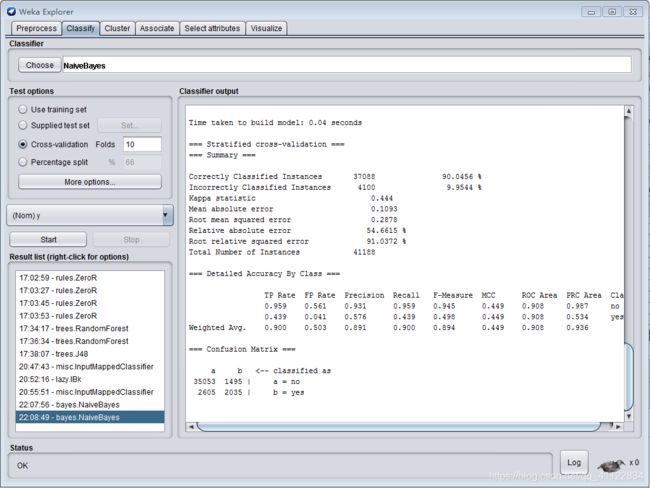
然后就可以根据训练好的模型进行测试。
KNN算法
到“Classify”选项卡,点击“Choose”按钮后可以看到很多分类或者回归的算法分门别类的列在一个树型框里。选择“lazy”下的“IBk”
点击choose文本框可配置参数
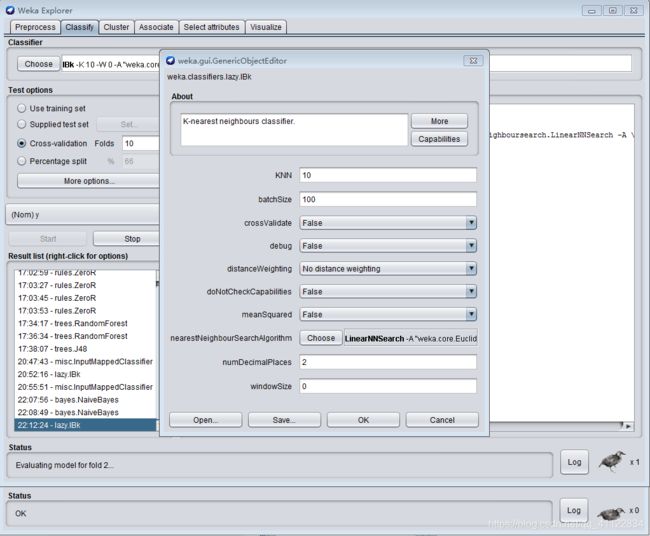
3) 分类和回归
IBk():k最近邻分类
LBR():naive Bayes法分类
J48():C4.5决策树算法(决策树在分析各个属性时,是完全独立的)。
LMT():组合树结构和Logistic回归模型,每个叶子节点是一个Logistic回归模型,准确性比单独的决策树和Logistic回归方法要好。
M5P():M5 模型数算法,组合了树结构和线性回归模型,每个叶子节点是一个线性回归模型,因而可用于连续数据的回归。
DecisionStump():单层决策树算法,常被作为boosting的基本学习器。
SMO():支持向量机分类
AdaBoostM1():Adaboost M1方法。-W参数指定弱学习器的算法。
Bagging():通过从原始数据取样(用替换方法),创建多个模型。
LogitBoost():弱学习器采用了对数回归方法,学习到的是实数值
MultiBoostAB():AdaBoost 方法的改进,可看作AdaBoost 和 “wagging”的组合。
Stacking():用于不同的基本分类器集成的算法。
LinearRegression():建立合适的线性回归模型。
Logistic():建立logistic回归模型。
JRip():一种规则学习方法。
M5Rules():用M5方法产生回归问题的决策规则。
OneR():简单的1-R分类法。
PART():产生PART决策规则。
聚类算法
Cobweb():这是种基于模型方法,它假设每个聚类的模型并发现适合相应模型的数据。不适合对大数据库进行聚类处理。
FarthestFirst():快速的近似的k均值聚类算法
SimpleKMeans():k均值聚类算法
XMeans():改进的k均值法,能自动决定类别数
DBScan():基于密度的聚类方法,它根据对象周围的密度不断增长聚类。它能从含有噪声的空间数据库中发现任意形状的聚类。此方法将一个聚类定义为一组“密度连接”的点集。
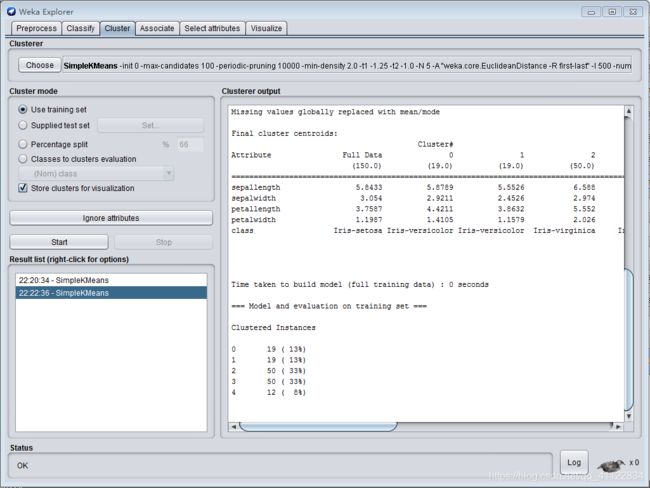
weka提供采用k-means算法聚类的SimpleKMeans,簇的数目由参数指定,用户可以选择使用欧式距离或曼哈顿距离作为距离度量。这里使用weka data自带的iris数据建立起聚类模型,>Preprocess>openfile>Cluster>choose>simepleKMeans>
点击choose文本框配置参数
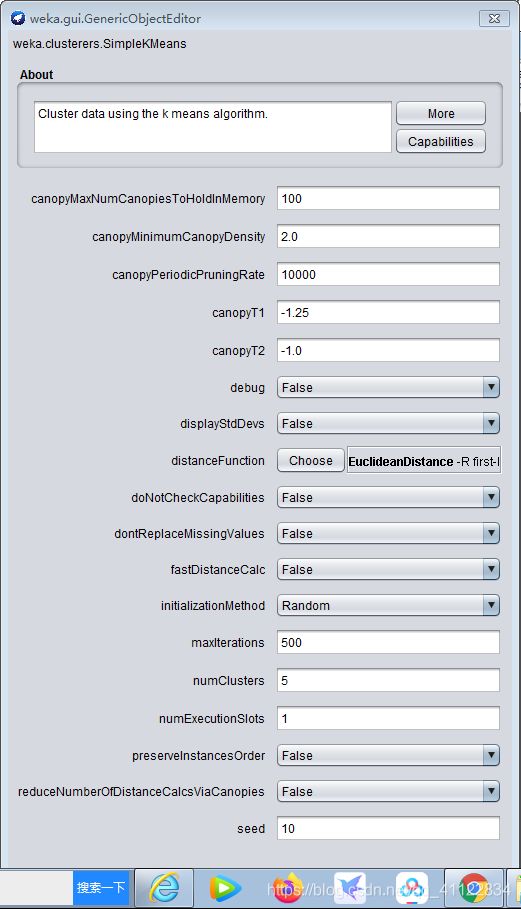
点击start开始训练