context2vec:Learning Generic Context Embedding with Bidirectional LSTM
参考
https://www.aclweb.org/anthology/K16-1006/
https://github.com/tatsuokun/context2vec
https://blog.csdn.net/yang191919/article/details/106141327
论文解读
* 提出了一种无监督模型,借助双向LSTM从大型语料库中有效学习通用句子上下文表征。
* 为了实现具体的目标实例推断,如果能够良好地表征目标单词和对应的句子上下文将对其有很大的帮助。
* 之前,在一些NLP任务上,使用的上下文表示形式通常只是相邻单词在目标单词周围的窗口中的单词嵌入的简单集合,或者是这些词嵌入的(有时候是加权的)平均值(average-of-word-embeddings represtation AWE)。可以看出,**这些方法并没有考虑到任何用于优化整个句子上下整体表示的机制。**
* 使用大型纯文本语料库来学习将整个句子上下文和目标词嵌入到同一低维空间的神经网络模型,该模型经过优化来反映出目标词与其相应的句子上下文之间的依赖性。
* 使用双向LSTM递归神经网络,从左到右方向LSTM提供一个句子序列,从右到左再提供一个序列,这两个网络的参数是完全独立的,包括两组从左到右和从右到左的上下文词嵌入。然后将这两个上下文向量拼接,喂入到多层感知机,以表示两侧上下文之间的非平凡依赖关系。
* 为了学习网络的参数,使用Word2Vec中提到的负采样目标函数,即一个正对是目标单词和整个句子上下文,而相应的k个负对(区别:不同的目标单词,相同的句子上下文)作为随机目标单词,是从词汇表上(平滑的)单词组合分布中采样的,并与相同的上下文配对。这样,我们既可以学习上下文嵌入网络参数,也可以学习目标词嵌入。
* 与Word2Vec和其他类似的词嵌入模型主要在内部使用上下文建模并将目标词嵌入作为其主要的输出相反,该文的主要重点是学习上下文表示。这样,将通过为句子上下文及其关联的目标词分配相似的嵌入表示来实现目标。这与Word2Vec类似,间接地将相似的词嵌入分配给相似的句子上下文相关联的目标单词,反之则分配给与相似的目标单词相关联的句子上下文。
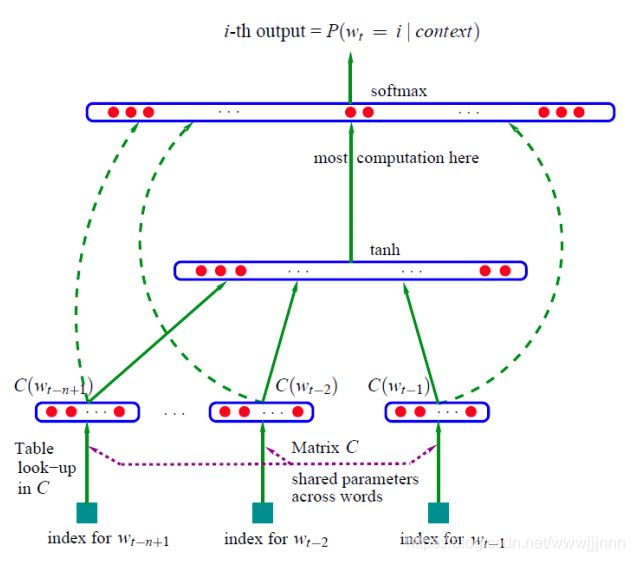

* 上图是Word2Vec和Context2Vec的结构图,后者类似前者,但是在Word2Vec中的CBOW架构中,使用AWE处理上下文 Embedding,而Context2Vec则是把上下文的词 Embedding输入到双向的LSTM,左侧蓝色的是正向的Embedding和右侧绿色的反向 Embedding分别经过LSTM的流转,最后进行拼接输入到多层感知机,产生红色的包含上下文信息的上下文 Embedding,最后,再经目标函数去整体训练参数。
* 通过LSTM的长时记忆能力,Context2Vec可以捕捉到离目标词更远的上下文信息,同时将序列之间的联系引入到模型中,并且通过多层感知机,又将左右两边的序列信息很好地结合在一起,成为真正的包含上下文语义信息的上下文 Embedding.
* 我们就可以联想到,建模最可能出现的文本序列,不就是语言模型的功能吗。论文中也提到,由于context2vec 利用文本上下文的机制,context2vec 和语言模型的关系是非常紧密的,比如它们都是通过上下文和目标词来训练模型,从而捕捉每个词和周围词的联系。主要区别在于语言模型着眼于优化通过上下文来预测目标词的条件概率,而context2vec是想找出一个有效的向量表达来刻画目标词和整个上下文的关系,所以这篇文章可以认为是传统词嵌入和预训练语言模型的一条纽带。最后,文章又在完形填空,词义消岐等任务上评测了一下context2vec的效果,都能达到或超过state-of-the-art的水平。
代码解析
### nets.py ###
import math
import torch
import torch.nn as nn
from src.core.loss_func import NegativeSampling
class Context2vec(nn.Module):
def __init__(self, vocab_size, counter, word_embed_size, hidden_size, n_layers, bidirectional, use_mlp, dropout,
pad_index, device, inference):
super(Context2vec, self).__init__()
self.vocab_size = vocab_size
self.word_embed_size = word_embed_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.use_mlp = use_mlp
self.device = device
self.inference = inference
self.rnn_output_size = hidden_size
self.drop = nn.Dropout(dropout)
# 方向:左到右
self.l2r_emb = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=word_embed_size,
padding_idx=pad_index)
self.l2r_rnn = nn.LSTM(input_size=word_embed_size,
hidden_size=hidden_size,
num_layers=n_layers,
batch_first=True)
# 方向:右到左
self.r2l_emb = nn.Embedding(num_embeddings=vocab_size,
embedding_dim=word_embed_size,
padding_idx=pad_index)
self.r2l_rnn = nn.LSTM(input_size=word_embed_size,
hidden_size=hidden_size,
num_layers=n_layers,
batch_first=True)
# 负采样 counter:词典中的词对应的频数(注:pad/unk/sos/eos对应为0) | hidden_size:600 | 采样数目:10 | 平滑因子alpha:0.75
self.criterion = NegativeSampling(embed_size=hidden_size, counter=counter, n_negatives=10, power=0.75,
device=device, ignore_index=pad_index)
# 多层感知机
if use_mlp:
self.MLP = MLP(input_size=hidden_size * 2,
mid_size=hidden_size * 2,
output_size=hidden_size,
dropout=dropout)
else:
# nn.Parameter:将一个固定不可训练的tensor转换成可以训练的类型parameter,
# 让某些变量在学习的过程中不断的修改其值以达到最优化.
self.weights = nn.Parameter(torch.zeros(2, hidden_size))
self.gamma = nn.Parameter(torch.ones(1))
# 初始化权重
self.init_weights()
def init_weights(self):
# BERT 中计算注意力矩阵,出现过乘以math.sqrt(1. / 维度大小)
std = math.sqrt(1. / self.word_embed_size)
self.r2l_emb.weight.data.normal_(0, std)
self.l2r_emb.weight.data.normal_(0, std)
def forward(self, sentences, target, target_pos=None):
batch_size, seq_len = sentences.size()
# input: a b c
# reversed_sentences: c b a
# sentences: a b c
# numpy.flip(1) 沿给定轴反转数组中元素的顺序.
reversed_sentences = sentences.flip(1)[:, :-1]
sentences = sentences[:, :-1]
l2r_emb = self.l2r_emb(sentences)
r2l_emb = self.r2l_emb(reversed_sentences)
output_l2r, _ = self.l2r_rnn(l2r_emb)
output_r2l, _ = self.r2l_rnn(r2l_emb)
# output_l2r: h() h(a) h(b) h(c) --> h() h(a) h(b)
# output_r2l: h() h(c) h(b) h(a) --> h(b) h(c) h()
output_l2r = output_l2r[:, :-1, :]
output_r2l = output_r2l[:, :-1, :].flip(1)
if self.inference:
# user_input: I like [] .
# target_pos: 2 (starts from zero) 即 [] 在user_input中的索引.
# output_l2r: h() h(I) h(like) h([])
# output_r2l: h(like) h([]) h(.) h()
# output_l2r[target_pos]: h(like) 即 output_l2r[2]: h(like)
# output_r2l[target_pos]: h(.) 即 output_l2r[2]: h(.)
if self.use_mlp:
# output_l2r[0, target_pos]: h() h(I) h(like)
output_l2r = output_l2r[0, target_pos]
# output_r2l[0, target_pos]: h(like) h([]) h(.)
output_r2l = output_r2l[0, target_pos]
# 注意:左到右序列(上文)一定是到target_pos前一个单词, 右到左序列(下文)一定是target_pos前一个单词到结束单词.
# 两个序列长度可能存在不同的情况.
# 根据第0个维度进行拼接, 保持第1和第2维度一致, 此处是为了推断出目标词.
c_i = self.MLP(torch.cat((output_l2r, output_r2l), dim=0))
else:
raise NotImplementedError
return c_i
else:
# on a training phase
if self.use_mlp:
# 根据第2个维度进行拼接, 保持第0和第1维度一致. (batch_size, seq_length, hidden_size*2)
c_i = self.MLP(torch.cat((output_l2r, output_r2l), dim=2))
else:
s_task = torch.nn.functional.softmax(self.weights, dim=0)
c_i = torch.stack((output_l2r, output_r2l), dim=2) * s_task
c_i = self.gamma * c_i.sum(2)
# target: (batch_size, seq_len)
# c_i: (batch_size, seq_len, hidden_size*2)
loss = self.criterion(target, c_i)
return loss
def init_hidden(self, batch_size):
weight = next(self.parameters())
return (weight.new_zeros(self.n_layers, batch_size, self.hidden_size),
weight.new_zeros(self.n_layers, batch_size, self.hidden_size))
def run_inference(self, input_tokens, target, target_pos, k=10):
context_vector = self.forward(input_tokens, target=None, target_pos=target_pos)
if target is None:
topv, topi = ((self.criterion.W.weight * context_vector).sum(dim=1)).data.topk(k)
return topv, topi
else:
context_vector /= torch.norm(context_vector, p=2)
target_vector = self.criterion.W.weight[target]
target_vector /= torch.norm(target_vector, p=2)
similarity = (target_vector * context_vector).sum()
return similarity.item()
def norm_embedding_weight(self, embedding_module):
embedding_module.weight.data /= torch.norm(embedding_module.weight.data, p=2, dim=1, keepdim=True)
# replace NaN with zero
embedding_module.weight.data[embedding_module.weight.data != embedding_module.weight.data] = 0
class MLP(nn.Module):
def __init__(self, input_size, mid_size, output_size, n_layers=2, dropout=0.3, activation_function='relu'):
super(MLP, self).__init__()
self.input_size = input_size
self.mid_size = mid_size
self.output_size = output_size
self.n_layers = n_layers
self.drop = nn.Dropout(dropout)
self.MLP = nn.ModuleList()
if n_layers == 1:
self.MLP.append(nn.Linear(input_size, output_size))
else:
# 输入层
self.MLP.append(nn.Linear(input_size, mid_size))
# 隐藏层
for _ in range(n_layers - 2):
self.MLP.append(nn.Linear(mid_size, mid_size))
# 输出层
self.MLP.append(nn.Linear(mid_size, output_size))
if activation_function == 'tanh':
self.activation_function = nn.Tanh()
elif activation_function == 'relu':
self.activation_function = nn.ReLU()
else:
raise NotImplementedError
def forward(self, x):
out = x
for i in range(self.n_layers - 1):
out = self.MLP[i](self.drop(out))
out = self.activation_function(out)
return self.MLP[-1](self.drop(out))
### loss_func.py ###
import torch
import torch.nn as nn
import numpy as np
class NegativeSampling(nn.Module):
"""
负采样 embed_size: 600 | n_negatives: 10 | power: 0.75
power 主要是为了实现平滑效果, 其中, power越大对稀有词就存在更大的偏见.
"""
def __init__(self, embed_size, counter, n_negatives, power, device, ignore_index):
super(NegativeSampling, self).__init__()
self.counter = counter
self.n_negatives = n_negatives
self.power = power
self.device = device
# len(counter): vocab_size
self.W = nn.Embedding(num_embeddings=len(counter), embedding_dim=embed_size, padding_idx=ignore_index)
# 权重全设置为0
self.W.weight.data.zero_()
self.logsigmoid = nn.LogSigmoid()
# np.power 对 频数counter 进行 power (0,1) 倍数的计算, 得到的是浮点list.
self.sampler = WalkerAlias(np.power(counter, power))
def negative_sampling(self, shape):
if self.n_negatives > 0:
# 按照概率值进行采样
return torch.tensor(self.sampler.sample(shape=shape), dtype=torch.long, device=self.device)
else:
raise NotImplementedError
def forward(self, sentence, context):
# sentence: (batch_size, seq_len)
# context: (batch_size, seq_len, hidden_size)
batch_size, seq_len = sentence.size()
# emb: (batch_size, seq_len, hidden_size)
emb = self.W(sentence)
pos_loss = self.logsigmoid((emb * context).sum(2))
# neg_samples: (batch_size, seq_len, self.n_negatives)
neg_samples = self.negative_sampling(shape=(batch_size, seq_len, self.n_negatives))
# neg_emb: (batch_size, seq_len, self.n_negatives, hidden_size)
neg_emb = self.W(neg_samples)
# context.unsqueeze(2): 增加一个维度, 相乘实现广播机制.
neg_loss = self.logsigmoid((-neg_emb * context.unsqueeze(2)).sum(3)).sum(2)
return -(pos_loss + neg_loss).sum()
class WalkerAlias(object):
"""
This is from Chainer's implementation.
You can find the original code at
https://github.com/chainer/chainer/blob/v4.4.0/chainer/utils/walker_alias.py
This class is
Copyright (c) 2015 Preferred Infrastructure, Inc.
Copyright (c) 2015 Preferred Networks, Inc.
"""
def __init__(self, probs):
prob = np.array(probs, np.float32)
# 归一化.
prob /= np.sum(prob)
# 词典大小.
threshold = np.ndarray(len(probs), np.float32)
# 大小为两倍的词典大小.
# 每列中最多只放两个事件的思想.
values = np.ndarray(len(probs) * 2, np.int32)
# 双指针思想.
il, ir = 0, 0
# i.g. [(0, 0), (0, 1), (0, 2), (0, 3), (0.001, 4), ...].
pairs = list(zip(prob, range(len(probs))))
# 按照prob的值从小到大排序 注意该点很重要,方便后面的回填,避免出现bug.
pairs.sort()
for prob, i in pairs:
# 按照其均值归一化, (除以1/N, 即乘以N).
p = prob * len(probs)
# p>1, 说明当前列需要被截断.
# 回填的思想, 如果当前的概率值大于均值的话, 就将遍历之前的ir到il之间没有填满的坑.
# 主要是为了构造一个1*N的矩阵.
while p > 1 and ir < il:
# 为了填充没有满的那一列ir, 并且将索引保存到奇数列.
values[ir * 2 + 1] = i
# 本列一共减少了(1-threshold[ir])的概率值.
p -= 1.0 - threshold[ir]
# ir位置的坑已经被填满,故ir+=1.
ir += 1
# 概率值*词典大小.
threshold[il] = p
# 保存单词的索引, 偶数列.
values[il * 2] = i
il += 1
# fill the rest
for i in range(ir, len(probs)):
values[i * 2 + 1] = 0
assert ((values < len(threshold)).all())
self.threshold = threshold
self.values = values
def sample(self, shape):
"""
采样
"""
# 从均匀分布中抽取样本.
ps = np.random.uniform(0, 1, shape)
# 均值归一化, (除以1/N, 即乘以N).
pb = ps * len(self.threshold)
# 转化为int类型, 可以认为index对应着词典中某个词的索引.
index = pb.astype(np.int32)
# 选择是奇数列还是偶数列, 注意, (pb - index) 返回的是0-1之间的数组, 巧妙!!!
left_right = (self.threshold[index] < pb - index).astype(np.int32)
return self.values[index * 2 + left_right]
收获总结
* 负采样很有意思,争取应用起来。
如有错误,欢迎指正!