有道词典的爬虫--POST方法提交数据的练习
目的:实现有道翻译的爬虫,输入需要翻译的内容,返回翻译的结果
访问的网址:http://fanyi.youdao.com/
难点:
- salt(盐)的生成,在js源代码中查看
- sign(签名)的生成,其加密方式的分析
- 访问的url不是有道翻译的网址,而是头部里的Request URL, 且访问的时候需要删除’_o’
POST方式爬虫分析:
-
需要解析Ajax的API接口,查看请求头部Request Headers和参数的Form data,并将请求头部和参数写入代码中,不需要全部写入
-
查询不同的单词的时候,Form data中的salt和sign不断发生变化,需研究salt和sign的生成规律
-
破解js加密,这里的js文件需要在线代码格式化工具(https://tool.oschina.net/codeformat/js)进行格式化,更方便我们查看代码,发现:salt: i,而 i = r + parseInt(10 * Math.random(), 10);
r = “” + (new Date).getTime()
加密方式:sign: n.md5(“fanyideskweb” + e + i +“Nw(nmmbP%A-r6U3EUn]Aj”)
sign是经过md5加密生成的,其中"fanyideskweb"和"Nw(nmmbP%A-r6U3EUn]Aj"为确定字符串, e为查询的单词, i为salt -
编写get_salt生成函数,get_md5加密函数,get_sign生成函数,youdao函数
补充
表达式:parseInt(string,radio);string为将要转换的字符串,radio为转换的基数。
在生成salt需要用到:
parseInt("010",10)就是10进制的结果:10
parseInt("010",2)就是2进制的结果:2
parseInt("010",8)就是8进制的结果:8
parseInt("010",16)就是2进制的结果:16
(new Date).getTime() 获取时间戳*1000
分析过程
- 访问网址,审查元素,查看源代码,点击network,选择XHR,然后再刷新页面
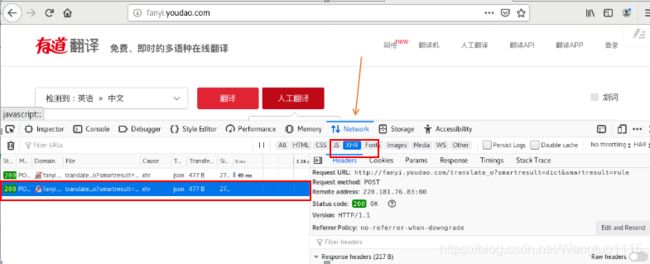 2. 查看请求的url,不是我们访问的网址,查看请求头部,这些信息是我们需要往代码中填写的
2. 查看请求的url,不是我们访问的网址,查看请求头部,这些信息是我们需要往代码中填写的
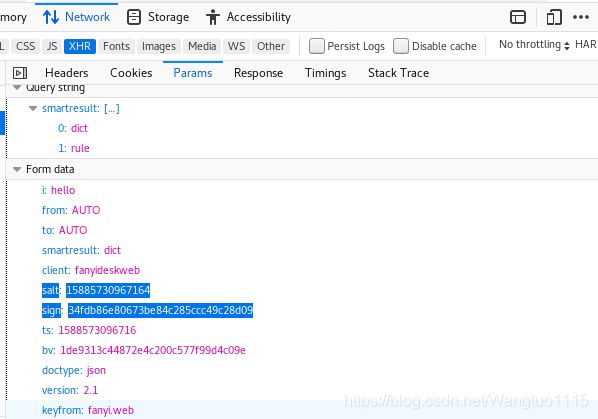
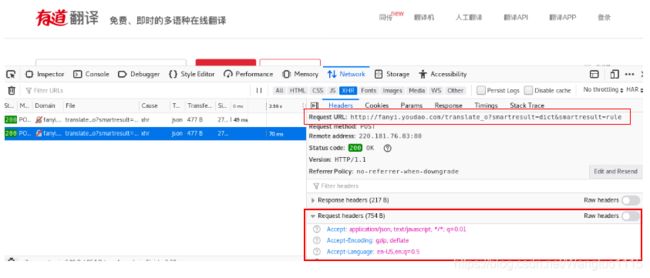 Params里面的内容也是我们需要的:
Params里面的内容也是我们需要的:
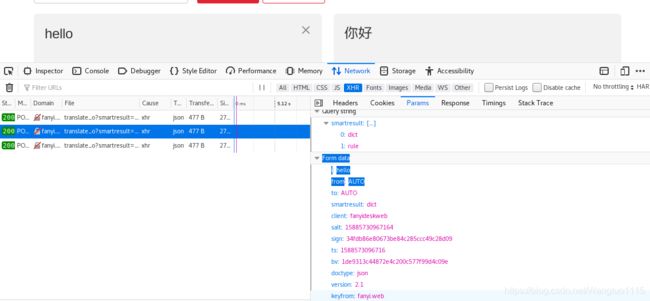 然后我们就可以编写代码爬取翻译的结果了:
然后我们就可以编写代码爬取翻译的结果了:
翻译结果在如下的位置:
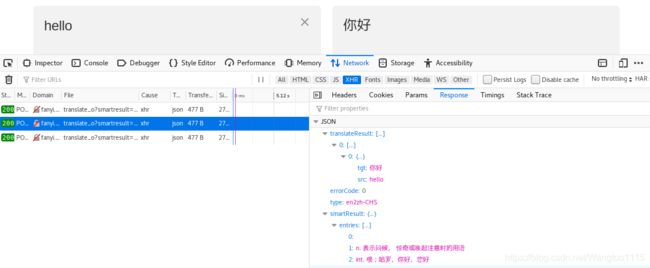
这样编写的代码只能爬取到我们上面输入的那一个单词的意思(hello),当我们想查询其他单词的意思时:发现代码并不能运行成功。通过输入不同的单词发现,是data里的salt和sign不断发生变化,所以我们只要解决了salt和sign的生成就能实现翻译我们需要翻译的单词了。
然后我们通过查看js文件,查看salt和sign 的生成方式:
如何js文件的位置?点击XHR左边的JS,发现左侧出现了js文件,我们点击这个文件。
 这里的js文件不能直接查看,需要进行格式化:
这里的js文件不能直接查看,需要进行格式化:
代码格式化工具:https://tool.oschina.net/codeformat/js
将格式化的js文件保存起来,搜索salt:
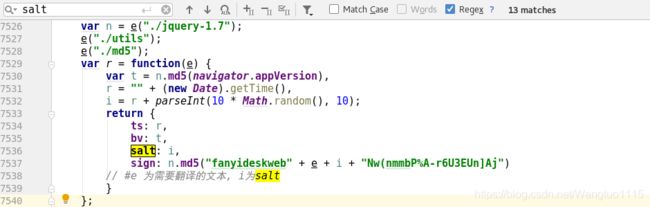 我们发现,salt的生成方式和sign的加密方式。
我们发现,salt的生成方式和sign的加密方式。
经过分析,我们发现salt是:i = r + parseInt(10 * Math.random(), 10);
r = “” + (new Date).getTime() 通过这种方式生成的,
其中:parseInt(string,radio);string为将要转换的字符串,radio为转换的基数。例如:parseInt(“010”,10)就是10进制的结果:10;(new Date).getTime() 获取时间戳*1000 这样我们就解决了salt的生成问题。
然后发现sign是经过md5加密生成的:sign: n.md5(“fanyideskweb” + e + i + “Nw(nmmbP%A-r6U3EUn]Aj”),其中"fanyideskweb"和"Nw(nmmbP%A-r6U3EUn]Aj"为确定字符串, e为查询的单词, i为salt,这样sign的生成也就解决了。
最后是分别编写get_salt生成函数,get_md5加密函数,get_sign生成函数,youdao函数,实现爬虫。
代码如下:
from urllib.error import HTTPError
import requests
from colorama import Fore
def get_salt():
import time,random
salt = int(time.time()*1000) + random.randint(0, 10)
return salt
def get_md5(value):
import hashlib
# 创建md5对象
md5_obj = hashlib.md5()
# 加密字符串, update需要bytes格式参数
md5_obj.update(value.encode('utf-8'))
# 获得加密后的字符串
value = md5_obj.hexdigest()
return value
def get_sign(salt, keyword):
sign = "fanyideskweb" + keyword + str(salt) + "Nw(nmmbP%A-r6U3EUn]Aj"
sign = get_md5(sign)
return sign
def youdao(keyword):
"""翻译单词"""
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data = {
'i': keyword,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': salt,
'sign': sign,
'ts': '1587643063646',
'bv': '1de9313c44872e4c200c577f99d4c09e',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_CLICKBUTTION',
'typoResult': "false"
}
# 数据编码
# data = parse.urlencode(data).encode()
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:45.0) Gecko/20100101 Firefox/45.0',
'Cookie': 'OUTFOX_SEARCH_USER_ID_NCOO=409718278.3062856; OUTFOX_SEARCH_USER_ID="[email protected]"; YOUDAO_MOBILE_ACCESS_TYPE=1; _ntes_nnid=2c6aa484b0d90bcab1a55a76a14205b8,1586516661463; YOUDAO_FANYI_SELECTOR=OFF; DICT_UGC=be3af0da19b5c5e6aa4e17bd8d90b28a|; JSESSIONID=abc8A-eMolzzPe4i-2Kgx; ___rl__test__cookies=1587643063640',
'Referer': 'http://fanyi.youdao.com/',
'Host': 'fanyi.youdao.com',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'en-US,en;q=0.5',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'Content-Length': '242',
'Connection': 'keep-alive',
"Origin": "http://fanyi.youdao.com",
}
try:
response = requests.post(url=url, data=data, headers=headers)
except HTTPError as e:
print(Fore.RED + '[-] 爬取网站%s失败:%s' % (url, e.reason))
return None
else:
# 两种反序列化方式
# translate_result = json.loads(response.content)
translate_result = response.json()
# print(translate_result)
# {'type': 'EN2ZH_CN', 'errorCode': 0, 'elapsedTime': 1, 'translateResult': [[{'src': 'girl', 'tgt': '女孩'}]]}
# 两种方式
# return translate_result['translateResult'][0][0]['tgt']
return translate_result.get('translateResult')[0][0]['tgt']
if __name__ == '__main__':
keyword = input('请输入要查询的单词: ')
salt = get_salt()
sign = get_sign(salt, keyword)
translate_result = youdao(keyword)
print(translate_result)
运行结果如下:
请输入要查询的单词: key
关键