如何使用eclipse开发hadoop程序
说明:
环境说明:服务器端:虚拟机下安装centos6.8, jdk1.7, hadoop2.7.5
客户端:win10,jdk1.7,hadoop2.7.5,eclipseMars.2 Release (4.5.2)
一、安装并配置相关软件
1、下载windows下使用的eclipse 插件hadoop-eclipse-plugin-2.7.2.jar,以及winutils.exe和hadoop.dll。
2、将hadoop解压到某目录,如笔者D:\centos-hadoop-2.7.5。名称前加上centos是因该版本是笔者在centos下自行编译生成的。
3、把hadoop.dll和winutile.exe放到D:\centos-hadoop-2.7.5目录下的bin
4、配置环境变量:
(1)添加变量名:HADOOP_HOME,变量值为hadoop解压后的路径D:\centos-hadoop-2.7.5。
(2)添加变量名:JAVA_HOME,变量值为jdk安装路径C:\Java\jdk1.7.0_75。
(3)变量path属性值里添加:%HADOOP_HOME%\bin;%JAVA_HOME%\bin
5、把hadoop-eclipse-plugin-2.7.3.jar包放到eclipse安装路径的plugins的文件夹里,并重启eclipse
6、运行eclipse,打开菜单Window->ShowView->Other,显示如
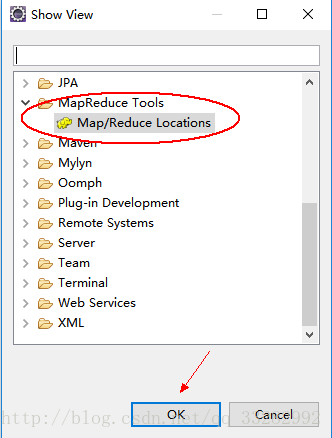
在Map/Reduce Locations中新建一个Hadoop Location。在这个View中,右键-->New Hadoop Location。在弹出的对话框中需要配置Locationname,还有Map/Reduce Master和DFS Master。
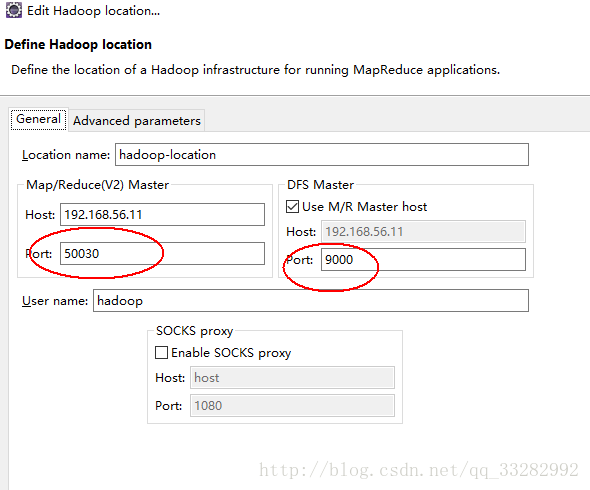
Map/Reduce(V2)Master
Host:为Map/Reduce主节点址(任务追踪器),这里笔者设为所安装的hadoop集群中的master节点的IP地址。
Port:为属性mapreduce.jobtracker.http.address所配置的端口号。此属性一般采用系统mapred-default.xml配置文件中的值“0.0.0.0:50030”,则端口为50030。
(注:笔者曾用50020、8030等其它端口号,程序也能正常运行。网上也有人认为应为hdfs-site.xml中dfs.datanode.ipc.address指定的的端口号50020,到现不知其原因,请指点)
DFS Master
Host:为分布式系统名称节点namenode主机IP。
Port:为core-site.xml中fs.defaultFS指定的端口。笔者机器配置如下,即为9000。
查看hadoop系统相关配置属性值,可用浏览器访问http://master:8088并点击Tools --> Configuration 进行查找。
UserName:hadoop集群上跑hadoop应用的用户名称。

8:在浏览器里查看的那些文件都能在eclipse的左边的DFSLocations里展示出来啦~
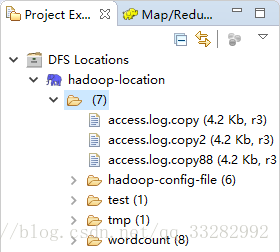
到此,环境配置完毕。
二、开发wordcount小程序
1、在eclipse中新建java project。
2、添加引用hadoop库文件。

库文件位于%HADOOP_HOME%\share\hadoop目录下,根据应用程序的需要添加。
本wordcount程序需要添加的是common、hdfs、yarn目录下的jar文件及子目录lib中的所有jar文件。
3、编写源代码(本源代码来自网络,如侵权请告知删除)
WordcountMapper.java
package cn.htkc.bigdata.mr.wcdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extendsMapper
@Override
protectedvoid map(LongWritable key, Text value, Context context) throws IOException,InterruptedException {
Stringline = value.toString();
String[]words = line.split(" ");
for(Stringword:words){
context.write(newText(word), new IntWritable(1));
}
}
}
WordcountReducer.java
package cn.htkc.bigdata.mr.wcdemo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extendsReducer
@Override
protectedvoid reduce(Text key, Iterable
int count=0;
for(IntWritablevalue:values){
count+= value.get();
}
context.write(key,new IntWritable(count));
}
}
WordcountDriver.java
package cn.htkc.bigdata.mr.wcdemo;
importorg.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
publicstatic void main(String[] args) throws Exception {
Configurationconf = new Configuration();
Jobjob = Job.getInstance(conf);
job.setJarByClass(WordcountDriver.class);
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
booleanres = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
三、运行程序
1、 本地运行
编写完相关代码后,配置输入输出参数,文件路径中的分隔符记得改为“/”。
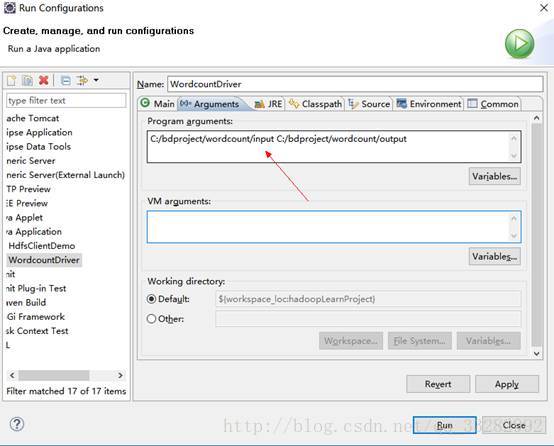
运行结果显示:
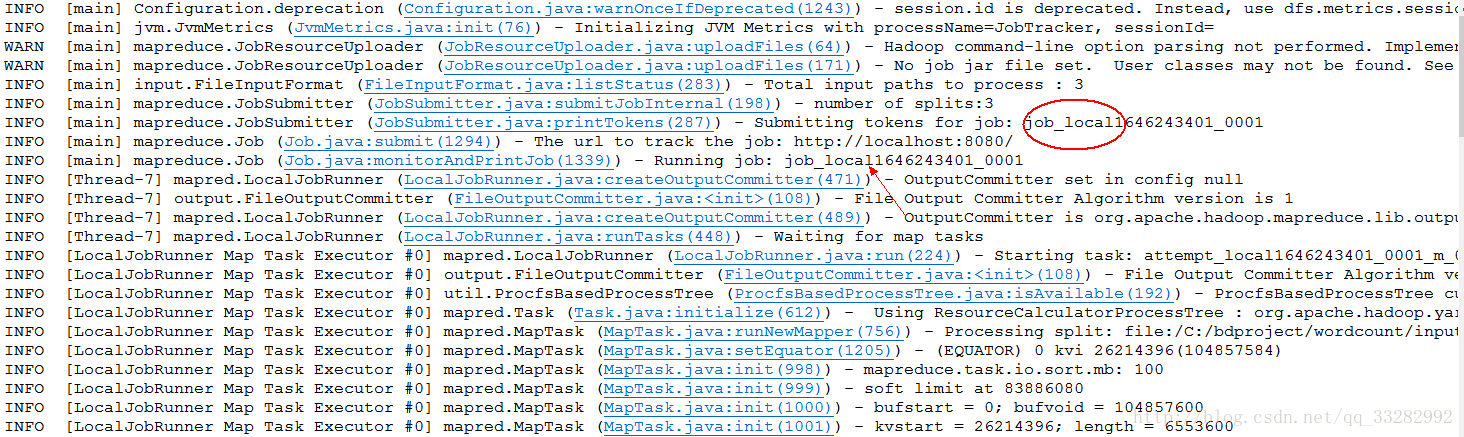
该程序的数据处理工作、数据的输入输出都基于本地进行的。
当然数据的输入输出也可放在hdfs系统上,只需要将上图中”program arguments”的参数改为hdfs://master:9000/wordcount/input/ hdfs://master:9000/wordcount/output/则可以了。
2、 远程服务器运行
2.1 将应用程序打包生成jar文件,并上传到centos服务器上。运行:
[hadoop@master~]$ hadoop jar wordcount.jar cn.htkc.bigdata.mr.wcdemo.WordcountDriver/wordcount/input /wordcount/output
程序将正常运行并输出结果