OCR之数据来源
最近一直在收集ocr相关的资料,正好看到某公众号上一篇介绍OCR数据来源的三种方式, 为了以后方便阅读, 直接将文章照搬过来. 感兴趣的读者可以参考连接
背景介绍
如果把深度学习看做引擎,大量带标注的数据则是燃料,燃料的体量和质量直接影响引擎的动力。随着计算能力大幅增强,深度学习模型已向wide & deep的方向越走越远,更大更深的模型需要更多的数据训练。这一点从近年来学术界与工业界竞相公开的数据集规模上可见一斑。以经典的计算机视觉任务为例,如fig.1所示,公开数据集的量级几乎呈指数上升趋势。体量越来越大的数据集同时也包含着越来越丰富的标签信息,正是这些庞大而丰富的信息使得深度模型得以充分的训练,从而能完成各种机器视觉,语义理解,行为预测等任务。

OCR数据
如图fig.2所示,OCR的作用是检测图像中的文字区域以及识别文字内容。我们的OCR算法当前主要应用于广告图片,不仅助力广告审核,更重要的是提取广告素材图片中的语义特征以求更精准的推荐。除了广告领域,还有内容相关的网络图像,游戏图像,以及各类卡证图像的识别。
相比物体检测识别,OCR由于包含倾斜文本框,低分辨率文字,以及文本版面多样化,因此OCR数据标注具有特殊性,标注成本更高。如此情况决定了很难通过用户反馈获得待标注样本来支撑OCR深度模型训练。因此,除了在具体业务场景中必不可少的人工数据标注,训练样本还需要通过机器生成来获取。
在这里插入图片描述
数据集生成
对基于深度学习的技术而言,训练数据的数量很大程度上影响了技术效果。公司的业务图片中包含大量中文汉字文本行,中英文数字混合的情况,几乎没有这样大规模可用的文字检测识别数据集,由于获取大量带标注训练数据成本高,易扩展且速度快的数据机器生成便成为首选。在计算机视觉领域,数据机器生成主要可粗略的分为三种类型:底层的图像处理技术,中间层的图像理解加人为规则,以及高层的端到端图像数据生成,OCR技术的数据生成同样遵循这三类。
图像处理数据增强
基于图像处理进行数据增强这种训练数据生成的方式是门槛最低也应用最为广泛的方法。最常用的图像处理方式包含如fig.3所示,翻转,平移,旋转,加噪声,模糊,等几十种基础操作,每张样本可通过组合这些操作生成出众多新样本。在OCR领域,除了上述的基础图像处理技术,书写文字的属性及背景图片也可以极大的多样化。使用的背景图片来自于多种业务场景;在字体选取上使用几百种中英文字体;在语料库的选择上,在现有广告语料基础上,构建了近千万词条的新语料库。生成的样本最大化接近真实广告图片,生成样本数千万,使得模型具备强大的识别能力和泛化性能。

基于图像分割&景深
由于直接将文字写在背景图片上这种策略并不考虑背景变化,在很多背景复杂的情况下,生成的样本显得不真实,且部分样本人眼也无法判断文字内容。这些样本的存在有极大的可能给模型检测识别能力带来副作用,于是对背景图片进行分析理解,选取趋近一致的背景进行文字书写,并且根据图片景深信息,将文字书写平面与图片中物体表面进行拟合,让文字贴合物体表面,获得更加真实的视觉效果。
(绿色文本框标识文本行位置,黑色文字代表文本框内文字内容,图像来源)
在fig.4中,第一行为背景图片处理流程,第二列为生成样本示例。图片经过景深检测,图像分割以及文字区域筛选。在书写文本行的过程中,文字书写的平面会依据物体表面,以模拟出更真实的图片样本。在fig.5中可以看到图片中生成的文字不仅每个文本行带有标注框,每个字的位置也有文本框明确的标注。

基于上述图像分割和图像景深的技术,在广告图片上生成了大量的带标注样本供文本检测模型训练。如fig.6所示,样本中的文字与图片大小比例,文本行倾斜角度,文字颜色与背景颜色的映射关系,文字间隔等细节特征也通过统计广告图片获得。在使生成样本更加趋近真实的样本的基础上,我们还从文字透明度,斜体方面增加了生成样本的多样性,从而获得更加鲁棒的文字检测及端到端检测识别的能力。
对于大部分网络图片(广告图片,信息流文章图片,游戏图片等),由于业务中的样本本身也由计算机生成,属于生成数字图片(Born-Digital Images)识别,因此生成的样本可以模拟到非常逼真。
但是在部分业务场景里,待识别的图片来自于真实拍摄,属于自然场景文字识别STR(Scene Text Recognition),STR在计算机视觉领域是经典且热门的技术,但是,STR在公开数据集的数量方面一直没有突破,一些研究尝试使用基于类似生成网络图片的方式生成自然场景样本,却始终没有取得显著的效果。
生成对抗网络
在自然场景中,文字通常不但不像网络图片具有显著性,还经常伴随着模糊,反光等情况,给文字检测识别带来极大的困难。以银行卡号识别场景为例,阴影,反光,角度,背景均给识别带来很大的困难,然而这些并不是最核心的问题,核心问题是银行卡图片属于个人隐私,获取大量真实银行卡图片样本几乎不可能。那么,如何满足模型训练却必须有样式丰富、数量庞大的样本集需求呢?我们需要更多从算法角度出发,寻找突破口。
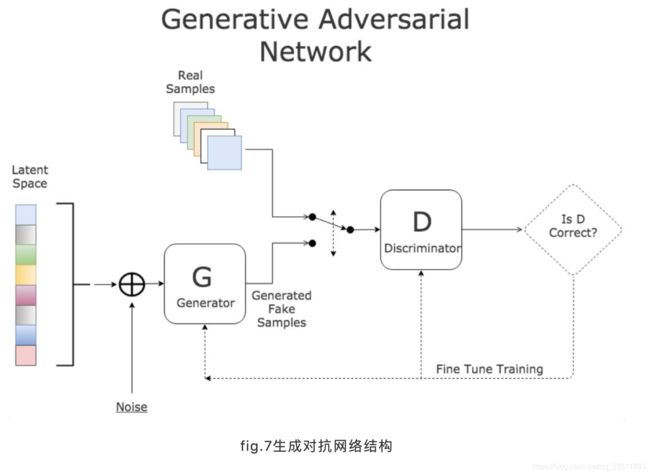
自从2014年底Ian Goodfellow 提出生成对抗模型(GANs)以来,业界涌现出大量GANs应用在各个任务上的工作,其中包含了一些数据生成的成果。GANs思想如fig.7所示,生成网络负责生成图像,判别网络负责预测输入图片是否真实,随着生成网络G与判别网络D的交替式对抗学习,生成网络逐渐能够生成以假乱真的图像。
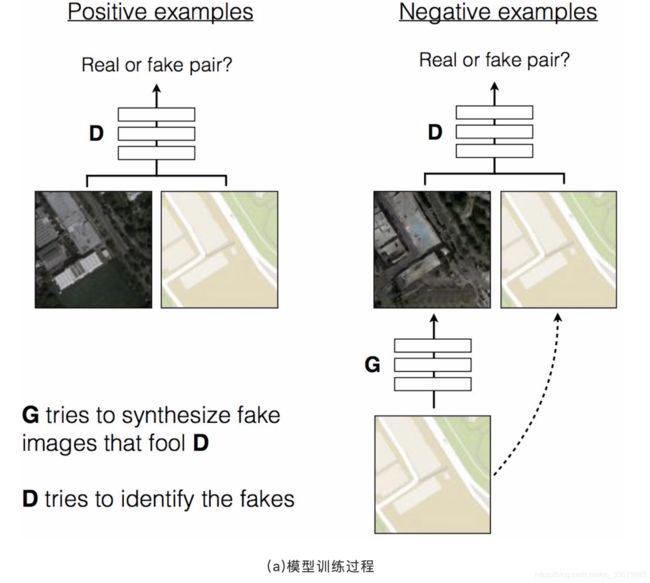

在一系列生成对抗网络的成果中,我们发现基于对抗学习的图片风格转化更符合我们的场景,如fig.8所示,pix2pix中,判别器D学习区分真实样本和生成样本;生成器G学习生成更真实的样本以求让D无法识别,其中生成器网络结构可选择是否带有跳跃连接。在这个基础上,可以将人工生成出的白底黑字的号码转化为银行卡号的风格,用以增加训练样本。如fig.9所示,左边为真实的银行卡样本图片,右边为对应卡号的模版。我们期望利用训练好的生成对抗网络将随机的卡号转化为银行卡风格的样本,如此以来我们便可以获得大量带标注的银行卡样本用以训练文字识别模型。

fig.10为我们使用的生成对抗模型,不同于常规的图片生成任务,卡号图片为长条形(长是宽的10倍以上),为了保证生成的图片整体风格一致,我们调整网络结构,让网络感受野足够看到大部分图片,从而保障生成的图片整体风格保持一致。另外再通过drop out来控制随机性,使同一个号码模版可以生成出几百种不同的风格。

Fig.11中的图片通过GANs生成, 可以看到尽管图片还有少量瑕疵(最下图),但绝大多数图片已经可以达到以假乱真的程度。我们依照银行卡号数字编码规范,可以很快生成几十万数字模版,再通过GANs将这些模版转换为银行卡号风格,伴随推理过程中的随机性,我们可以在一天内产出百万量级的生成样本提供给识别模型训练。
在这里插入图片描述](https://img-blog.csdnimg.cn/20200330105751941.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMzNTExNjkz,size_16,color_FFFFFF,t_70)
小结
通过上述的数据生成技术,我们在网络图片,自然场景图片,以及特定业务场景(银行卡,身份证…)的OCR检测与识别效果有明显提升。尤其是网络图片,由于生成样本逼真,数量多,足够多样化,能够通过算法bad case反馈迅速反应,生成针对性的样本,使得OCR能力快速提升。