Pandas数据分析——从0.3到0.8学习指南
注:本文是学习+整理的笔记 学习资料及学习团队组织均为DataWhale提供
目录
一、基础部分
筛选数据
Series数据结构
DataFrame数据结构
apply函数
索引
分组
变形
合并
一、基础部分
import pandas as pd
import numpy as np
设置行列最大数
pd.set_option('max_column',8,'max_rows',10)文件读取:pd.read_csv
DataFrame组件访问:data.colunms data.index data.values
type查看数据类型或行列属性;data.['属性名']亦可
调用Series方法pd.Series
最大显示行数:pd.set_option('max_rows',8)
属性值出现次数:columns.value_counts()
属性值中位分位数:columns.quantile()
data.min(skipna=False) 参数说明:只计算非缺失值列 .max() .mean() .median() .std() .sum() 分别查看最小值、最大值、平均值、中位数、标准差、总和
data.isnull()查看空值 .isnull().mean()查看空值比例 属性.fillna(0)填补空值 属性.dropna()删除空值
data.value_counts(normalize=True) 查看每个值出现的频率
data.hasnans 判断是否有缺失值 属性.notnull()判断是否为非缺失值
data可直接进行四则运算+ - * /
.add()加法 .mul()乘法 .floordiv()底除 .gt()筛选大于 .eq()筛选等于 .mod取模长
括号串联筛选示例:(data.fillna(0).astype(int).head())
增加列名:data['列名']=0 注:也可使用insert()方法直接插入列与值
data.all()检查是否所有布尔值都为ture
筛选数据
筛选多列:data[['a','b']] 或者
pd.DataFrame(data,columns=['Height','Weight'])筛选特定数据列:data.select_dtypes(include=['输入要筛选的数据类型']).head()
.ndim() 查看数据维度
Series数据结构
创建Series列
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='这是一个Series',dtype='float64')Series常见属性有index(索引),name(名字),dtype(类型)
s.values s.index s.dtype查看对应内容
print([attr for attr in dir(s) if not attr.startswith('_')])查看可调用的方法
DataFrame数据结构
创建DataFrame
df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},
index=list('一二三四五'))df['col1']取出的列为Series

修改行或列名
df.rename(index={'一':'one'},columns={'col1':'new_col1'})replace对某些值进行替换
df['Address'].replace(['street_1','street_2'],['one','two']).head()第一个参数为修改前,第二个参数为修改后
调用属性方法:df.index df.values da.columns df.shape
pandas具有索引对齐特性,即数据间的运算位置由索引确定且相对应
df结构的数据删除:data.drop(index='',columns='') 或del data[' 列名'] 此处注意:设置inplace=True后会直接在原DataFrame中改动
将Series转为DataFrame:data.to_fame()
data.idxmax()返回最大值 ,类似有.idmin data.nlargest(3)返回3个大的元素值,类似有.nsmallest
data.clip(a,b)大于a小于b
apply函数
1.可实现对某一列中的每一个值同时进行操作
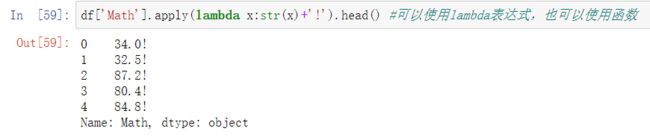
2.可实现同时对每一列的每一个数据进行操作
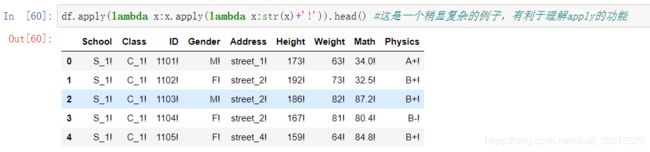
排序:索引排序与值排序
【练习一】 现有一份关于美剧《权力的游戏》剧本的数据集,请解决以下问题:
(a)在所有的数据中,一共出现了多少人物?
(b)以单元格计数(即简单把一个单元格视作一句),谁说了最多的话?
(c)以单词计数,谁说了最多的单词?
pd.read_csv('data/Game_of_Thrones_Script.csv').head()
df=pd.read_csv('data/Game_of_Thrones_Script.csv')
df['Name'].nunique()
df['Name'].value_counts().index[0]df_words = df.assign(Words=df['Sentence'].apply(lambda x:len(x.split()))).sort_values(by='Name')
df_words.head() 
【练习二】现有一份关于科比的投篮数据集,请解决如下问题:
(a)哪种action_type和combined_shot_type的组合是最多的?
(b)在所有被记录的game_id中,遭遇到最多的opponent是一个支?
df = pd.read_csv('data/Kobe_data.csv',index_col='shot_id')
df.head() 
pd.Series(list(zip(df['action_type'],df['combined_shot_type']))).value_counts().index[0]
pd.Series(list(list(zip(*(pd.Series(list(zip(df['game_id'],df['opponent'])))
.unique()).tolist()))[1])).value_counts().index[0]索引
loc(包含右端点), iloc(不包含右端点), []
单行索引:df.loc[2] 查询第二行数据
多行索引:df.loc[1,3]查询1到3行数据;df.loc[8:].head()查询从第8行开始的前5行;df.loc[8::-1].head()倒序查询第8行开始的后5行
单列索引:df.loc[:,'names'].head()查询names列有哪些数据
多列索引:df.loc[:,['names','math']].head()查询names和math列的数据
df.loc[:,'names':'phone'].head()查询names到phone列的数据
联合索引:df.loc[1:15:3,'names':'phone'].head()查询ID在1-15间间隔为3的names到phone列的数据
函数式索引:df.loc[lambda x:x['Gender']=='M'].head() 查询性别为女的前五行数据
布尔索引:df.loc[df['Address'].isin(['street_7','street_4'])].head()查询Address中标签为.._7,.._4的前五行数据
布尔索引的等价表达式:df.loc[[True if i[-1]=='4' or i[-1]=='7' else False for i in df['Address'].values]].head()
布尔索引
df.loc[df['Math']>60,(df[:8]['Address']=='street_6').values].head()
#如果不加values就会索引对齐发生错误,Pandas中的索引对齐是一个重要特征,很多时候非常使用
#但是若不加以留意,就会埋下隐患

isin方法
df[df['Address'].isin(['street_1','street_4'])&df['Physics'].isin(['A','A+'])]等价语句:df[df[['Address','Physics']].isin(['Address':['street_1','street_4'],'Physics':['A','A+']]).all(1)]
区间索引:pd.interval_range(start=0,end=5)Interval详解
利用cut将数值列转为区间元素的分类变量

用from_tuple或from_arrays直接创建元组

使用zip创建元组
L1=list('AABB')
L2=list('abab')
tuples=list(zip(L1,L2))
mul_index=pd.MultiIndex.from_tuples(tuples,names=('Upper','Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)通过Array创建
arrays=[['A','a'],['A','b'],['B','a'],['B','b']]
mul_index=pd.MultiIndex.from_tuples(arrays,names=('Upper','Lower'))
pd.DataFrame({'Score':['perfect','good','fair','bad']},index=mul_index)指定df中的列创建(set_index方法)
df.set_index(['Class','Address'])
一般切片
df_using_mul.index.is_lexsorted() #当索引不排序时,单个索引会报出性能警告
df_using_mul.sort_index().loc['C_2','street_5']#选择loc所示标签内容数据
df_using_mul.sort_index().loc[('C_2','street_6'):('C_3','street_4')]多层切片,loc包含右端点,选取[a:b]区间内的数据
df_using_mul.sort_index().loc[('C_2','street_7'):'C_3'].head()
df_using_mul.sort_index().loc[[('C_2','street_7'),('C_3','street_2')]]选取包含这两个标签的数据
df_using_mul.sort_index().loc[(['C_2','C_3'],['street_4','street_7']),:] 以元组构成列表,表示选出第一层在C_2,C_3且第二层在
‘street_4’和‘street_7’的行
多层索引中的slice对象
L1,L2=['A','B','C'],['a','b','c']
mul_index1=pd.MultiIndex.from_product([L1,L2],names=('Upper','Lower'))
L3,L4=['D','E','F'],['d','e','f']
mul_indeDx2=pd.MultiIndex.from_product([L3,L4],names=('Big','Small'))
df_s=pd.DataFrame(np.random.rand(9,9),index=mul_index,columns=mul_index2)
df_s索引层的交换
df_using_mul.swaplevel(i=1,j=0,axis=0).sort_index().head()#axis=0意为跨行按列方向交换
reorder_levels方法多层交换
df_muls=df.set_index(['School','Class','Address'])
df_muls.reorder_levels([2,0,1],axis=0).sort_index()
索引设定
pd.read_csv('data.csv',index_col=['Address','School'])index_col是read_csv中的参数,而非方法
df.reindex(index=[1,2,3,4])选取这几个id号的行数据
df.reindex(columns=['Height','Gender','Average'])选取index为这几个的列数据
缺失值的填充方法:fill_value和method(bfill/ffill/nearest) method方法必须索引单调
df.reindex(index=[1101,1203,1206,2402],method='bfill')
#bfill表示用所在索引1206的后一个有效行填充,ffill为前一个有效行,nearest是指最近的df.reindex(index=[1101,1203,1206,2402],method='nearest')
#数值上1205比1301更接近1206,因此用前者填充duplicated方法重复元素处理
drop_duplicates去除重复项
sample抽样函数,参数有n样本量,frac抽样比,replace是否放回,axis默认抽样维度为行,weights为样本权重自动归一化,
练习一】 现有一份关于UFO的数据集,请解决下列问题:
(a)在所有被观测时间超过60s的时间中,哪个形状最多?
(b)对经纬度进行划分:-180°至180°以30°为一个划分,-90°至90°以18°为一个划分,请问哪个区域中报告的UFO事件数量最多?
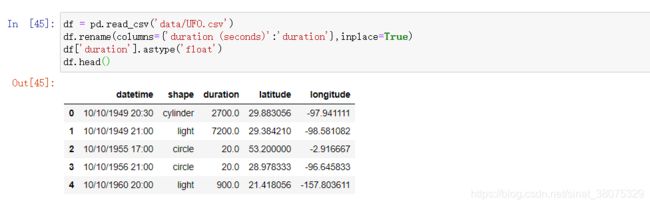 a)df.query('duration>60')['shape'].value_counts().index[0]
a)df.query('duration>60')['shape'].value_counts().index[0]
b)
bins_long=np.linspace(-180,180,13).tolist()
bins_la=np.linspace(-90,90,11).tolist()
cuts_long=pd.cut(df['longitude'],bins=bins_long)
df['cuts_long']=cuts_long
cuts_la=pd.cut(df['latitude'],bins_la)
df['cuts_la']=cuts_la
df.head()
df.set_index(['cuts_long','cuts_la']).index.value_counts().head()分组
SAC过程:split-apply-combine
split指基于某一些规则,将数据拆成若干组,apply是指对每一组独立地使用函数,combine指将每一组的结果组合成某一类数据结构
#按school列分组
grouped_single = df.groupby('School')
grouped_single.get_group('S_1').head()#按某几列分组
grouped_mul=df.groupby(['School','Class'])
gruoped_mul.get_group(('S_2','C_4'))组容量和组数:grouped_single.size() grouped_mul.ngroups()
#组的遍历
for name,group in grouped_single:
print(name)
display(group.head())查看group可调用的方法

对分组对象使用head函数,返回的是每个组的前几行,而不是数据集前几行
grouped_single.head(2)
first显示的是以分组为索引的每组的第一个分组信息
grouped_single.first()
np.random.choice可设置参数实现按比例或随机分组
df.groupby(np.random.choice(['a','b','c','d'],df.shape[0])).get_group('a').head()
#相当于将np.random.choice(['a','b','c'],df.shape[0])当做新的一列进行分组根据奇偶行分组
df.groupby(lambda x:'奇数行' if not df.index.get_loc(x)%2==1 else '偶数行').groups
如果为多层索引,lambda表达式中的输入就是元组

group的[]操作
- 可以用[]选出groupby对象的某个或者某几个列:df.groupby(['Gender','School'])['Math'].mean()>=60
-
用列表可选出多个属性列:df.groupby(['Gender','School'])[['Math','Height']].mean()
-
连续型变量分组:bins=[0,40,60,80,90,100] cuts=pd.cut(df['Math'],bins=bins) df.groupby(cuts)['Math'].count()
聚合,过滤和变换聚合(Aggregation):
group_m=grouped_single['Math']
group_m.std().values/np.sqrt(group_m.count().values)==group_m.sem().values同时使用多个聚合函数:group_m.agg(['sum','mean','std'])
利用元组进行重命名:group_m.agg([('rename_sum','sum'),('rename_mean','mean')])
指定哪些函数作用哪些列:grouped_mul.agg({'math':['mean','max'],'Height':'var'})
变形

pivot可重新组成数据框:df.pivot(index='ID',columns='Gender','values='Height'),可将某一列如:Gender作为新的cols
pivot无法处理重复的行列索引对(pair)
aggfunc:对组内进行聚合统计,可传入各类函数,默认为‘mean’
行、列、值都可为多级
pd.pivot_table(df,index=['School','Class'],columns=['Gender','Address'],values=['Height','Weight'])crosstab交叉表:典型的用途如分组统计
pd.crosstab(index=df['Address'],columns=df['Gender'],normalize='all',margins=True)
其他变形方法:melt将unstacked状态的数据压缩成stacked eg:df_m=df[['ID','Gender','Math']]
Dummy Varible(哑变量) 这里介绍get_dummies函数,功能主要是进行one-hot编码
pd.get_dummies(df_d[['Class','Gender']]).join(df_d['Weight'])
合并
append与assign
利用序列添加行:
1.df_append=df.loc[:3,['Gender','Height']].copy()
2.s=pd.Series({'Gender':'F','Height':188},name='new_row')
df_append.append(s)
利用序列添加列:
s=pd.Series(list('abcd'),index=range(4))
df_append.assign(Letter=s)
可以一次添加多个列:df_append.assign(col1=lambda x:x['Gender']*2,col2=s)
combine和update
“ 可以看出combine方法是按照表的顺序轮流进行逐列循环的,而且自动索引对齐,缺失值为NaN,理解这一点很重要”
根据列均值的大小填充
df1=pd.DataFrame({'A':[1,2],'B':[3,4]})
df2=pd.DataFrame({'A':[8,7],'B':[6,5]})
df1.combine(df2,lambda x,y:x if x.mean()>y.mean() else y)参数overwrite:原来的df值是否被覆盖
参数fill_value:新增df的元素位置填充-1
combine_first方法:用df2填补df1的缺失值
df1=pd.DataFrame({'A':[1,2],'B':[3,4]})
df2=pd.DataFrame({'A':[8,7],'B':[6,5]})
concat方法
#concat方法可以在两个维度上拼接,默认纵向拼接(axis=0),拼接方式默认为外连接
,外连接就是取拼接方向的并集,而inner是取拼接方向的交集
merge与join
merge将两个pandas对象横向合并
【练习一】有2张公司的员工信息表,每个公司共有16名员工,共有五个公司,请解决如下问题:
# (a) 每个公司有多少员工满足如下条件:既出现第一张表,又出现在第二张表。
# (b) 将所有不符合(a)中条件的行筛选出来,合并为一张新表,列名与原表一致。
# (c) 现在需要编制所有80位员工的信息表,对于(b)中的员工要求不变,对于满足(a)条件员工,它们在某个指标的数值,取偏离它所属公司中满足(b)员工的均值数较小的哪一个,例如:P公司在两张表的交集为{p1},并集扣除交集为{p2,p3,p4},那么如果后者集合的工资均值为1万元,且p1在表1的工资为13000元,在表2的工资为9000元,那么应该最后取9000元作为p1的工资,最后对于没有信息的员工,利用缺失值填充。a) L=list(set(df1['Name']).intersection(set(df2['Name'])))
b) df_b1=df1[~df1['Name'].isin(L)]
df_b2=df2[~df2['Name'].isin(L)]
df_b=pd.concat([df_b1,df_b2]).set_index('Name')
c)