智联招聘反爬虫—MmEwMD参数定位
本文仅供学习交流使用,请勿用于商业用途或不正当行为
如果侵犯到贵公司的隐私或权益,请联系我立即删除
1、x-zp-client-id
全局搜索x-zp-client-id很容易定位到是由cookie中来的


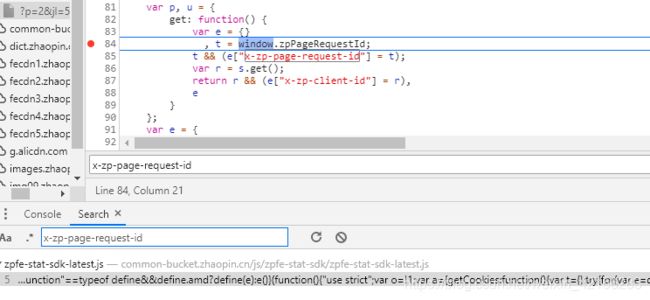
2、x_zp_page_request_id
全局搜索发现从window.zpPageRequestId的值中获取, 该值时访问列表页返回的

3、MmEwMD
我们可以编写一个插件来进行hook,插件内容来自IT猫之家:https://www.itmaohome.com/windows-soft/574.html, 可以在这个页面内直接下载
1)首先创建一个文件夹, 命名为hook, 然后进入
2)创建一个文件, 命名为inject.js, 具体内容为
var code = function(){
var open = window.XMLHttpRequest.prototype.open;
window.XMLHttpRequest.prototype.open = function open(method, url, async){
if (url.indexOf("MmEwMD")>-1){
debugger;
}
return open.apply(this, arguments);
};
}
var script = document.createElement('script');
script.textContent = '(' + code + ')()';
(document.head||document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
3)创建一个文件, 命名为manifest.json, 具体内容为
{
"name": "Injection",
"version": "2.0",
"description": "RequestHeader钩子",
"manifest_version": 2,
"content_scripts": [
{
"matches": [
""
],
"js": [
"inject.js"
],
"all_frames": true,
"permissions": [
"tabs"
],
"run_at": "document_start"
}
]
}
4)然后点击chrome扩展程序→加载已解压的扩展程序→选中hook这个文件夹即可
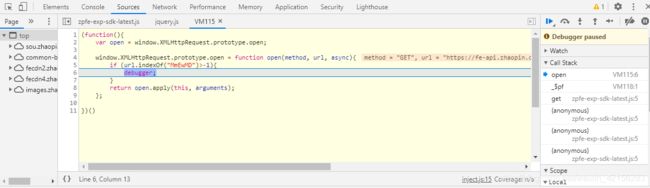
5)打开chrome开发者工具,然后输入列表页的对应的网址,可以发现断下来, 然后就可以查看调用堆栈进行下一步分析了
4、参数获取接口
写了个接口, 可以获取以上三个参数, 仅供测试使用, 切勿高频率请求
http://139.9.119.18:8000/key=e4d1f73c78f19bb6c7db25f6b39dc5c6
# -*- coding:utf-8 -*-
import requests
import json
resp = requests.get('http://139.9.119.18:8000/key=e4d1f73c78f19bb6c7db25f6b39dc5c6')
resp_dict = json.loads(resp.text)
print(resp_dict)
x_zp_page_request_id = resp_dict['x_zp_page_request_id']
x_zp_client_id = resp_dict['x_zp_client_id']
MmEwMD = resp_dict['MmEwMD']
url = f'https://fe-api.zhaopin.com/c/i/sou?x-zp-page-request-id={x_zp_page_request_id}&x-zp-client-id={x_zp_client_id}&MmEwMD={MmEwMD}'
headers = {
'authority': "fe-api.zhaopin.com",
'pragma': "no-cache",
'cache-control': "no-cache,no-cache",
'accept': "application/json, text/plain, */*",
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
'content-type': "application/json;charset=UTF-8",
'origin': "https://sou.zhaopin.com",
'sec-fetch-site': "same-site",
'sec-fetch-mode': "cors",
'sec-fetch-dest': "empty",
'referer': "https://sou.zhaopin.com/?p=2&jl=530&kw=python&kt=3",
'accept-language': "zh-CN,zh;q=0.9,en;q=0.8",
}
payload = {
'start': '90',
'pageSize': '90',
'cityId': '530',
'workExperience': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': 'python',
'kt': '3',
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)