机器学习实战刻意练习 —— Task 01. K-邻近算法
第 1 周任务
分类问题:K-邻近算法
分类问题:决策树
第 2 周任务
分类问题:朴素贝叶斯
分类问题:逻辑回归
第 3 周任务
分类问题:支持向量机
第 4 周任务
分类问题:AdaBoost
第 5 周任务
回归问题:线性回归、岭回归、套索方法、逐步回归等
回归问题:树回归
第 6 周任务
聚类问题:K均值聚类
相关问题:Apriori
第 7 周任务
相关问题:FP-Growth
第 8 周任务
简化数据:PCA主成分分析
简化数据:SVD奇异值分解
文章目录
-
- 1. K-近邻算法
-
- 1.1. K-近邻法简介
- 1.2. 距离度量
- 1.3. Python3代码实现
-
- 1.3.1 准备数据集
- 1.3.2. K-近邻算法
- 1.3.3 整体代码
- 2. 项目案例
-
- 2.1. 优化约会网站的配对效果
-
- 2.1.1. 项目概述
- 2.1.2. 开发流程
-
- 2.1.2.1. 收集数据
- 2.1.2.2. 准备数据
- 2.1.2.3. 分析数据
- 2.1.2.4. 训练算法
- 2.1.2.5. 测试算法
- 2.1.2.6. 使用算法
- 参考资料
1. K-近邻算法
1.1. K-近邻法简介
K-近邻法(K-nearest neighbor, K-NN)是1967年由Cover T和Hart P提出的一种基本分类与回归方法。
它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。
一般来说,我们只选择样本数据集中前K个最相似的数据,这就是K-近邻算法中K的出处,通常K是不大于20的整数。最后,选择K个最相似数据中出现次数最多的分类,作为新数据的分类。
举个简单的例子,我们可以使用k-近邻算法分类一个电影是动作片还是喜剧片。
| 电影名称 | 打斗镜头 | 搞笑镜头 | 电影类型 |
|---|---|---|---|
| 电影1 | 10 | 99 | 喜剧片 |
| 电影2 | 5 | 111 | 喜剧片 |
| 电影3 | 90 | 17 | 动作片 |
| 电影4 | 70 | 30 | 动作片 |
表1.1就是我们已有的数据集合,也就是训练样本集。这个数据集有两个特征,即打斗镜头数和搞笑镜头数。除此之外,我们也知道每个电影的所属类型,即分类标签。用肉眼粗略地观察,搞笑镜头多的,是喜剧片。打斗镜头多的,是动作片。以我们多年的看片经验,这个分类还算合理。如果现在给我一部电影,你告诉我这个电影打斗镜头数和搞笑镜头数。不告诉我这个电影类型,我可以根据你给我的信息进行判断,这个电影是属于喜剧片还是动作片。而K-近邻算法也可以像我们人一样做到这一点,不同的地方在于,我们的经验更丰富,而K-邻近算法是靠已有的数据。比如,你告诉我这个电影打斗镜头数为2,搞笑镜头数为102,我的经验会告诉你这个是喜剧片,k-近邻算法也会告诉你这个是喜剧片。你又告诉我另一个电影打斗镜头数为49,搞笑镜头数为51,我们会意识到,这有可能是个喜剧&动作片,但是K-近邻算法不会告诉你这些,因为在它的眼里,电影类型只有喜剧片和动作片,它会提取样本集中特征最相似数据(最邻近)的分类标签,得到的结果可能是喜剧片,也可能是动作片,但绝不会是喜剧&动作片。当然,这些取决于数据集的大小以及最近邻的判断标准等因素。
1.2. 距离度量
我们已经知道K-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签。那么,如何进行比较呢?比如,我们还是以表1.1为例,怎么判断红色圆点标记的电影所属的类别呢?如图1.1所示。
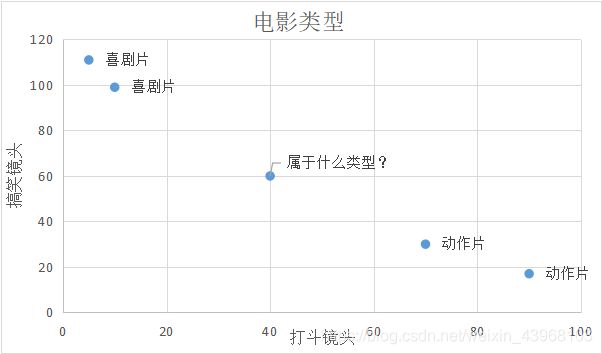
我们可以从散点图大致推断,这个红色圆点标记的电影可能属于动作片,因为距离已知的那两个动作片的圆点更近。k-近邻算法用什么方法进行判断呢?没错,就是距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用我们高中学过的两点距离公式计算距离,如图1.2所示。
![]()
通过计算,我们可以得到如下结果:
- (40,60)到喜剧片(10,99)的距离约为49.20
- (40,60)到喜剧片(5,111)的距离约为61.85
- (40,60)到动作片(90,19)的距离约为64.66
- (40,60)到动作片(70,30)的距离约为42.43
通过计算可知,未知标记的电影到动作片 (70,30)的距离最近,为42.43。如果算法直接根据这个结果,判断该红色圆点标记的电影为动作片,这个算法就是最近邻算法,而非K-近邻算法。那么K-邻近算法是什么呢?K-近邻算法步骤如下:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的K个点;
- 确定前K个点所在类别的出现频率;
- 返回前K个点所出现频率最高的类别作为当前点的预测分类。
比如,现在我这个K值取3,那么在电影例子中,按距离依次排序的三个点分别是动作片(70,30)、喜剧片(10,99)、喜剧片(5,111)。在这三个点中,喜剧片出现的频率为三分之二,动作片出现的频率为三分之一,所以该红色圆点标记的电影为喜剧片。这个判别过程就是K-近邻算法。
1.3. Python3代码实现
我们已经知道了k-近邻算法的原理,那么接下来就是使用Python3实现该算法,依然以电影分类为例。
1.3.1 准备数据集
对于表1.1中的数据,我们可以使用numpy直接创建,代码如下:
import numpy as np
"""
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
"""
def createDataSet():
#四组二维特征
group = np.array([[10,99],[5,111],[90,17],[70,30]])
#四组特征的标签
labels = ['喜剧片','喜剧片','动作片','动作片']
return group, labels
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#打印数据集
print(group)
print(labels)
"""
[[10,99]
[5,111]
[90,17]
[70,30]]
['喜剧片','喜剧片','动作片','动作片']
"""
1.3.2. K-近邻算法
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
import numpy as np
import operator
"""
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
K - KNN算法参数,选择距离最小的K个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, K):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {
}
for i in range(K):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
1.3.3 整体代码
这里预测红色圆点标记的电影(40,60)的类别,K-NN的K值为3。创建KNN_test01.py文件,编写代码如下:
import numpy as np
import operator
"""
Parameters:
无
Returns:
group - 数据集
labels - 分类标签
"""
def createDataSet():
#四组二维特征
group = np.array([[10,99],[5,111],[90,17],[70,30]])
#四组特征的标签
labels = ['喜剧片','喜剧片','动作片','动作片']
return group, labels
"""
Parameters:
inX - 用于分类的数据(测试集)
dataSet - 用于训练的数据(训练集)
labes - 分类标签
K - KNN算法参数,选择距离最小的K个点
Returns:
sortedClassCount[0][0] - 分类结果
"""
def classify0(inX, dataSet, labels, K):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {
}
for i in range(K):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group, labels = createDataSet()
#测试集
test = [40,60]
#KNN分类
test_class = classify0(test, group, labels, 3)
#打印分类结果
print(test_class)
"""
喜剧片
"""
2. 项目案例
2.1. 优化约会网站的配对效果
2.1.1. 项目概述
海伦使用约会网站寻找约会对象。经过一段时间之后,她发现曾交往过三种类型的人:
- 不喜欢的人
- 魅力一般的人
- 极具魅力的人
她希望:
- 不喜欢的人则直接排除掉
- 工作日与魅力一般的人约会
- 周末与极具魅力的人约会
现在她收集到了一些约会网站未曾记录的数据信息,这更有助于匹配对象的归类。
2.1.2. 开发流程
2.1.2.1. 收集数据
此案例书中提供了文本文件。
海伦把这些约会对象的数据存放在文本文件 datingTestSet2.txt 中,总共有 1000 行。海伦约会的对象主要包含以下 3 种特征:
Col1:每年获得的飞行常客里程数Col2:玩视频游戏所耗时间百分比Col3:每周消费的冰淇淋公升数
文本文件数据格式如下:
40920 8.326976 0.953952 3
14488 7.153469 1.673904 2
26052 1.441871 0.805124 1
75136 13.147394 0.428964 1
38344 1.669788 0.134296 1
2.1.2.2. 准备数据
使用 Python 解析文本文件。将文本记录转换为 NumPy 的解析程序如下所示:
import numpy as np
def file2matrix(filename):
"""
Desc:
导入训练数据
parameters:
filename: 数据文件路径
return:
数据矩阵 returnMat 和对应的类别 classLabelVector
"""
fr = open(filename)
# 获得文件中的数据行的行数
lines = fr.readlines()
numberOfLines = len(lines) # type: int
# 生成对应的空矩阵
# 例如:zeros(2,3)就是生成一个 2*3的矩阵,各个位置上全是 0
returnMat = np.zeros((numberOfLines, 3)) # prepare matrix to return
classLabelVector = [] # prepare labels return
index = 0
for line in lines:
# str.strip([chars]) --返回已移除字符串头尾指定字符所生成的新字符串
line = line.strip()
# 以 '\t' 切割字符串
listFromLine = line.split('\t')
# 每列的属性数据
returnMat[index, :] = listFromLine[0:3]
# 每列的类别数据,就是 label 标签数据
classLabelVector.append(int(listFromLine[-1]))
index += 1
# 返回数据矩阵returnMat和对应的类别classLabelVector
return returnMat, classLabelVector
2.1.2.3. 分析数据
使用 Matplotlib 画二维散点图。
import matplotlib.pyplot as plt
if __name__ == '__main__':
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
color = ['r', 'g', 'b']
fig = plt.figure()
ax = fig.add_subplot(311)
for i in range(1, 4):
index = np.where(np.array(datingLabels) == i)
ax.scatter(datingDataMat[index, 0], datingDataMat[index, 1], c=color[i - 1], label=i)
plt.xlabel('Col.0')
plt.ylabel('Col.1')
plt.legend()
bx = fig.add_subplot(312)
for i in range(1, 4):
index = np.where(np.array(datingLabels) == i)
bx.scatter(datingDataMat[index, 0], datingDataMat[index, 2], c=color[i - 1], label=i)
plt.xlabel('Col.0')
plt.ylabel('Col.2')
plt.legend()
cx = fig.add_subplot(313)
for i in range(1, 4):
index = np.where(np.array(datingLabels) == i)
cx.scatter(datingDataMat[index, 1], datingDataMat[index, 2], c=color[i - 1], label=i)
plt.xlabel('Col.1')
plt.ylabel('Col.2')
plt.legend()
plt.show()
图中清晰地标识了三个不同的样本分类区域,具有不同爱好的人其类别区域也不同。

归一化特征值,消除特征之间量级不同导致的影响。
def autoNorm(dataSet):
"""
Desc:
归一化特征值,消除特征之间量级不同导致的影响
parameter:
dataSet: 数据集
return:
归一化后的数据集 normDataSet.ranges和minVals即最小值与范围,并没有用到
归一化公式:
Y = (X-Xmin)/(Xmax-Xmin)
其中的 min 和 max 分别是数据集中的最小特征值和最大特征值。该函数可以自动将数字特征值转化为0到1的区间。
"""
# 计算每种属性的最大值、最小值、范围
minVals = np.min(dataSet, axis=0)
maxVals = np.max(dataSet, axis=0)
# 极差
ranges = maxVals - minVals
m = dataSet.shape[0]
# 生成与最小值之差组成的矩阵
normDataSet = dataSet - np.tile(minVals, (m, 1))
# 将最小值之差除以范围组成矩阵
normDataSet = normDataSet / np.tile(ranges, (m, 1)) # element wise divide
return normDataSet, ranges, minVals
2.1.2.4. 训练算法
此步骤不适用于 k-近邻算法。因为测试数据每一次都要与全部的训练数据进行比较,所以这个过程是没有必要的。
import operator
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
# 距离度量 度量公式为欧氏距离
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
sqDistances = np.sum(sqDiffMat, axis=1)
distances = sqDistances ** 0.5
# 将距离排序:从小到大
sortedDistIndicies = distances.argsort()
# 选取前K个最短距离, 选取这K个中最多的分类类别
classCount = {
}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
2.1.2.5. 测试算法
计算错误率,使用海伦提供的部分数据作为测试样本。如果预测分类与实际类别不同,则标记为一个错误。
def datingClassTest():
"""
Desc:
对约会网站的测试方法
parameters:
none
return:
错误数
"""
# 设置测试数据的的一个比例
hoRatio = 0.1 # 测试范围,一部分测试一部分作为样本
# 从文件中加载数据
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt') # load data setfrom file
# 归一化数据
normMat, ranges, minVals = autoNorm(datingDataMat)
# m 表示数据的行数,即矩阵的第一维
m = normMat.shape[0]
# 设置测试的样本数量, numTestVecs:m表示训练样本的数量
numTestVecs = int(m * hoRatio)
print('numTestVecs=', numTestVecs)
errorCount = 0.0
for i in range(numTestVecs):
# 对数据测试
classifierResult = classify0(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
print("分类器返回结果: %d, 实际结果: %d" % (classifierResult, datingLabels[i]))
if classifierResult != datingLabels[i]:
errorCount += 1.0
print("错误率: %f" % (errorCount / float(numTestVecs)))
print(errorCount)
2.1.2.6. 使用算法
产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否为自己喜欢的类型。
约会网站预测函数如下:
def classifyPerson():
resultList = ['不喜欢的人', '魅力一般的人', '极具魅力的人']
ffMiles = float(input("每年获得的飞行常客里程数?"))
percentTats = float(input("玩视频游戏所耗时间百分比?"))
iceCream = float(input("每周消费的冰淇淋公升数?"))
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = np.array([ffMiles, percentTats, iceCream])
intX = (inArr - minVals) / ranges
classifierResult = classify0(intX, normMat, datingLabels, 3)
print("这个人属于: ", resultList[classifierResult - 1])
实际运行效果如下:
if __name__ == '__main__':
classifyPerson()
'''
每年获得的飞行常客里程数? 10000
玩视频游戏所耗时间百分比? 10
每周消费的冰淇淋公升数? 0.5
这个人属于: 魅力一般的人
'''
未完待续...
参考资料
- https://blog.csdn.net/c406495762/article/details/75172850
- https://blog.csdn.net/LSGO_MYP/article/details/103048796