天池大赛——二手车交易价格预测方案分享(二)
这个比赛是天池的一个数据挖掘入门赛,要求根据提供的数据预测二手车的交易价格,属于回归问题,此篇主要分享一下模型方面的设计思路。
推荐系统最常用的模型是LightGBM和XGBoost等,但在这个比赛中两个模型的表现一般,也可能是我自己没有调好的原因。最终没有选择这两个模型,而是采用了神经网络,并基于pytorch实现。
网络结构
普通的全连接网络在层数比较深的时候会由于梯度衰减的问题难以训练,因此在设计网络结构的时候参考了Resnet的跳层连接思想,即在网络中设计了名为Basicblock的基本模块。
class BasicBlock(nn.Module):
def __init__(self, input_size, hidden_size):
super(BasicBlock, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.layer1 = nn.Sequential(nn.Linear(self.input_size, self.hidden_size),
nn.BatchNorm1d(self.hidden_size),
nn.ReLU())
self.layer2 = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),
nn.BatchNorm1d(self.hidden_size),
nn.ReLU())
self.layer3 = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),
nn.BatchNorm1d(self.hidden_size),
nn.ReLU())
self.layer4 = nn.Sequential(nn.Linear(self.hidden_size, self.input_size),
nn.BatchNorm1d(self.input_size))
self.relu = nn.ReLU()
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = out + x
out = self.relu(out)
return out
另外为了提高网络的拟合能力,参考SeNet的注意力思想,设计了注意力模块:
nn.Sequential(nn.Linear(self.layer_size, self.layer_size//16),
nn.ReLU(),
nn.Linear(self.layer_size//16, self.layer_size),
nn.Sigmoid())
网络整体结构如下所示:
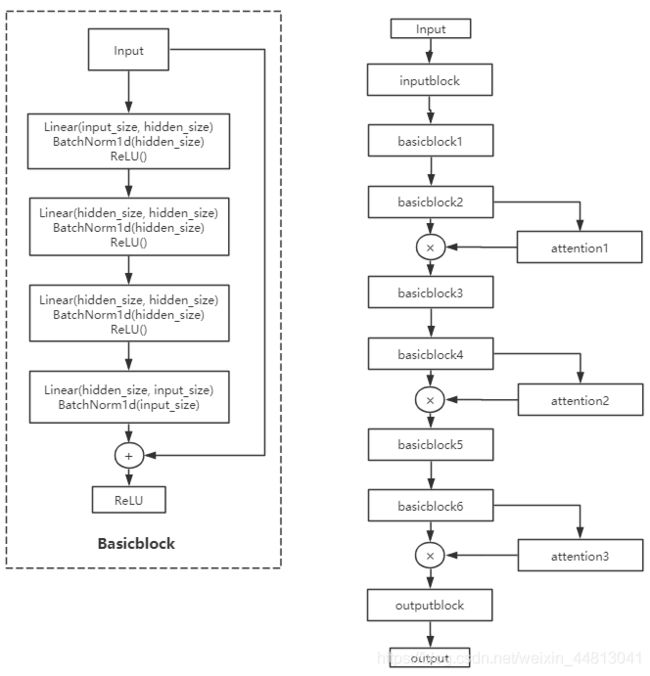
网络结构中的input_block和output_block如下:
self.inputblock = nn.Sequential(nn.Linear(input_size, self.layer_size),
nn.BatchNorm1d(self.layer_size),
nn.ReLU())
self.outputblock = nn.Linear(self.layer_size, 1)
模型的训练
在训练时采用了10折交叉验证,生成十个模型,然后对十个模型在测试集上的预测结果进行平均得到最终预测结果。
优化器采用的是Adam,初始学习率设置为1e-1,学习率衰减采用的是ReduceLROnPlateau:
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=5, verbose=True, cooldown=1, factor=0.7, min_lr=1e-5)
batch_size设置为2048,训练150轮。
模型性能
上述结构的模型,在验证集上的mae基本上能够到420+,不过这时的训练集mae比验证集的略高。在调试过程中发现略微的欠拟合能够实现更低的val_loss。
经过十个模型融合后的预测结果,提交到网站上以后,基本能够达到410+的结果。最终提交的结果,是我通过调整模型结构(如增加深度,增加宽度)之后得到的5个预测结果的平均,最终排行榜上结果是408,排行第15。