tesseract简单介绍和训练
Python--图片文字识别--Tesseract
1、tesseract介绍
Tesseract,一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)库,目前由谷歌赞助,它可以通过训练识别出任何字体,我们可以不断的训练的库,使图像转换文本的能力不断增强;
2、tesseract安装
我们可以百度tesseract,就会有安装包,基本上稍微之前的版本是3.02版本,不过大多的是现在使用的3.05版的,但是最新的是4.00,相对来说,3.05比较稳定,在这里,我安装的是3.05版本的。现在安装教程还蛮多的,大家可自行百度,找一份适合自己情况的教程。推荐 https://www.cnblogs.com/jianqingwang/p/6978724.html记得配置好环境变量啊!
3、tesseract训练
重头戏来了,训练tesseract,什么叫训练tesseract呢?其实就是告诉tesseract正确的识别答案,让它记住。其中,有两个小工具用得到哦——jTessBoxEditor(这个是必不可少的)和TiffToy(这个很方便的)。
首先,下载jTessBoxEditor,地址https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/;解压后得到jTessBoxEditor,由于这是由Java开发的,所以我们应该确保在运行jTessBoxEditor前先安装JRE(Java Runtime Environment,Java运行环境)。
其次,生成目标文件,自己制作或者网上寻找一些图片,文字,字母,数字 ,就是一些验证码图片啦,看自己的需求或者喜好,生成.tif的图集。运气好的呢,就直接打开jTessBoxEditor,Tools->Merge TIFF,将样本文件全部选上,并将合并文件保存为name.tif,然而我运气并不好,总是出现错误,什么Couldn’t Seek的错误啦,什么I/O错误啦,这个时候就用到了TiffToy,把多个图形文件格式合并成一个tif文件,这个下载的话自行百度吧,万一自己运气不差呢。
接下来,生成box文件,这个就在命令行里进行啦
tesseract name.tif name batch.nochop makebox
【语法】:tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
lang为语言名称,fontname为字体名称,num为序号;在tesseract中,一定要注意格式。
打开jTessBoxEditor,BOX Editor -> Open,打开name.tif;
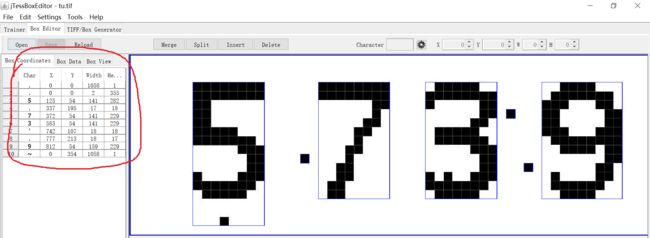
注意红色圈出来的地方,jTessBoxEditor是不能全部完全正确识别出来的,而且还会识别出作为干扰的点,这个时候就需要我们人为地识别啦,在图片上的数字的蓝色框是可以调整的,不准确的要我们人为自行调整。这是个繁琐的事情,要记得不是只识别一张图片呦。
在目标文件夹内生成一个名为font_properties的文本文件,内容为
font 0 0 0 0
【语法】:
fontname为字体名称,italic为斜体,bold为黑体字,fixed为默认字体,serif为衬线字体,fraktur德文黑字体,1和0代表有和无,精细区分时可使用。
- tesseract why4.tif why4 nobatch box.train
然后,生成tr文件 tesseract name.tif name nobatch box.train
聚集tesseract 识别的训练文件 cntraining name.tr
最后一步,合并相关文件,生成字典文件 combine_tessdata name4.
这些都是在命令行里进行的哟
最后,我们就可以测试一下喽 tesseract 1.jpg 1 -l name4