【Faiss】PQ和IVF介绍
Faiss是什么
Faiss是FAIR出品的一个用于向量k-NN搜索的计算库,其作用主要在保证高准确度的前提下大幅提升搜索速度,根据我们的实际测试,基于1600w 512维向量建库,然后在R100@1000 (即召回top 1000个,然后统计包含有多少个实际距离最近的top 100)= 87%的前提下单机15线程可以达到1000的qps,这个性能应该是可以满足大部分的推荐系统召回模块性能需求了。

向量搜索一例:把图片转换成向量然后进行k-NN搜索从而实现相似图片匹配功能
Faiss 的原理
首先来介绍一下Faiss使用时候的数据流:

在使用Faiss的时候首先需要基于原始的向量build一个索引文件,然后再对索引文件进行一个查询操作,在第一次build索引文件的时候,需要经过Train和Add两个过程,后续如果有新的向量需要被添加到索引文件的话还可以有一个Add操作从而实现增量build索引,但是如果增量的量级与原始索引差不多的话,整个向量空间就可能发生了一些变化,这个时候就需要重新build整个索引文件,也就是再用全部的向量来走一遍Train和Add,至于具体是怎么Train和Add的,就关系到Faiss的核心原理了。
Faiss的核心原理其实就两个部分:
- Product Quantizer, 简称PQ.
- Inverted File System, 简称IVF.
Produce Quantizer
Quantizer是通信领域经常出现的一个名词,在这里我觉得PQ有一点CS里面的HashMap的意思,抽象来讲就是把连续的空间离散化,这么做的目的就是为了优化距离计算的速度,在这篇博客里面有具体描述PQ的计算过程。PQ有一个Pre-train的过程,一般分为两步操作,第一步是Clustering,第二部是Assign,这两步合起来就是对应到前文提到Faiss数据流的Train阶段,可以以一个128维的向量库为例:

PQ Clustering && ssign
在做PQ之前,首先需要指定一个参数M,这个M就是指定向量要被切分成多少段,所以M一定要能整除向量的维度,在上图中M=4,所以向量库的每一个向量就被切分成了4段,然后把所有向量的第一段取出来做Clustering得到256个簇心(256是一个作者拍的经验值),再把所有向量的第二段取出来做Clustering得到256个簇心,直至对所有向量的第N段做完Clustering,从而最终得到了256*M个簇心,做完Clustering就开始对所有向量做Assign操作。这里的Assign就是把原来的N维的向量映射到M个数字,以N=128,M=4为例,首先把向量切成四段,然后对于每一段向量,都可以找到对应的最近的簇心 ID,4段向量就对应了4个簇心 ID,一个128维的向量就变成了一个由4个ID组成的向量,这样就可以完成了Assign操作的过程。

PQ Search
完成了PQ的Pre-train,就可以看看如何基于PQ做向量检索了。
同样是以N=128,M=4为例,对于每一个查询向量,以相同的方法把128维分成4段32维向量,然后计算每一段向量与之前预训练好的簇心的距离,得到一个4*256的表,就可以开始计算查询向量与库里面的向量的距离,而PQ优化的点就在这里,在计算查询向量和向量库向量的距离的时候,向量库的向量已经被量化成M个簇心 ID,而查询向量的M段子向量与各自的256个簇心距离已经预计算好了,所以在计算两个向量的时候只用查M次表,比如的库里的某个向量被量化成了[124, 56, 132, 222], 那么首先查表得到查询向量第一段子向量与其ID为124的簇心的距离,然后再查表得到查询向量第二段子向量与其ID为56的簇心的距离。。。最后就可以得到四个距离d1、d2、d3、d4,查询向量跟库里向量的距离d = d1+d2+d3+d4。所以在提出的例子里面,使用PQ只用4×256次128维向量距离计算加上4xN次查表,而最原始的暴力计算则有N次128维向量距离计算,很显然随着向量个数N的增加,后者相较于前者会越来越耗时。
由于上面的量化,粗心一共有256*4个128维的向量(可能有重复)。
接着输入一条查询向量,查询向量与4*256条向量比一下,但是这是隔断开的,依旧分为4个,也就是查询向量与第一段256条向量进行比较,离得近就被量化为谁;接着与第二段的256条向量比较,离得近就被量化为谁。以此类推。
这样新输入的查询向量就被量化成一个1*4的向量。
此时该1*4的向量与库中被量化后的N*4的向量进行比较。比如的库里的某个向量被量化成了[124, 56, 132, 222], 那么首先查表得到查询向量第一段子向量与其ID为124的簇心的距离,然后再查表得到查询向量第二段子向量与其ID为56的簇心的距离。。。最后就可以得到四个距离d1、d2、d3、d4,查询向量跟库里向量的距离d = d1+d2+d3+d4。

PQ和直接暴力计算的比较
Inverted File System
PQ优化了向量距离计算的过程,但是假如库里面的向量特别多,每一个查询向量依旧要进行很多次距离计算,效率依旧还是不够高,所以这时就有了Faiss用到的另外一个关键技术——Inverted File System。
IVF本身的原理比较简单粗糙,其目的是想减少需要计算距离的目标向量的个数,做法就是直接对库里所有向量做KMeans Clustering,假设簇心个数为1024,那么每来一个查询向量,首先计算其与1024个粗聚类簇心的距离,然后选择距离最近的top N个簇,只计算查询向量与这几个簇底下的向量的距离,计算距离的方法就是前面说的PQ,Faiss具体实现有一个小细节就是在计算查询向量和一个簇底下的向量的距离的时候,所有向量都会被转化成与簇心的残差,这应该就是类似于归一化的操作,使得后面用PQ计算距离更准确一点。使用了IVF过后,需要计算距离的向量个数就少了几个数量级,最终向量检索就变成一个很快的操作。
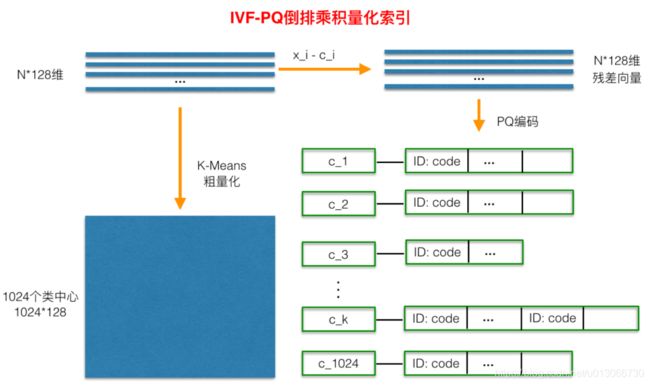
IVF-PQ
Faiss本身的索引格式有很多种,原理大都基于PQ和IVF中的两个或者一个,不同的索引格式对应不同的应用场景,官方给出了一个如何选择索引格式的guideline,在具体应用的时候可以根据自己的数据量级来参照实验。
Tips
关于cosine距离:Faiss中的PQ目前还都是基于L2距离(欧式距离),并不支持cosine距离;
关于源代码阅读:可以从AutoTone.cpp这个文件开始阅读;
关于矩阵计算框架:Faiss外部依赖只有一个矩阵计算框架,这个框架可以用OpenBlas也可以用Intel的MKL,使用MKL编译的话性能会比OpenBlas稳定提升30%,在发布Faiss的时候MKL还是商用License,所以官方并没有直接使用,但是现在MKL已经免费了,所以建议使用MKL;
关于OpenMP:Faiss内部实现使用了大量的OpenMP来提高计算效率,其默认的向量检索也是batch,如果应用场景是单条向量查询,建议把环境变量OMP_NUM_THREADS设为1,避免使用OpenMP带来的多余性能开销,这样可以将单条查询的latency减少至原本的20%;
默认返回的结果是有可能重复的:要想保证结果不重复就在IndexPQ.cpp:927中MinSumK
References
- https://github.com/facebookresearch/faiss
- Product quantization for nearest neighbor search
- https://yongyuan.name/blog/ann-search.html
- http://vividfree.github.io/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/2017/08/05/understanding-product-quantization
- https://zhuanlan.zhihu.com/c_159623040